论文链接:https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
代码链接:https://github.com/openai/gpt-oss
1.介绍
我们推出了 gpt-oss-120b 和 gpt-oss-20b,这两个开放权重推理模型遵循 Apache 2.0 许可证和我们的 gpt-oss 使用政策。这些纯文本模型是根据开源社区的反馈开发的,与我们的 Responses API 兼容,旨在用于具有强大指令遵循能力的 Agent 工作流中,支持网页搜索和 Python 代码执行等工具,并具备推理能力——包括能够针对不需要复杂推理的任务调整推理力度。这些模型可定制,提供完整的思维链 (CoT),并支持结构化输出。
安全是我们处理开源模型的基石。开源模型的风险状况与专有模型不同:一旦发布,执着的攻击者就可以对其进行微调,以绕过安全拒绝机制,或直接进行优化以造成损害,而 OpenAI 无法实施额外的缓解措施或撤销访问权限。
在某些情况下,开发者和企业需要实现额外的安全措施,以便复制通过我们的 API 和产品提供的模型中内置的系统级保护。我们将本文档称为 model card,而不是 system card,因为 gpt-oss 模型将作为各种系统的一部分使用,这些系统由众多利益相关者创建和维护。虽然这些模型默认遵循 OpenAI 的安全策略,但其他利益相关者也会制定并实施他们自己的决策,以确保这些系统的安全。
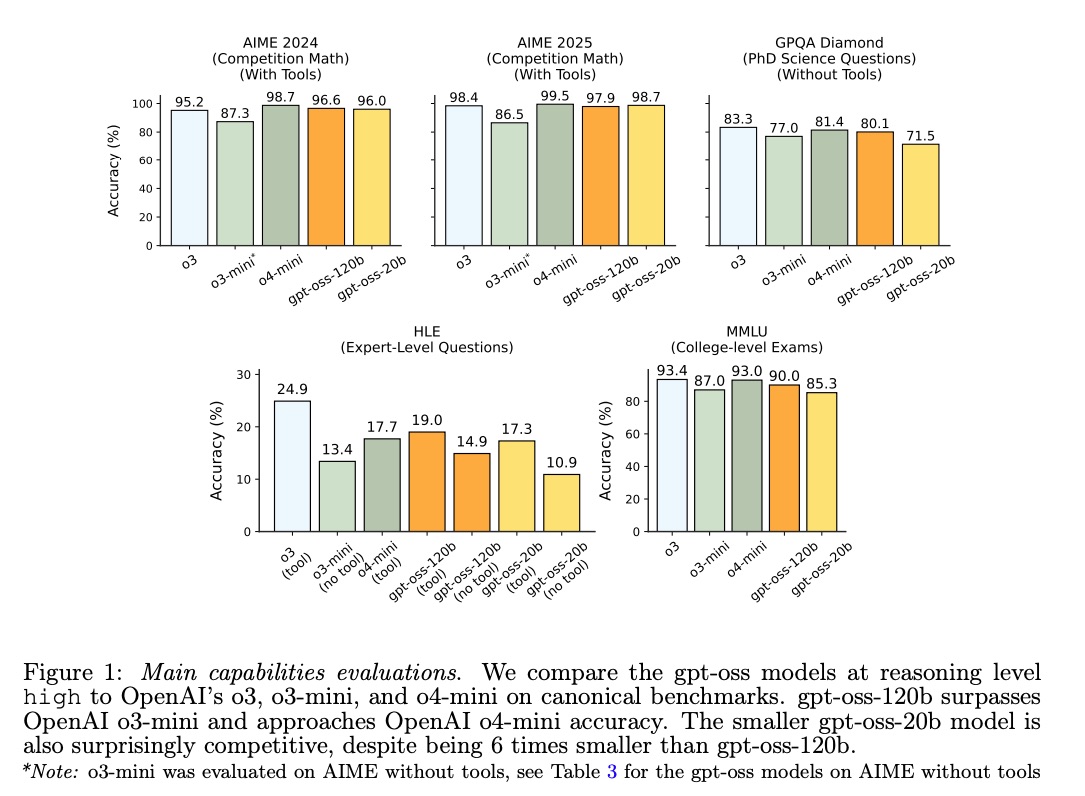
我们对 gpt-oss-120b 进行了可扩展能力评估,并确认默认模型在我们的 Preparedness Framework 的三个跟踪类别(生物和化学能力、网络能力和 AI 自我改进)中均未达到 High capability(在 OpenAI 的《准备框架》中,「High capability(高等级能力)」被定义为:一旦模型具备这种能力,就会“显著放大已知造成严重伤害的风险路径”。如果模型跨过了这条线,在部署前必须先加上足够强的安全防护措施,High capability 只是说明“能力”这一项已经达到可能造成灾难性后果的量级;实际危险大小还取决于有没有恶意者、以及安全机制是否到位。)的指示性阈值。我们还调查了另外两个问题:
- Could adversarial actors fine-tune gpt-oss-120b to reach High capability in the Biological and Chemical or Cyber domains? 通过模拟攻击者的潜在行为,我们针对这两个类别对 gpt-oss-120b 模型进行了对抗性微调。OpenAI 安全咨询小组(“SAG”)审查了此次测试,并得出结论:即使利用 OpenAI 领域领先的训练堆栈进行了稳健的微调,gpt-oss-120b 在生物和化学风险以及网络风险方面仍未达到“高”水平。
- Would releasing gpt-oss-120b significantly advance the frontier of biological capabilities in open foundation models? 我们发现答案是否定的:对于大多数评估,一个或多个现有开源模型的默认性能接近于 gpt-oss-120b 的对抗性微调性能。
作为此次发布的一部分,OpenAI 重申了其致力于推进有益人工智能和提高整个生态系统安全标准的承诺。
2.Model architecture, data, training and evaluations
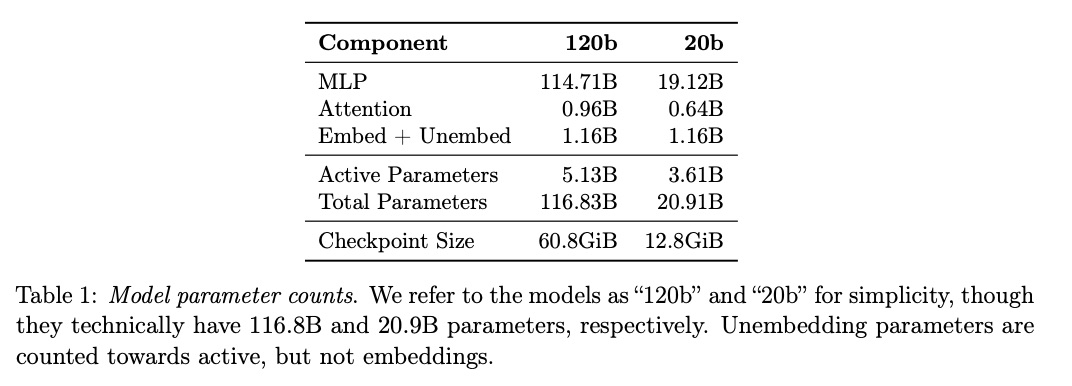
GPT-OSS 模型是基于 GPT-2 和 GPT-3 架构构建的自回归混合专家 (MoE) Transformer。我们发布了两种模型大小:GPT-OSS-120b,包含 36 层(总参数 116.8 B,每个 token 每前向传递 5.1 B 个“活跃”参数);以及 GPT-OSS-20b,包含 24 层(总参数 20.9 B,活跃参数 3.6 B)。表 1 展示了参数数量的完整细分。
2.1 Quantization
我们利用量化来减少模型的内存占用。我们对模型进行了后训练,将 MoE 权重量化为 MXFP4 格式,其中每个参数的权重量化为 4.25 位。MoE 权重占总参数数量的 90% 以上,将这些权重量化为 MXFP4 格式可以使较大的模型适应单个 80GB 的 GPU,而较小的模型则可以在内存低至 16GB 的系统上运行。表 1 列出了模型的 checkpoint 大小。
2.2 Architecture
两个模型的残差流维度均为 2880,对每个注意力模块和 MoE 模块之前的激活值应用均方根归一化。与 GPT-2 类似,我们使用了 Pre-LN 布局。
Mixture-of-Experts:每个 MoE 块由固定数量的专家(gpt-oss120b 为 128 个,gpt-oss-20b 为 32 个)以及一个标准线性路由器投影组成,该投影将残差激活映射到每个专家的分数。对于这两个模型,我们为路由器给出的每个 token 选择排名前 4 位的专家,并使用路由器投影的 softmax 函数对每个专家的输出进行加权,该函数仅作用于选定的专家。MoE 块使用门控的 SwiGLU 激活函数(我们的 SwiGLU 实现非常规,包括 clamp 和残差连接)。
Attention:参照 GPT-3,注意力模块在带状窗口和全密集模式之间交替,滑动窗口宽度为 128 个 token。每层包含 64 个维度为 64 个 query 头,并使用带有 8 个 key value 头的分组查询注意力机制 (GQA)。我们应用旋转位置嵌入,并使用 YaRN 将密集层的上下文长度扩展至 131,072 个 token。每个注意力头在 softmax 的分母中都有一个可学习的 bias,类似于 off-by-one 注意力机制和注意力 sinks,这使得注意力机制可以在需要时不关注任何 token。
2.3 Tokenizer
在所有训练阶段,我们都使用了 o200k_harmony 分词器,该分词器已在 TikToken 库中开源。它是一种字节对编码 (BPE),扩展了用于其他 OpenAI 模型(例如 GPT-4o 和 OpenAI o4-mini)的 o200k 分词器,其中包含明确用于我们如表 18 所示的 Harmony 聊天格式的分词器,总共包含 201,088 个 token。
2.4 Pretraining
Data:我们在一个包含数万亿个 token 的纯文本数据集上训练模型,重点关注 STEM、编码和常识。为了提高模型的安全性,我们在预训练过程中过滤了数据中的有害内容,尤其是与危险生物安全知识相关的内容,并复用了 GPT-4o 中的 CBRN 预训练过滤器。我们模型的知识截止日期为 2024 年 6 月。
Training:gpt-oss 模型在 NVIDIA H100 GPU 上训练,使用 PyTorch 框架和专家优化的 Triton 内核。gpt-oss-120b 的训练运行耗时 210 万 H100 小时,而 gpt-oss-20b 所需的时间几乎减少了十分之一。这两个模型都利用 Flash Attention 算法来降低内存需求并加速训练。
2.5 Post-Training for Reasoning and Tool Use
预训练完成后,我们使用与 OpenAI o3 类似的 CoT 强化学习技术对模型进行后训练。此过程教会模型如何使用 CoT 进行推理和解决问题,并教会模型如何使用工具。由于采用了类似的强化学习技术,这些模型的“个性”与我们在 ChatGPT 等第一方产品中使用的模型类似。我们的训练数据集涵盖了编程、数学、科学等领域的广泛问题。
2.5.1 Harmony Chat Format
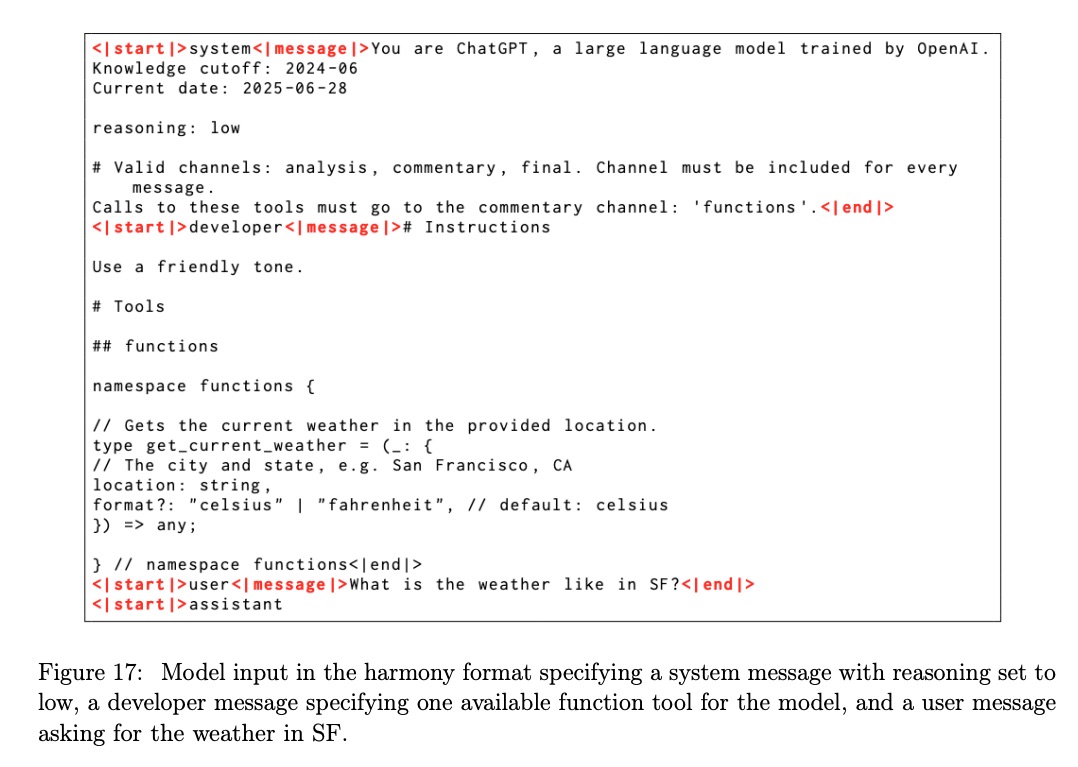

在模型训练中,我们使用一种名为 harmony chat format 的自定义聊天格式。该格式提供特殊 token 来划分消息边界,并使用关键字参数(例如,user 和 assistant)来指示消息的创建者和接收者。我们使用与 OpenAI API 模型中相同的 system 和 developer 消息角色。使用这些角色,模型遵循基于角色的信息层次结构来解决指令冲突:System > Developer > User > Assistant > Tool。
该格式还引入了 channels 来指示每条消息的可见性,例如,CoT token 的 analysis、函数工具调用的 commentary 以及显示给用户的答案的 final。这种格式使 gpt-oss 能够提供高级 Agent 功能,包括在 CoT 内交错工具调用,或提供向用户概述更长行动计划的序言。我们随附的开源实现和指南详细介绍了如何正确使用这种格式——正确部署我们的 gpt-oss 模型以发挥其最佳功能至关重要。例如,在多轮对话中,应删除过去 assistant 轮次的推理痕迹。附录中的表 17 和 18 展示了 Harmony Chat 格式的模型输入和输出示例。
2.5.2 Variable Effort Reasoning Training
我们训练模型以支持三种推理级别:low、medium、high。这些级别可在系统提示中通过插入关键字(例如“Reasoning: low”)进行配置。提高推理级别会导致模型的平均 CoT 长度增加。
2.5.3 Agentic Tool Use
在后训练中,我们还教模型使用不同的 Agent 工具:
- 浏览工具,允许模型调用搜索和打开函数与网络交互。这有助于验证事实,并允许模型获取超出其知识范围的信息。
- 一个 python 工具,允许模型在有状态的 Jupyter 笔记本环境中运行代码。
- 任意 developer 函数,可以在 developer 消息中指定函数模式,类似于 OpenAI API。函数的定义采用我们的 Harmony 格式。示例见表 18。该模型可以交替 CoT、函数调用、函数响应、显示给用户的中间消息以及最终答案。
通过在系统提示中指定,模型已训练支持使用这些工具或不使用它们运行。对于每种工具,我们都提供了支持通用核心功能的基本参考框架。我们的开源实现提供了更多详细信息。
2.6 Evaluation