AUXILIARY-LOSS-FREE LOAD BALANCING STRATEGY FOR MIXTURE-OF-EXPERTS
论文链接:https://arxiv.org/pdf/2408.15664
代码链接:
摘要
对于混合专家(MoE)模型,专家负载不均衡会导致路由崩溃或计算开销增加。现有方法通常采用辅助损失来促进负载均衡,但较大的辅助损失会在训练过程中引入不可忽略的干扰梯度,从而降低模型性能。为了在训练过程中控制负载均衡而不产生不必要的梯度,我们提出了一种名为 Loss-Free Balancing 的策略,其特点是采用无辅助损失的负载均衡方法。具体来说,在做出 个路由决策之前,Loss-Free Balancing 首先会根据每个专家的路由得分应用一个专家级偏差。通过根据每个专家的近期负载动态更新其偏差,Loss-Free Balancing 可以持续地维持专家负载的均衡分布。此外,由于 Loss-Free Balancing 不会产生任何干扰梯度,因此它也提高了混合专家模型训练所能达到的性能上限。我们使用参数高达 3B、训练数据高达 2000B token 的混合专家模型验证了 Loss-Free Balancing 的性能。实验结果表明,与传统的辅助损失控制负载均衡策略相比,Loss-Free Balancing 能够实现更好的性能和更好的负载均衡。
1.介绍
混合专家(MoE)架构已成为大语言模型(LLM)参数扩展时管理计算成本的一种很有前景的解决方案。最近,MoE 在基于 Transformer 的模型中的应用已成功实现了将语言模型扩展到相当大规模的尝试,并取得了显著的性能提升。然而,训练 MoE 模型始终面临负载不均衡的问题,这可能导致路由崩溃或计算开销增加。为了避免路由不均衡,现有方法通常使用辅助损失来促进专家负载的均衡分配。虽然辅助损失可以缓解训练过程中的负载不均衡,但它也会引入与语言建模目标相冲突的不良梯度。这些干扰梯度会降低模型性能,因此现有的多目标估计方法始终需要在负载均衡和模型性能之间权衡取舍。
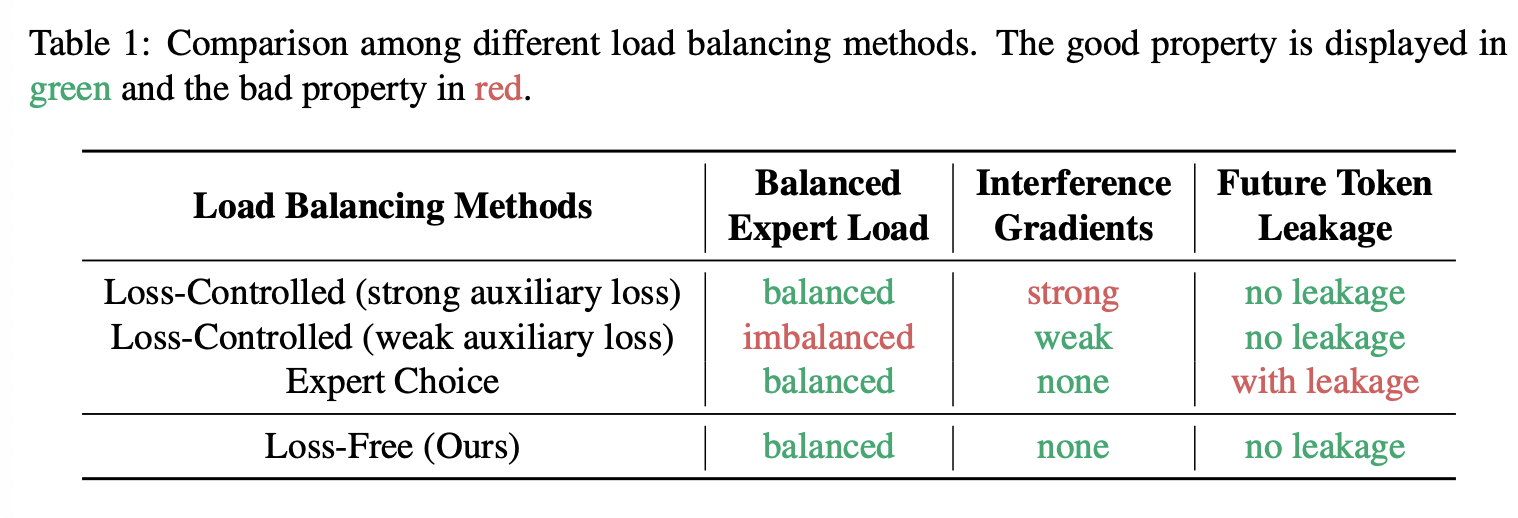
本文提出了一种名为 Loss-Free Balancing 的无损失负载均衡策略,旨在保持对专家负载均衡的控制,同时避免引入干扰梯度。Loss-Free Balancing 采用迭代式 token 路由和偏差更新机制。如图 1 所示,在 MoE 模型做出 top-k 个 token 路由决策之前,Loss-Free Balancing 首先对原始路由分数应用专家偏置,生成偏置门控分数,该分数决定了训练过程中每个 token 的实际路由目标。这些专家偏置会根据近期训练 token 的专家负载情况不断更新,其中高负载专家的偏置值降低,低负载专家的偏置值升高。通过这种动态更新策略,Loss-Free Balancing 确保偏置门控分数能够持续地产生均衡的路由结果。与辅助损失控制的负载均衡策略相比,无损负载均衡不会引入干扰语言建模主要目标的不期望梯度,因此其训练过程更加无噪声且友好。
为了验证 Loss-Free Balancing 算法的性能,我们从零开始训练了参数量分别为 1B 和 3B 的 MoE 语言模型,前者使用 100B token,后者使用 200B token。实验结果表明,Loss-Free Balancing 算法生成的 MoE 模型比传统的辅助损失控制模型具有更低的验证损失。同时,在保持性能优势的同时,Loss-Free Balancing 算法在全局和 batch 层面也实现了显著更优的负载均衡,并且天然兼容专家并行计算,后者通常用于训练超大规模的 MoE 模型。
2.BACKGROUND
2.1 MIXTURE-OF-EXPERTS
目前主流的 MoE 架构用 MoE 层替换了标准 Transformer 中的 MLP 层。在 MoE 层中,采用 Top-K 路由为每个 token 选择专家。令 表示第 个token到具有 个专家的 MoE 层的输入,则输出 计算如下:
其中 为非线性门控函数, 为第 个专家的质心。
2.2 AUXILIARY LOSS FOR LOAD BALANCE
Auxiliary Loss。不受控制的路由策略容易出现负载不均衡,这会带来两个显著的缺点。首先,存在路由崩溃的风险,即模型始终只选择少数专家,从而阻碍其他专家的充分训练。其次,当专家分布在多个设备上时,负载不均衡会加剧计算瓶颈。为了解决这些问题,通常采用辅助损失来控制负载均衡。对于长度为 的序列,辅助损失定义如下:
其中 为专家总数, 为每个 token 选择的专家数量, 为专家 对 token 的路由得分, 表示路由到专家 的 token 比例, 表示专家 的平均门控得分, 是控制辅助损失强度的超参数。
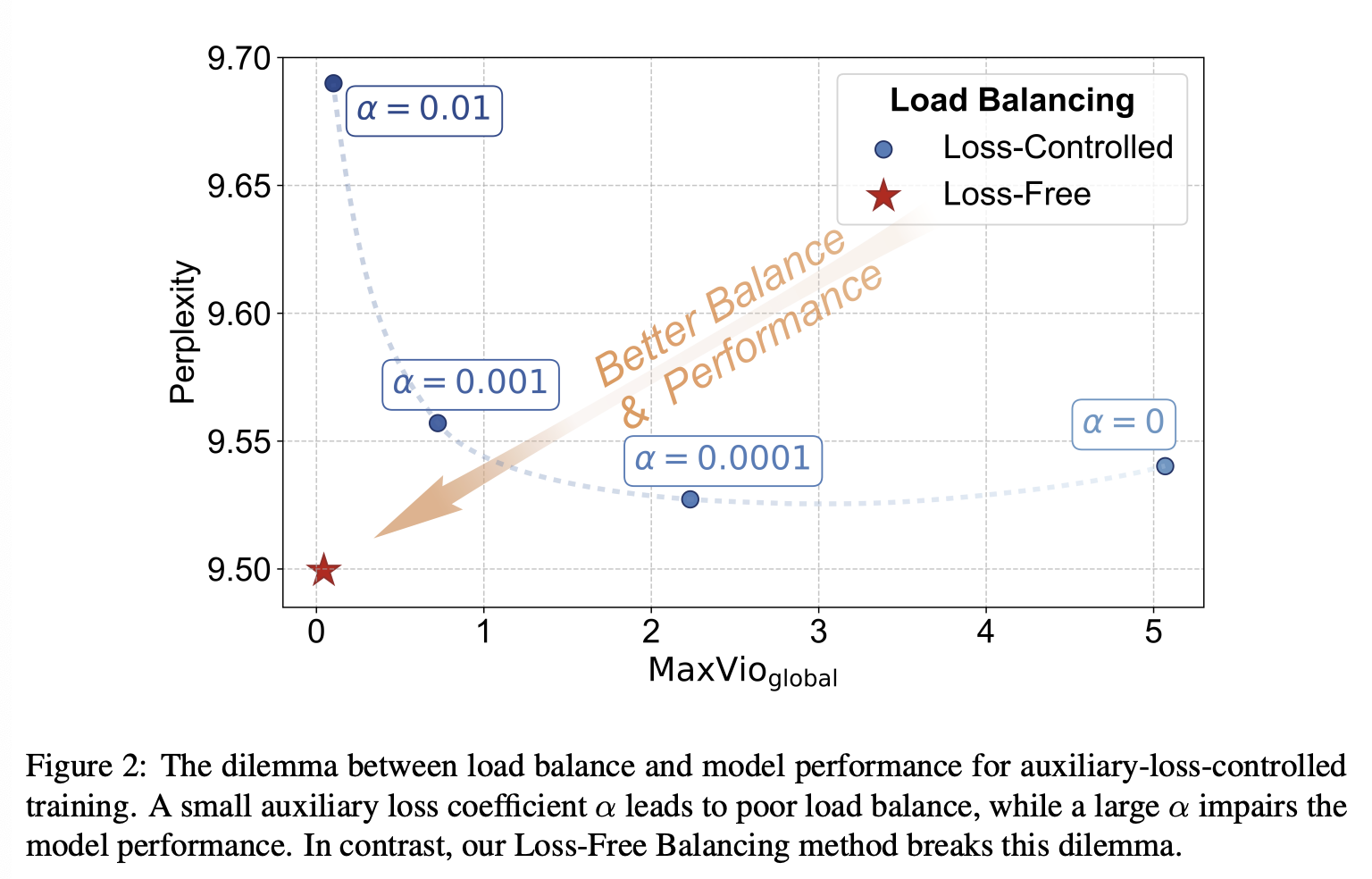
The Dilemma Between Load Balance and Model Performance。上述辅助损失可以促进负载均衡,但作为额外的正则化项,它也会干扰语言模型训练。缺少辅助损失或辅助损失系数 过小会导致负载均衡效果不佳,而 过大则会损害训练,导致模型性能欠佳。为了说明这一困境,我们在图 2 中展示了负载均衡与模型性能之间的关系。我们将 的值分别设置为 1e-2、1e-3、1e-4 和 0,并给出了相应的 值,该值用于衡量负载均衡程度,其计算细节在 §4.1 中描述。如图所示,较小的 值会导致路由崩溃,影响模型效率,并可能导致某些专家未被充分学习或利用;而较大的 值虽然能够控制负载均衡,但会显著降低模型性能。为了解决这一困境,我们提出了 Loss-Free Balancing 方案,该方案直接控制专家负载均衡,且不会引入除语言模型损失梯度之外的其他梯度。
3. AUXILIARY-LOSS-FREE LOAD BALANCING STRATEGY

为了提供一种更好的负载均衡方案,避免直接干扰训练目标的主要梯度,我们提出了 Loss-Free Balancing 方法。该方法根据每个专家的平衡状态直接调整其门控分数。如图 1 所示,我们向每个专家的门控分数 添加一个专家级偏差项 ,并使用这些偏差分数来确定 top-K 个选择:
需要注意的是,专家偏差项 仅用于通过影响 top-K 个专家的选择来调整路由策略。它不会添加到用于在计算 MoE 层最终输出时对所选专家的输出进行加权的 中。
为了获得合适的偏差项,我们根据以下原则迭代调整每个偏差项 :当对应的专家负载较高时降低其偏差项,反之亦然。具体来说,对于每个偏差项 ,我们持续监测其对应专家在上一 batch 中的负载。如果某个专家在上一 batch 中负载较高,则降低其偏差项;否则,增加其偏差项。算法 1 详细描述了我们针对专家差项的更新算法。值得注意的是,我们基于历史负载均衡条件更新偏差项,因为利用当前序列的负载信息会破坏语言建模的因果约束,导致未来 token 信息的泄露。通过动态调整偏差项,我们可以实现良好的专家负载均衡,而不会像辅助损失控制方法那样直接向模型引入噪声梯度。
Comparison with Other Load Balancing Methods。为了展示 Loss-Free Balancing 的理论优势,我们将其与另外两种主流负载均衡方法进行比较,即辅助损失控制方法和专家选择(EC)方法。如第2.2节所述,辅助损失控制方法面临着负载均衡和模型性能之间的两难困境,可能难以找到完美的平衡点。而专家选择方法会破坏语言建模的因果约束,因为每个 token 的目标专家都基于同一序列或 batch 中的后续 token。这将导致未来 token 信息的泄露,从而破坏模型的泛化能力。表 1 总结了不同负载均衡方法的特性。