Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
论文链接:https://arxiv.org/pdf/2101.03961
代码链接:
摘要
在深度学习中,模型通常会对所有输入复用相同的参数。混合专家模型(MoE)打破了这一常规,其为每个输入样本选择不同的参数。其结果是形成了一个稀疏激活模型,尽管参数数量惊人,但计算成本却保持不变。然而,尽管 MoE 取得了一些显著的成功,但其广泛应用仍然受到复杂性、通信成本和训练不稳定性等问题的阻碍。我们通过引入 Switch Transformer 来解决这些问题。我们简化了 MoE 的路由算法,并设计了直观且改进的模型,从而降低了通信和计算成本。我们提出的训练技术缓解了不稳定性,并且首次证明了可以使用较低精度(bfloat16)训练大型稀疏模型。我们基于 T5-Base 和 T5-Large 设计模型,在相同的计算资源下,预训练速度最多可提升7倍。这些改进也延伸到了多语言场景,我们在所有 101 种语言中都测量了相对于 mT5-Base 版本的性能提升。最后,我们通过在“Colossal Clean Crawled Corpus”上预训练高达万亿参数的模型,进一步提升了语言模型的规模,并实现了相对于 T5-XXL 模型 4 倍的速度提升。
1.介绍
大规模训练一直是构建灵活强大的神经语言模型的有效途径。简单的架构——在充足的计算资源、数据集规模和参数数量支持下——能够超越更复杂的算法。Radford et al. (2018); Raffel et al. (2019); Brown et al. (2020) 采用的方法扩展了密集激活 Transformer 模型的规模。虽然这种方法有效,但计算量也极其庞大。受大规模模型成功经验的启发,但为了追求更高的计算效率,我们提出了一种稀疏激活的专家模型:Switch Transformer。在我们的模型中,稀疏性来自于对每个输入样本仅激活神经网络权重的一个子集。
稀疏训练是目前研究和工程领域的热点,但迄今为止,机器学习库和硬件加速器仍然主要针对稠密矩阵乘法。为了获得高效的稀疏算法,我们从专家混合模型(MoE)出发,对其进行简化,以提高训练稳定性和计算效率。MoE 模型在机器翻译领域取得了显著的成功,但由于其复杂性、通信成本和训练不稳定性等问题,其广泛应用受到限制。
我们首先探讨了这些问题,然后超越翻译的范畴,发现这类算法在自然语言处理领域具有广泛的价值。我们在多种自然语言任务以及自然语言处理的三个阶段(预训练、微调和多任务训练)中都验证了其卓越的扩展性。虽然这项工作侧重于扩展性,但我们也表明,Switch Transformer 架构不仅在超级计算机领域表现出色,即使只有少量计算核心也能发挥作用。此外,我们的大型稀疏模型可以蒸馏成小型稠密版本,同时保留 30% 的稀疏模型质量提升。我们的贡献如下:
- Switch Transformer 架构简化并改进了 Mixture of Experts。
- 我们测试了模型的扩展性,并将其与经过深度微调的 T5 模型进行了基准测试。结果表明,在保持每个 token 的 FLOPS 不变的情况下,预训练速度提升了 7 倍以上。此外,我们还证明,即使在计算资源有限的情况下,仅使用两位专家,也能获得同样的性能提升。
- 成功地将稀疏的预训练模型和专门的微调模型蒸馏成小型密集模型。我们在保留大型稀疏 teacher 模型 30% 质量提升的同时,将模型大小减少了高达 99%。
- 改进的预训练和微调技术:(1)选择性精度训练,允许使用较低的 bfloat16 精度进行训练;(2)初始化方案,允许扩展到更多数量的专家;(3)增强的专家正则化,改进稀疏模型微调和多任务训练。
- 对多语言数据进行预训练效益测量,结果发现所有 101 种语言均有普遍改进,其中 91% 的语言比 mT5 基线提高了 4 倍以上。
- 通过高效地结合数据、模型和专家并行计算,神经语言模型的规模得以显著提升,创建出参数量高达万亿的模型。这些模型将经过严格调优的 T5-XXL 基线模型的预训练速度提高了 4 倍。
2.Switch Transformer
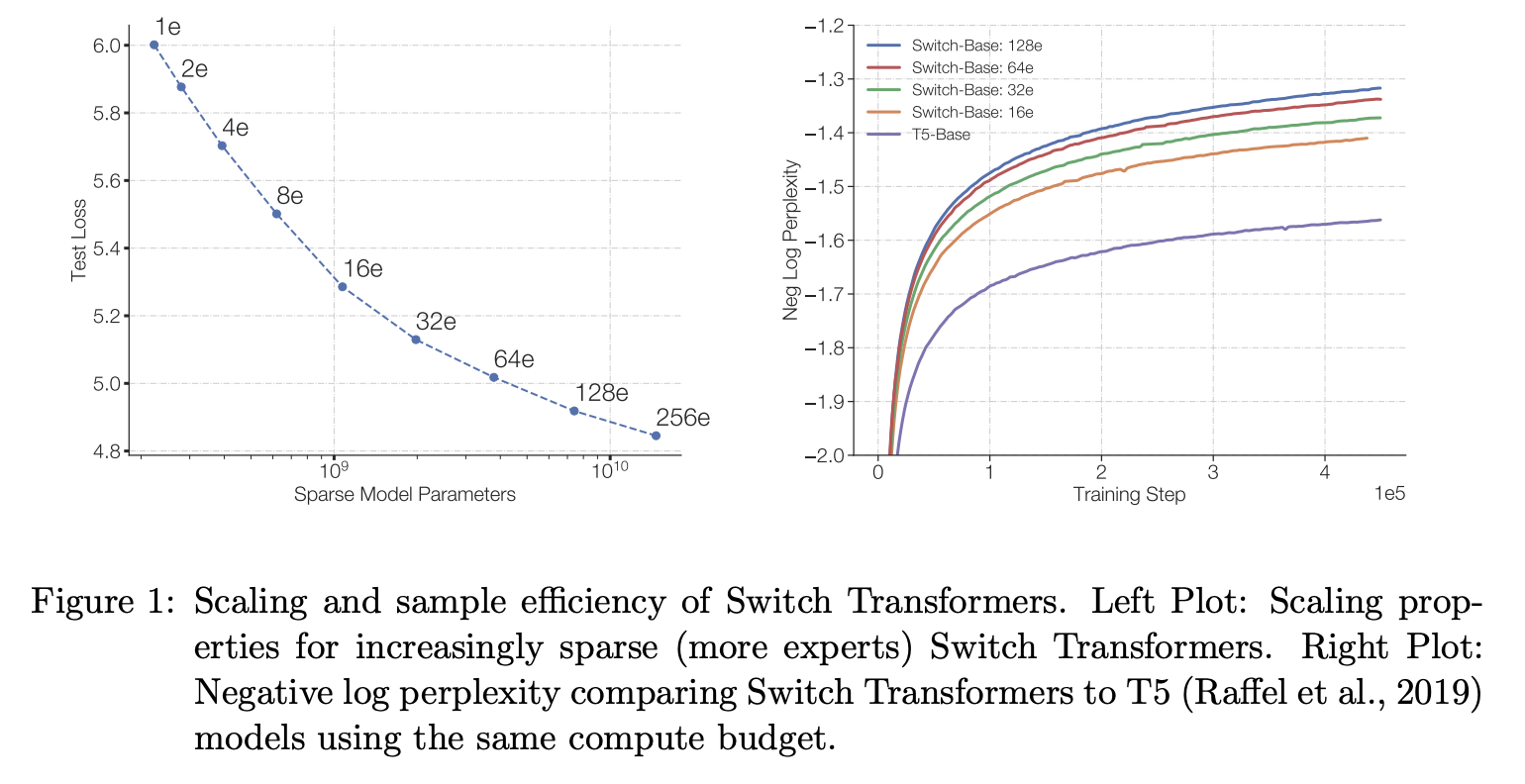
Switch Transformer 的设计指导原则是以简单且计算高效的方式最大化 Transformer 模型的参数数量。Kaplan et al. (2020) 对规模效益进行了详尽的研究,揭示了模型规模、数据集规模和计算预算之间的幂律关系。重要的是,这项工作提倡使用相对较少的数据来训练大型模型,认为这是计算效率最优的方法。
基于这些结果,我们研究了第四个维度:在保持每个样本的浮点运算次数 (FLOPs) 不变的情况下增加参数数量。我们的假设是,参数数量(与总计算量无关)是一个独立的、重要的扩展维度。我们通过设计一个稀疏激活模型来实现这一点,该模型能够高效地利用专为密集矩阵乘法设计的硬件,例如 GPU 和 TPU。本文重点关注 TPU 架构,但这类模型也可以在 GPU 集群上进行类似的训练。在我们的分布式训练设置中,稀疏激活层在不同的设备上分配不同的权重。因此,模型的权重会随着设备数量的增加而增加,同时还能保持每个设备上可控的内存和计算资源占用。
2.1 Simplifying Sparse Routing
Mixture of Expert Routing。Shazeer et al. (2017) 提出了一种自然语言混合专家(MoE)层,该层以 token 表示 作为输入,并将其路由至从 个专家集合 中选择的最佳 top-k 个专家。路由变量 生成 logits ,这些 logits 通过该层可用 个专家的 softmax 分布进行归一化。专家 的门控值由下式给出:
选择 top-k 个门的值来路由 token 。如果 是所选 top-k 个索引的集合,则该层的输出计算是每个专家对 token 的计算结果按门值进行线性加权组合的结果。
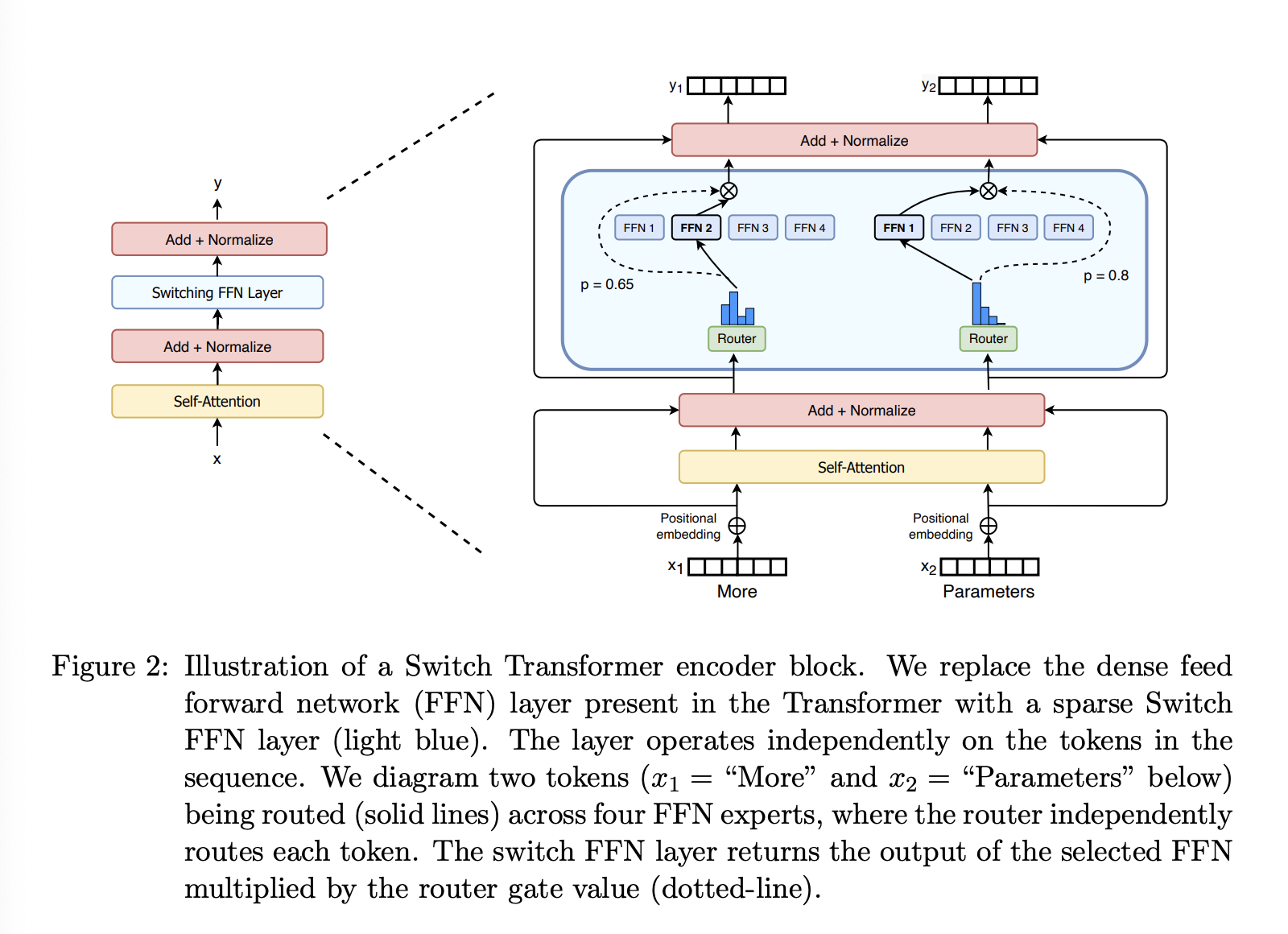
Switch Routing: Rethinking Mixture-of-Experts。Shazeer et al. (2017) 推测,为了使路由函数具有 non-trivial 梯度,路由到 位的专家是必要的。作者直觉地认为,如果没有比较至少两位专家的能力,路由学习将无法进行。Ramachandran and Le (2018) 进一步研究了 top-k 个专家的决策,发现对于具有多个路由层的模型而言,模型较低层中较高的 值至关重要。与这些观点相反,我们采用了一种简化的策略,即仅路由到单个专家。我们证明,这种简化能够保持模型质量,减少路由计算量,并提高性能。这种 的路由策略在后文中被称为 Switch 层。需要注意的是,对于 MoE 路由和 Switch 路由,公式 2 中的门值 都允许 router 具有可微性。
Switch 层的优势体现在三个方面:(1) 由于每个 token 仅路由至单个专家,因此路由器的计算量减少。(2) 由于每个 token 仅路由至单个专家,因此每个专家的 batch size(专家容量)至少可以减半。(3) 路由实现简化,通信成本降低。图 3 展示了不同专家容量因子下的路由示例。
2.2 Efficient Sparse Routing
我们使用 Mesh-Tensorflow (MTF),它是一个与 Tensorflow 语义和 API 类似的库,能够实现高效的分布式数据和模型并行架构。其工作原理是将物理核集合抽象为处理器的逻辑网格。然后,张量和计算可以按命名维度进行分片,从而方便地跨维度划分模型。我们的模型设计以 TPU 为目标,TPU 需要静态声明大小。下面我们将介绍我们的分布式 Switch Transformer 实现。
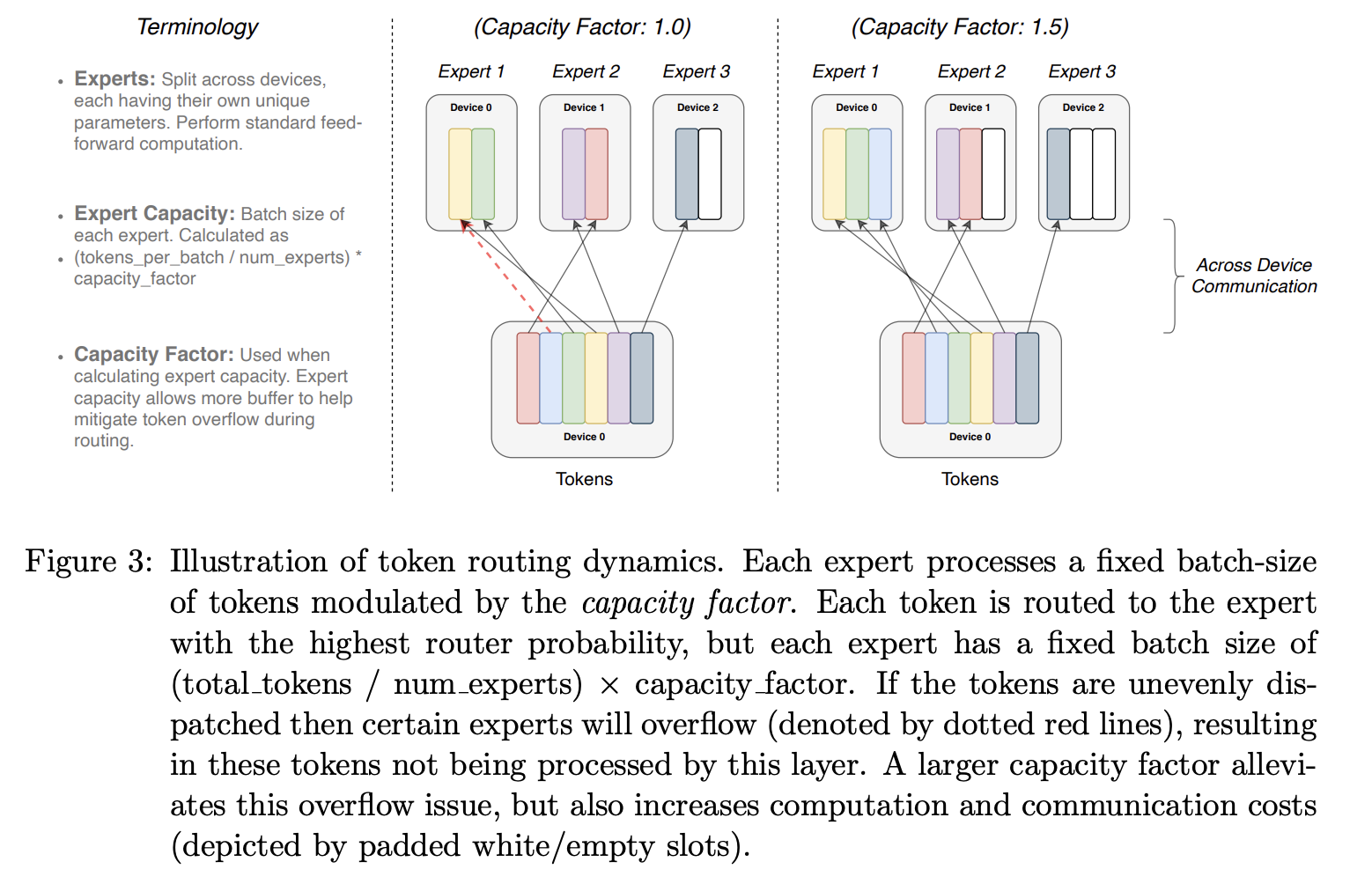
Distributed Switch Implementation。我们所有的张量形状都在编译时静态确定,但由于训练和推理过程中的路由决策,我们的计算是动态的。因此,一个重要的技术考虑因素是如何设置专家容量。专家容量(即每个专家计算的 token 数)的设定方法是:将 batch 中的 token 数平均分配给专家数量,然后乘以一个容量因子。
容量因子大于 1.0 时,会创建额外的缓冲区,以应对专家之间 token 分配不均的情况。如果过多的 token 被路由到某个专家,则会跳过相应的计算(以下简称丢弃 token),并通过残差连接将 token 表示直接传递到下一层。然而,增加专家容量并非没有缺点,因为过高的容量值会导致计算和内存的浪费。图 3 解释了这种权衡。经验表明,确保较低的丢弃 token 率对于稀疏专家模型的扩展性至关重要。在我们的实验中,我们没有发现丢弃 token 的数量(通常 < 1%)与专家数量之间存在任何依赖关系。使用足够高系数的辅助负载均衡损失可以确保良好的负载均衡。表 1 研究了这些设计决策对模型质量和速度的影响。
A Differentiable Load Balancing Loss。为了促进专家间的负载均衡,我们添加了一个辅助损失。与 Shazeer et al. (2018); Lepikhin et al. (2020) 的研究类似,Switch Transformer 简化了 Shazeer et al. (2017) 的原始设计,后者使用了单独的负载均衡损失和重要性加权损失。对于每个 Switch 层,该辅助损失在训练期间会添加到模型的总损失中。给定 个专家(索引为 到 )和一个包含 个 token 的 batch ,辅助损失计算为向量 和 的缩放点积。
其中 是分配给专家 的 token 比例,
其中 是分配给专家 的路由器概率比例,
由于我们希望将一批 token 均匀分配给 位专家,因此我们希望两个向量的值都为 。公式 4 的辅助损失鼓励均匀分配,因为它在均匀分布下最小化。目标函数也可以微分,因为 向量可微,而 向量不可微。最终损失乘以专家数量 ,以保持损失在专家数量变化时保持不变,因为在均匀分配下,。最后,超参数 是这些辅助损失的乘法系数;在本文中,我们使用 ,该值足够大以确保负载均衡,同时又足够小,不会对主要的交叉熵目标造成过大的影响。我们以 10 的幂次方扫描了 的超参数范围,从 到 ,发现 可以快速实现负载均衡,而不会影响训练损失。
2.3 Putting It All Together: The Switch Transformer
我们对 Switch Transformer 的首次测试始于在 “Colossal Clean Crawled Corpus”(C4)上的预训练,该数据集由 (Raffel et al., 2019) 提出。预训练目标采用 mask 语言建模任务,该任务旨在训练模型预测缺失的 token。在我们的预训练设置中,我们丢弃 15% 的 token,然后用单个哨兵 token 替换掩码序列。为了比较我们的模型,我们记录了负对数困惑度。在本文的所有表格中,“↑”表示该指标值越高越好,“↓”则表示值越低越好。表 9 列出了本文研究的所有模型的比较结果。
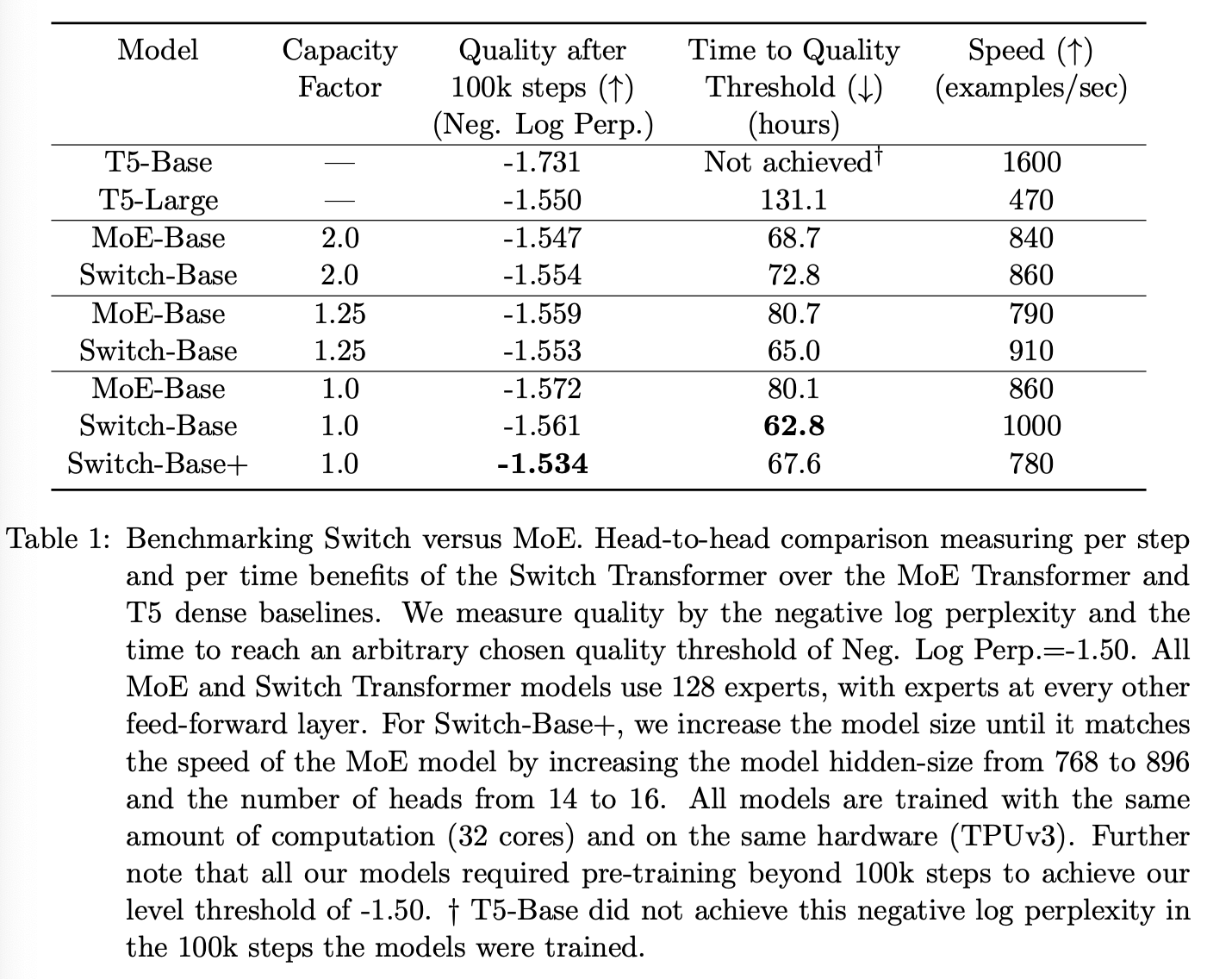
表 1 展示了 Switch Transformer 和 MoE Transformer 的直接对比。我们的 Switch Transformer 模型与“T5-Base”模型在 FLOP 性能上匹配(每个 token 的计算量相同)。MoE Transformer 采用 top-2 路由,由两个专家分别对每个 token 应用一个独立的 FFN,因此其 FLOP 性能更高。所有模型均在相同的硬件上训练相同步数。值得注意的是,在上述实验设置中,MoE 模型的容量因子从 2.0 降至 1.25 时,性能反而下降(从 840 降至 790),这出乎意料。
我们从表 1 中总结出三个关键发现:(1) 在速度和质量方面,Switch Transformer 模型优于精心调优的密集模型和 MoE Transformer 模型。在计算量和运行时间固定的情况下,Switch Transformer 模型能够取得最佳结果。(2) Switch Transformer 模型的计算量小于 MoE Transformer 模型。如果我们将其规模扩大到与 MoE Transformer 模型相同的训练速度,我们发现它在每步的性能上也优于所有 MoE 和密集模型。(3) Switch Transformer 模型在较低的容量因子(1.0 和 1.25)下表现更佳。较小的专家容量表明,在大模型场景中,模型内存非常有限,因此需要尽可能降低容量因子。
2.4 Improved Training and Fine-Tuning Techniques
稀疏专家模型可能会比普通的 Transformer 模型带来更多的训练难题。由于每一层都需要进行硬切换(路由)决策,因此可能导致模型不稳定。此外,低精度格式(例如 bfloat16)会加剧我们路由器中 softmax 计算的问题。本文将描述这些训练难题,以及我们为克服这些难题而采用的方法,以实现稳定且可扩展的训练。
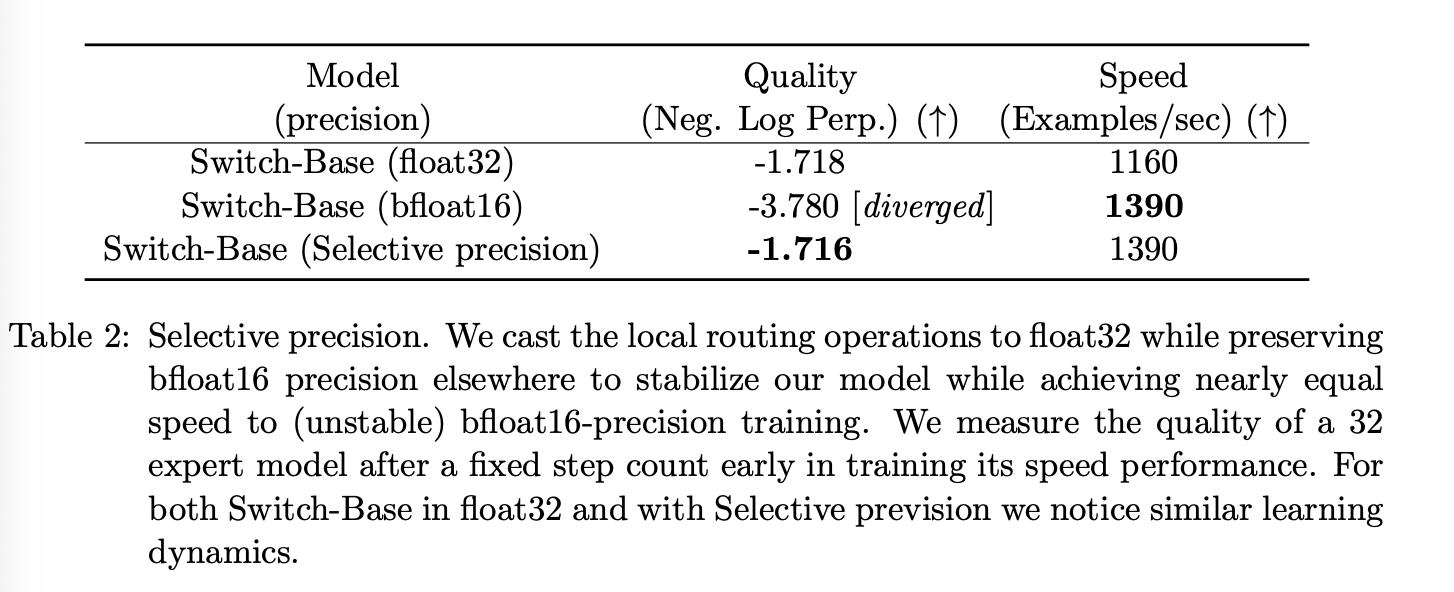
Selective precision with large sparse models。模型的不稳定性阻碍了使用高效的 bfloat16 精度进行训练的能力,因此,Lepikhin et al. (2020) 在其 MoE Transformer 模型中全程使用 float32 精度进行训练。然而,我们证明,通过在模型的局部区域选择性地转换为 float32 精度,可以在不增加 float32 张量通信成本的情况下实现模型稳定性。该技术与现代混合精度训练策略相一致,即模型的某些部分和梯度更新以更高的精度进行。表 2 显示,我们的方法在保持 float32 训练稳定性的同时,实现了与 bfloat16 训练几乎相同的速度。
为了实现这一点,我们将 router 的输入转换为 float32 精度。router 函数以 token 作为输入,并生成用于专家计算的选择和重组的分发张量和组合张量(详情请参阅附录中的代码块 15)。重要的是,float32 精度仅在路由器函数内部使用——即仅用于该设备本地的计算。由于生成的分发张量和组合张量在函数结束时被重新转换为 bfloat16 精度,因此不会通过全设备通信操作广播昂贵的 float32 张量,但我们仍然受益于 float32 更高的稳定性。
Smaller parameter initialization for stability。适当的初始化对于深度学习的成功训练至关重要,我们尤其观察到这一点在 Switch Transformer 中更为明显。我们通过从均值为 、标准差为 的截断正态分布中抽取元素来初始化权重矩阵,其中 是尺度超参数, 是权重张量中的输入单元数(例如,fan-in)。
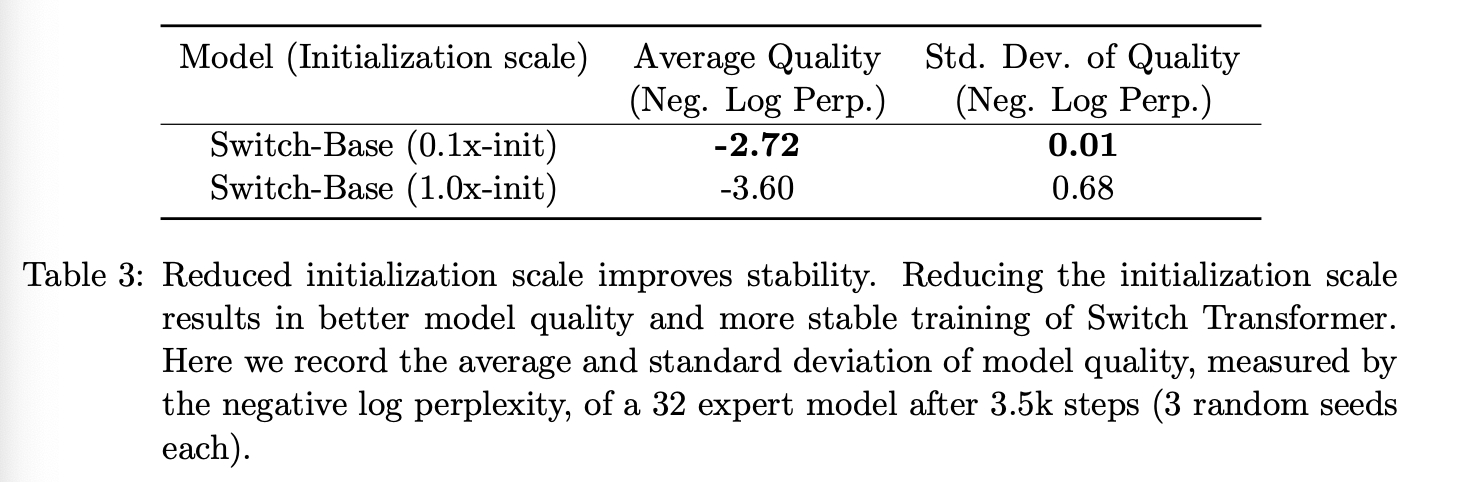
为了进一步解决模型不稳定的问题,我们建议将默认的 Transformer 初始化尺度 降低 10 倍。这既能提高模型质量,又能降低实验中训练不稳定的可能性。表 3 衡量了模型质量的提升以及训练初始化方差的降低。我们发现,以负对数困惑度 (Neg. Log Perp.) 衡量的平均模型质量显著提高,且不同运行之间的方差也大幅降低。此外,这种初始化方案对跨越多个数量级的模型都普遍有效。我们使用相同的方法稳定地训练了从参数量仅为 2.23 亿的基线模型到参数量超过万亿的巨型模型。
Regularizing large sparse models。本文探讨了自然语言处理(NLP)中常见的预训练方法,即先在大语料库上进行预训练,然后在较小的下游任务(例如文本摘要或问答)上进行微调。由于许多微调任务的样本数量非常有限,因此自然会出现过拟合问题。在对标准Transformer 模型进行微调时,Raffel et al. (2019) 在每一层都使用了dropout 来防止过拟合。我们的 Switch Transformer 模型比FLOP匹配的密集基线模型参数数量要多得多,这可能导致在这些较小的下游任务上出现更严重的过拟合。
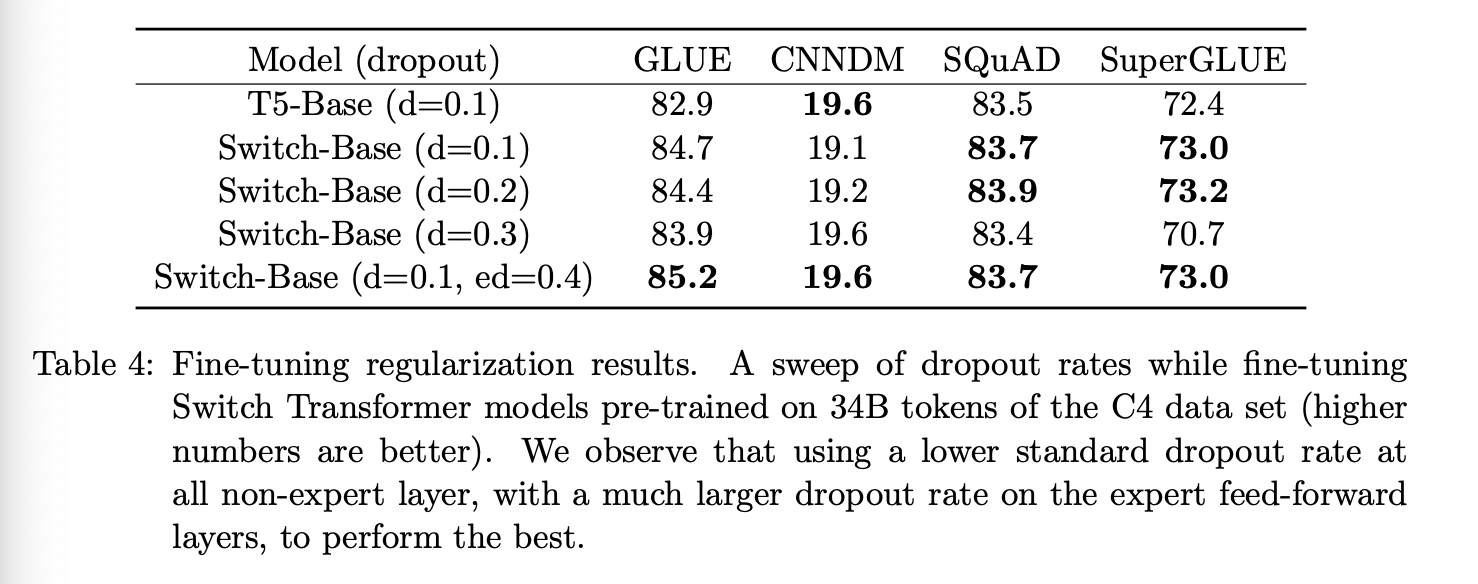
因此,我们提出了一种在微调过程中缓解此问题的简单方法:提高专家层内部的 dropout 率,我们称之为专家 dropout。在微调过程中,我们仅在每个专家层的中间前馈计算阶段大幅提高 dropout 率。表 4 列出了我们专家 dropout 率的结果。我们观察到,简单地提高所有层的dropout 率会导致性能下降。然而,在非专家层设置较小的 dropout 率(0.1),而在专家层设置较大的 dropout 率(0.4),可以提高四个下游较小任务的性能。