论文链接:https://arxiv.org/pdf/2507.08128
代码链接:https://github.com/NVIDIA/audio-flamingo
摘要
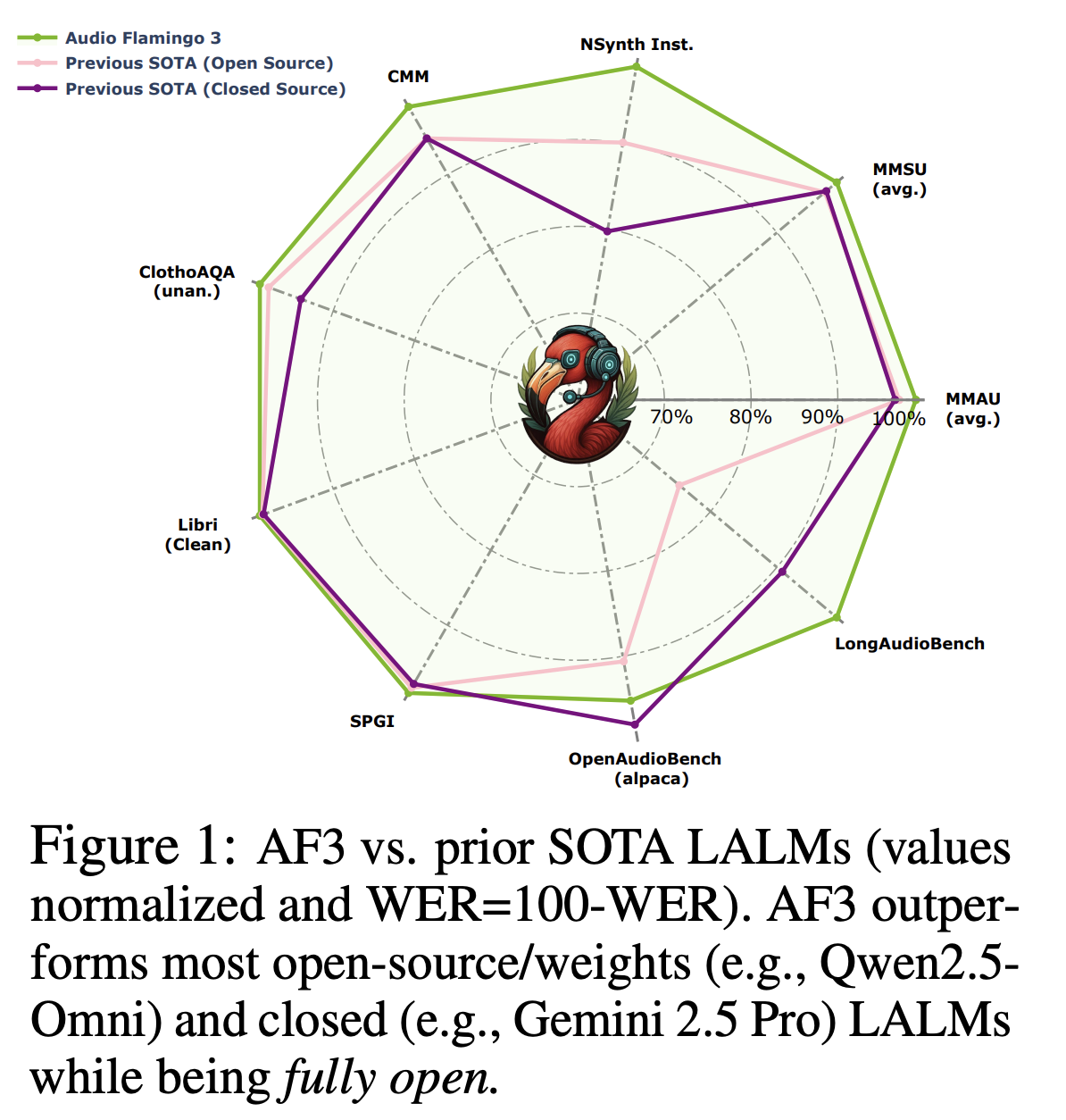
我们推出了 Audio Flamingo 3 (AF3),这是一个完全开放的、最先进的大型音频语言模型,旨在提升语音、声音和音乐的推理和理解能力。AF3 引入了以下功能:(i) AF-Whisper,这是一个统一的音频编码器,采用一种新的策略进行训练,以实现语音、声音和音乐三种模态的联合表征学习;(ii) flexible, on-demand thinking,允许模型在回答问题前进行思路链式推理;(iii) 多轮多音频聊天;(iv) 长达 10 分钟的长音频理解和推理(包括语音);以及 (v) 语音交互。为了实现这些功能,我们提出了几个采用新策略精心设计的大规模训练数据集,包括 AudioSkills-XL、LongAudio-XL、AF-Think 和 AF-Chat,并采用一种新的五阶段课程式训练策略对 AF3 进行训练。 AF3 仅基于开源音频数据进行训练,在超过 20 个(长)音频理解和推理基准上取得了新的 SOTA 结果,超越了在更大数据集上训练的开放权重和闭源模型。
1.介绍
音频(包括语音、声音和音乐)是人类感知和交互的核心。它使我们能够理解周围环境、参与对话、表达情感、解读视频以及欣赏音乐。人工智能系统要想达到通用人工智能 (AGI) 的水平,就必须具备理解和推理各种音频信号的能力。虽然大语言模型 (LLM) 擅长基于语言的推理,但它们的音频理解能力仍然有限——无论是在可访问性还是在功能方面都存在局限性。扩展 LLM 以处理和推理音频对于构建真正具有上下文感知能力的智能 Agent 至关重要。
音频语言模型 (ALM) 将语言模型的功能扩展到听觉领域。早期的研究,例如 CLAP,将音频和文本对齐到共享的嵌入空间中,使其能够执行诸如检索之类的任务。最近,大型 ALM (LALM)(一种增强了音频理解能力的纯解码器语言模型)的出现,释放了强大的功能,包括需要推理和世界知识的开放式音频问答 (AQA)。这些功能进一步赋能了音频分析、对话助手等任务。
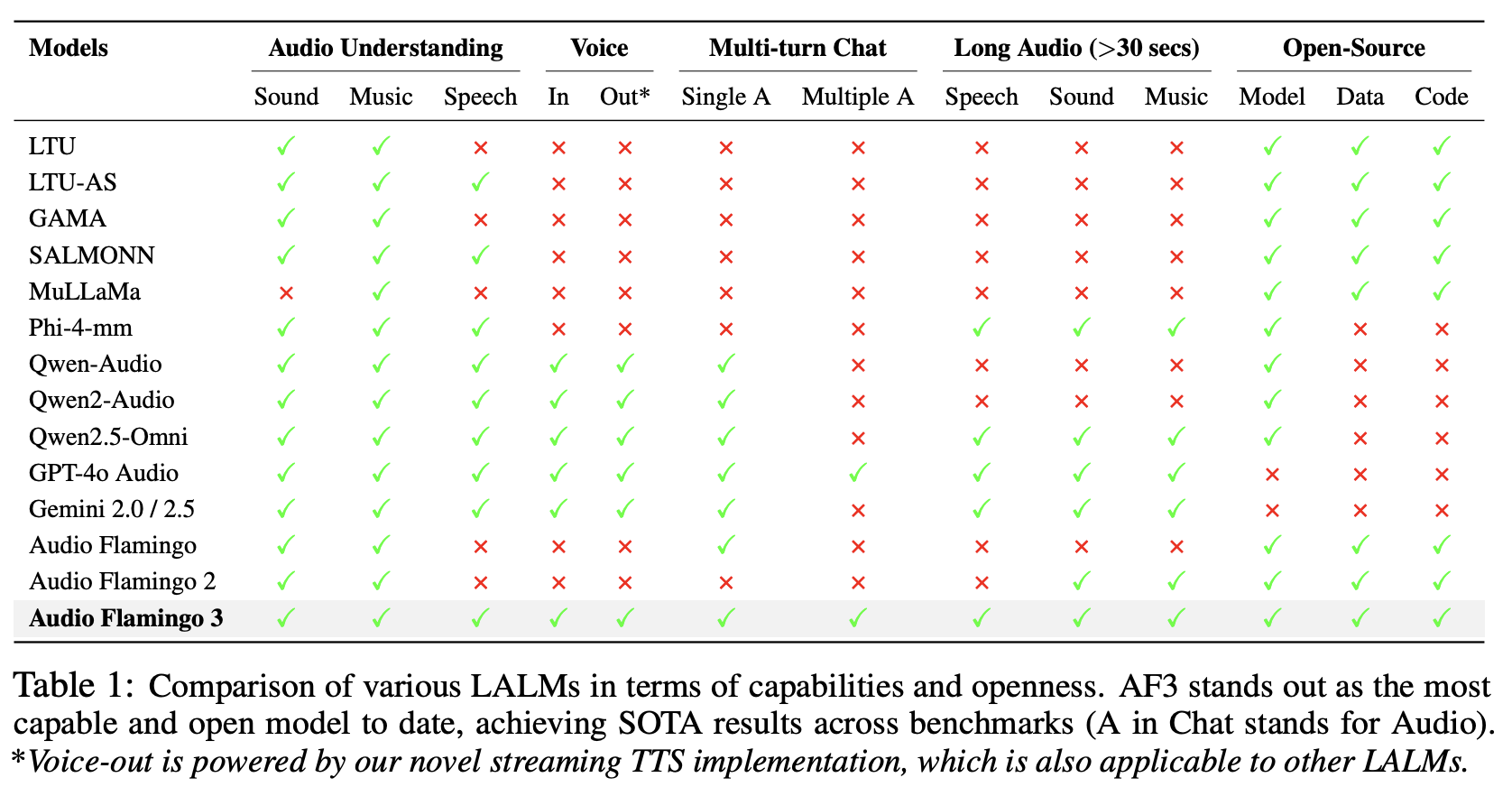
然而,现有模型在通用人工智能 (AGI) 的关键领域仍然存在不足,例如专家级推理、多轮多音频对话以及长音频理解。我们发现了两个核心限制:(i) 大多数 LALMs 主要基于短音频进行训练,用于识别任务,而非需要深思熟虑推理的任务;(ii) 反过来,它们缺乏完成复杂任务所需的技能。此外,大多数支持语音、声音和音乐三种模态的 LALM 都是闭源的:虽然有些模型公开发布了模型权重,但它们提供的关于其数据、代码或配方的信息非常有限,甚至根本没有(更多详情见表 1)。
Main Contributions。为了解决这些问题,我们推出了 Audio Flamingo 3 (AF3),这是一款完全开源的大语音语言模型 (LALM),在 20 多个基准测试中拥有卓越的音频理解和推理性能。此外,AF3 还带来了多项新功能,包括多轮对话、多音频聊天、按需思考、语音对语音交互以及长语境音频推理(最长 10 分钟)。为了实现这些功能,我们提出了三项核心创新:(i) Data:我们专注于大规模收集高质量数据,并提出了 (a) AudioSkills-XL:一个包含 800 万个多样化 AQA 对的大规模数据集;(b) LongAudio-XL:一个包含 125 万个多样化音频问答对的大规模数据集,用于长音频推理; (c) AF-Chat:一个使用新算法整理的多轮多音频聊天数据集,包含 75,000 个实例;(d) AF-Think:一个包含超过 250,000 个 AQA 对的数据集,这些对带有较短的前缀,以鼓励在得出答案之前进行 CoT 类型的推理;(ii) AF-Whisper:我们训练 AF-Whisper,这是一个统一的音频编码器,使用一种新策略在大规模音频-字幕对上进行预训练,能够学习跨语音、声音和音乐的通用表示;(iii) 课程学习:我们采用基于五阶段课程的训练策略训练 AF3,该策略逐步增加上下文长度和任务复杂度。总而言之,我们的主要贡献如下:
- 我们推出了 Audio Flamingo 3 (AF3),这是迄今为止开源的功能最强大的大语音语言模型 (LALM)。AF3 引入的关键功能包括:(i) 长上下文音频问答(扩展至声音之外,如 [40] 所述,并包含语音);以及 (ii) 灵活的按需思考,使模型能够在提示下生成简洁的 CoT 式推理步骤。AF3 在 20 多个音频理解和推理基准测试中取得了最佳性能。
- 我们还推出了 AF3-Chat,这是 AF3 的微调版本,专为多轮、多音频聊天和语音交互而设计。
- 我们在数据管理、音频编码器表示学习和训练策略方面提出了创新。我们完全开放代码、训练方案和 4 个新数据集,以促进该领域的研究。
2.Related Work
Audio Language Models。LLM 的快速发展催生了多模态 LLM (MLLM) 的发展,MLLM 能够理解和推理包括音频在内的多种数据模态。在这一领域,ALM 专门针对语音、声音和音乐等听觉输入进行推理。ALM 通常遵循两种主要的架构范式:(i) 仅编码器的 ALM,它学习音频和文本的联合嵌入空间,从而支持跨模态检索等任务。代表性模型包括 CLAP、Wav2CLIP 和 AudioCLIP。(ii) 编码器/解码器 ALM,也称为 LALM,它使用音频编码器增强的纯解码器的 LLM 。值得注意的例子包括 LTU、LTU-AS、SALMONN、Pengi、Audio Flamingo、Audio Flamingo 2、AudioGPT、GAMA、Qwen-Audio 和 Qwen2-Audio。这些 LALM 在核心音频理解任务上的性能显著提升,例如自动语音识别 (ASR)、音频字幕和声学场景分类。更重要的是,它们实现了诸如开放式音频问答等新功能,而这需要复杂的推理和外部世界知识。
尽管取得了这些进步,但目前的 LALM 在支持各种功能方面仍存在不足,包括多轮对话、多音频聊天、长上下文音频理解等。此外,大多数 LALM 仅限于特定的音频类型,缺乏统一语音、声音和音乐理解的能力。最后,最先进的 LALM 仍然部分开源,只发布模型检查点,而不附带训练代码或数据。这种缺乏透明度的限制了可复现性,并通过掩盖开发过程阻碍了科学进步。
Reasoning and Long-Context Understanding。LLM 领域的最新进展越来越强调长上下文理解。在视觉语言领域,长视频建模取得了长足的进步。在音频领域,AF2 标志着迈向长上下文音频理解的第一步,尽管其研究范围仅限于声音和音乐。
与此同时,人们也致力于通过改进推理数据集、多模态感知方面的进步以及诸如思路链 (CoT) 提示等新兴范式(鼓励模型“先思考后回答”)来增强 LLM 和 MLLM 的推理能力。在开发 AF3 的过程中,我们结合了这些进步——整合了可控推理监督、长上下文训练和模态多样性——使模型具备强大的推理能力和长上下文理解能力,包括语音理解。
3.Methodology
3.1 Audio Flamingo 3 Architecture
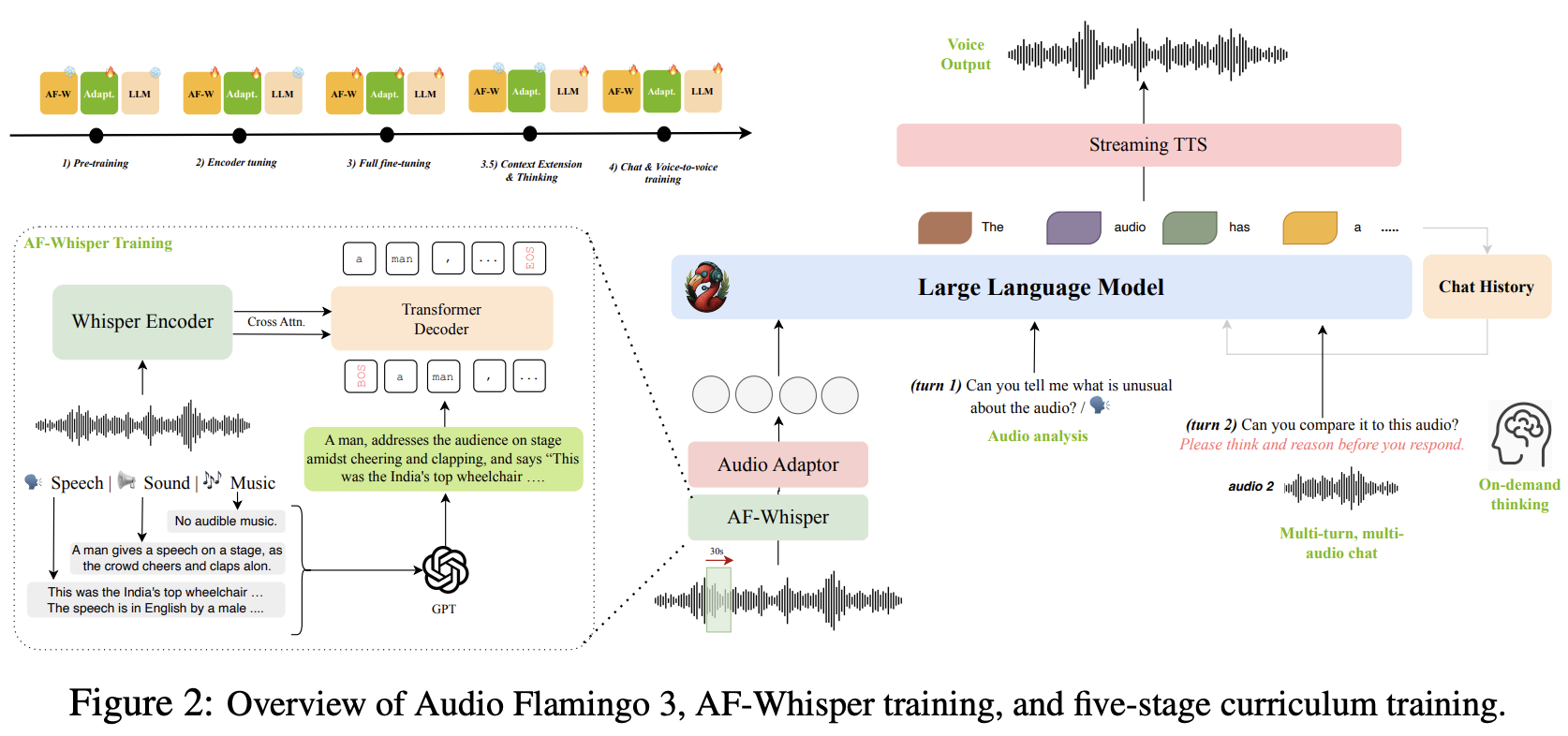
在本节中,我们将讨论我们提出的 Audio Flamingo 3 架构,如图 2 所示。AF3 包含:i) AF-Whisper:一个带有滑动窗口特征提取的音频编码器;ii) 音频投影器;iii) LLM;以及 iv) 流式 TTS。下文将详细介绍每个组件。
AF-Whisper Audio Encoder。音频表示学习领域的先前研究通常将语音、声音和音乐视为独立的模态,而 LALM 通常依赖于针对每种模态的不同编码器。为 LALM 使用单独的编码器会增加模型复杂度,引入帧率不匹配问题,并可能导致训练不稳定。为了解决这个问题,我们提出了 AF-Whisper,这是一个统一的音频编码器,采用简单而有效的表示学习策略进行训练,可以对这三种音频类型进行建模。
如图 2 所示,我们从预训练的 Whisper large-v3 编码器开始,将其连接到标准 Transformer 解码器,并使用音频字幕任务进行训练,目标为下一个 token 预测 (next-token-prediction)。为此,我们为每个音频生成自然语言字幕,描述其语音、声音和音乐内容。首先,我们池化多个数据集,然后提示 GPT-4.1 生成音频字幕。在提示过程中,我们使用每个样本的可用元数据,包括转录、环境声音描述和音乐属性。对于缺少这三种元数据的样本,我们使用 AF2 或 Whisper-Large-v3 ASR 进行合成。所有用于训练的数据集详见 A.2 节。我们选择 Whisper 作为骨干模型,因为它具备语音理解能力,并且拥有密集的高分辨率音频特征,这些特征比 CLAP 等模型的特征更具信息量。我们使用交叉注意力机制将其与 Transformer 解码器连接起来(类似于 RECAP 和 AF2),该解码器有 24 层、8 个注意力头和 1024 个隐藏层大小。
Feature Extraction。给定音频输入 ,我们首先将其重采样为 16kHz 单声道。然后,使用 25ms 的窗口大小和 10ms 的平移大小,将原始波形转换为 128 通道梅尔谱图。该梅尔谱图经 AF-Whisper 处理后,生成隐藏层表征,记为 ,其中 。如图 2 所示,每段音频以 30 秒的不重叠滑动窗口块进行处理,帧数 取决于音频长度和滑动窗口的最大数量(根据训练阶段而变化)。AF-Whisper 以 50Hz 的帧速率生成音频特征,我们进一步应用一个步幅为 2 的池化层,类似于 [19]。 表示隐藏层维度,为 1280。
Audio Adaptor。为了将音频模态与 LLM 的文本嵌入空间对齐,我们引入了音频 Adaptor,记为 。具体来说,来自 AF-Whisper 的编码隐藏表征 会经过这些适配层,从而生成嵌入:。这些生成的嵌入会与文本指令一起作为 LLM 的提示。
Large Language Model (LLM)。我们采用 Qwen-2.5-7B 作为我们的主干,这是一个纯解码器的因果 LLM,具有 7B 个参数、36 个隐藏层和 16 个注意力头。
Streaming TTS。为了实现语音交互,我们采用了一个 TTS 模块来生成流式语音,并支持流式输入和输出。我们的 TTS 模块采用纯解码器的 Transformer 架构:它根据来自 LLM 的输入子词文本 token 和先前生成的音频 token 的历史记录,预测后续的音频 token。类似的流式 TTS 技术已在 LLM 中得到探索(用于 LLM 输出的语音输出),但尚未在 LALM(我们将其定义为旨在感知和推理不同音频输入的模型)的背景下进行探索。由于这并非我们工作的核心创新点,我们将在附录一中提供更多细节,包括训练和架构。
4.Audio Flamingo 3 Training Data
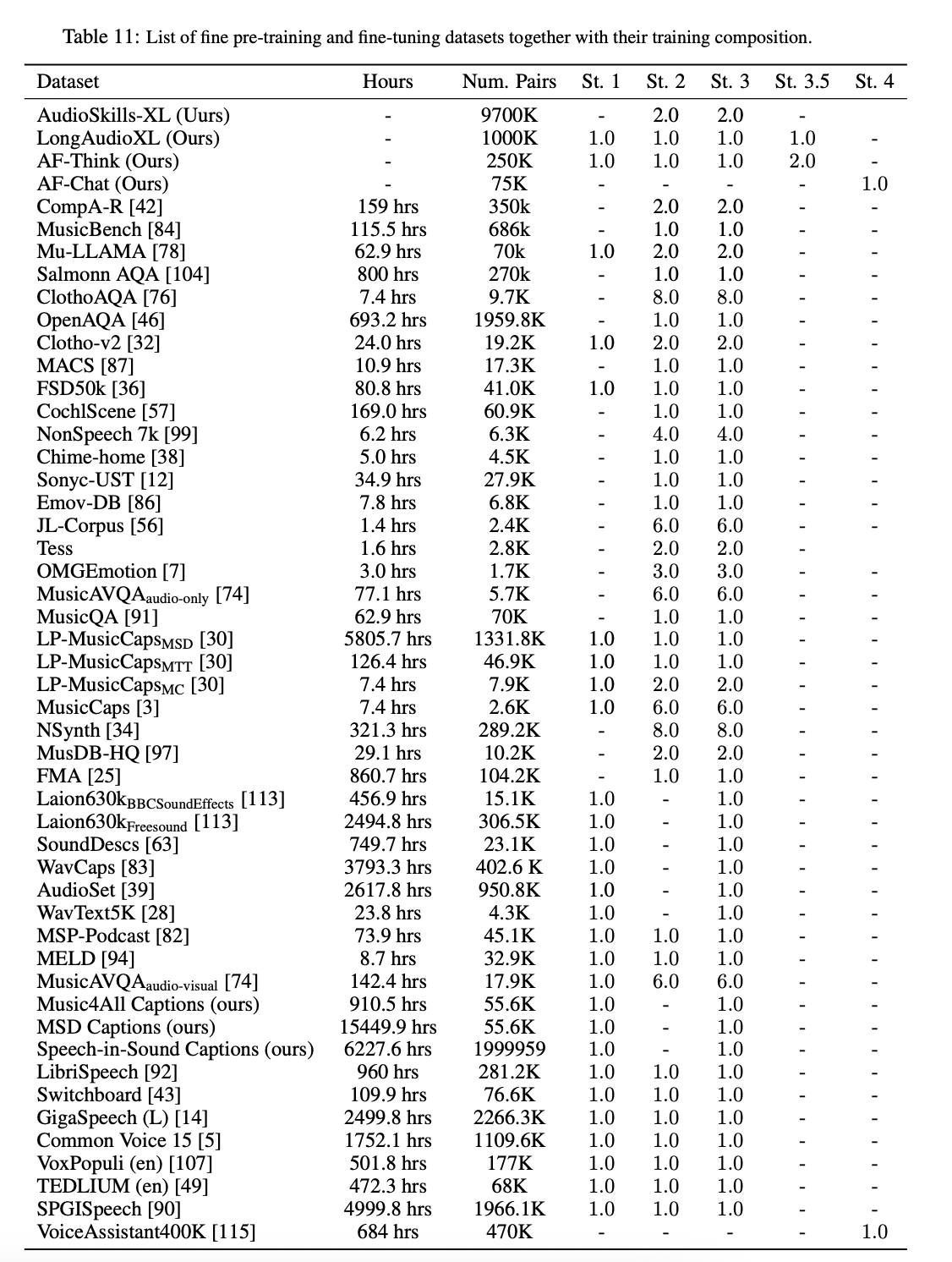
表 11 展示了用于训练 AF3 的所有数据集的详细统计数据。AF3 共有 5 个训练阶段,每个阶段都采用独立的数据集组合,并赋予其独特的权重(即该阶段对该数据集的遍历次数)。对于第 1 阶段和第 2 阶段,我们使用已转换为 QA 格式的开源、专注于识别的基础数据集。在接下来的小节中,我们将介绍第 3、3.5 和 4 阶段中使用的四个新的且独立的数据集,每个数据集都配有定制的数据管理策略,这些数据集构成了本研究的核心贡献。
4.1 AudioSkills-XL: Expanding AudioSkills with Reasoning-Focused QAs
基于基础基准测试(例如,自动语音识别 (ASR)、声学事件分类)的音频问答对不足以训练专家级推理模型。因此,在第三阶段的微调中,我们优先考虑开发推理和解决问题的能力,方法是收集大规模、高质量的音频问答数据。受 AF2 的启发,我们将此阶段限制为短音频片段(≤30 秒),并将长音频推理推迟到后续阶段。我们在 AudioSkills 数据集中新增了 450 万个音频问答对(主要基于多项选择题 (MCQ)),从而创建了包含 800 万个音频问答对的高质量语料库 AudioSkills-XL,并采用了以下两种策略:
(1)我们扩展了现有推理技能的覆盖范围,并使用其他音频源引入了新的技能,从而使数据集增加了 350 万个 QA 对:(a)对于声音,我们整合了来自 YouTube8M 和合成源的数据。(b)对于音乐,我们包括 Music4All 和 Million Song Dataset。对于 YouTube8M,我们改编了来自 AudioSetCaps 的字幕,并使用 GPT-4.1 和来自 AF2 的一般推理提示生成 QA。此外,我们引入了新的推理技能并设计了相应的提示来支持它们。对于音乐,我们为新技能生成数据(因为 AudioSkills 更侧重于声音;详情见表 6)并且超越了字幕——我们利用歌曲名称、艺术家姓名、专辑名称等元数据(完整列表见图 4)来生成更复杂、更注重推理的 QA。我们还使用这些元数据为第一阶段和第二阶段的预训练生成丰富的音乐字幕(见图 4),展示了基于文本的知识如何增强音频理解,尤其是在音乐等知识驱动的领域。这种方法可以看作是合成知识生成,我们利用基于文本的知识来丰富音频理解,并使模型能够从外部未标记的音频中获取特定领域的知识。我们的分析表明,像 GPT-4.1 这样的 LLM 拥有丰富的音乐世界知识,并且元数据可以显著提高 QA 质量。
(2)我们用 YouTube8M、LibriSpeech(朗读语音)、GigaSpeech(对话)和 VoxCeleb2(访谈)等数据集中的 100 万条语音问答样本扩充了 AudioSkills。从 YouTube8M 中,我们引入了一项新任务:Speech-in-Sound 问答,其中模型必须推理语音内容和环境声音才能理解复杂的听觉场景。为了创建这些问答,我们创建了 Speech-in-Sound-Caps,这是一个包含约 200 万条来自 YouTube8M 的语音感知听觉场景字幕的新数据集。为了整理这个数据集,我们首先过滤数据集中的英语语音(使用 AF2),并使用 Whisper-Large-v3 转录口述内容。然后,我们生成两种类型的描述:一种捕捉声音事件,另一种总结语音特征,例如声调、情感和音高(均使用 AF2 和自定义提示;参见附录 26)。最后,我们提示 GPT-4.1 合成语音感知场景字幕。这些字幕通过提供更全面的音频表示,显著提升了最终音频字幕的质量(与仅使用声音信息相比)。对于 LibriSpeech 和 GigaSpeech,我们将较短的片段连接成 15-30 秒的片段,并通过提示 LLM 筛选出信息密集的片段。为了超越大多数当前数据集中常见的基本口语内容理解,我们设计了五种不同类型的语音问答系统,它们需要不同的推理技能(下一节将对此进行解释)。
4.2 LongAudio-XL: Expanding LongAudio with Long Speech QA
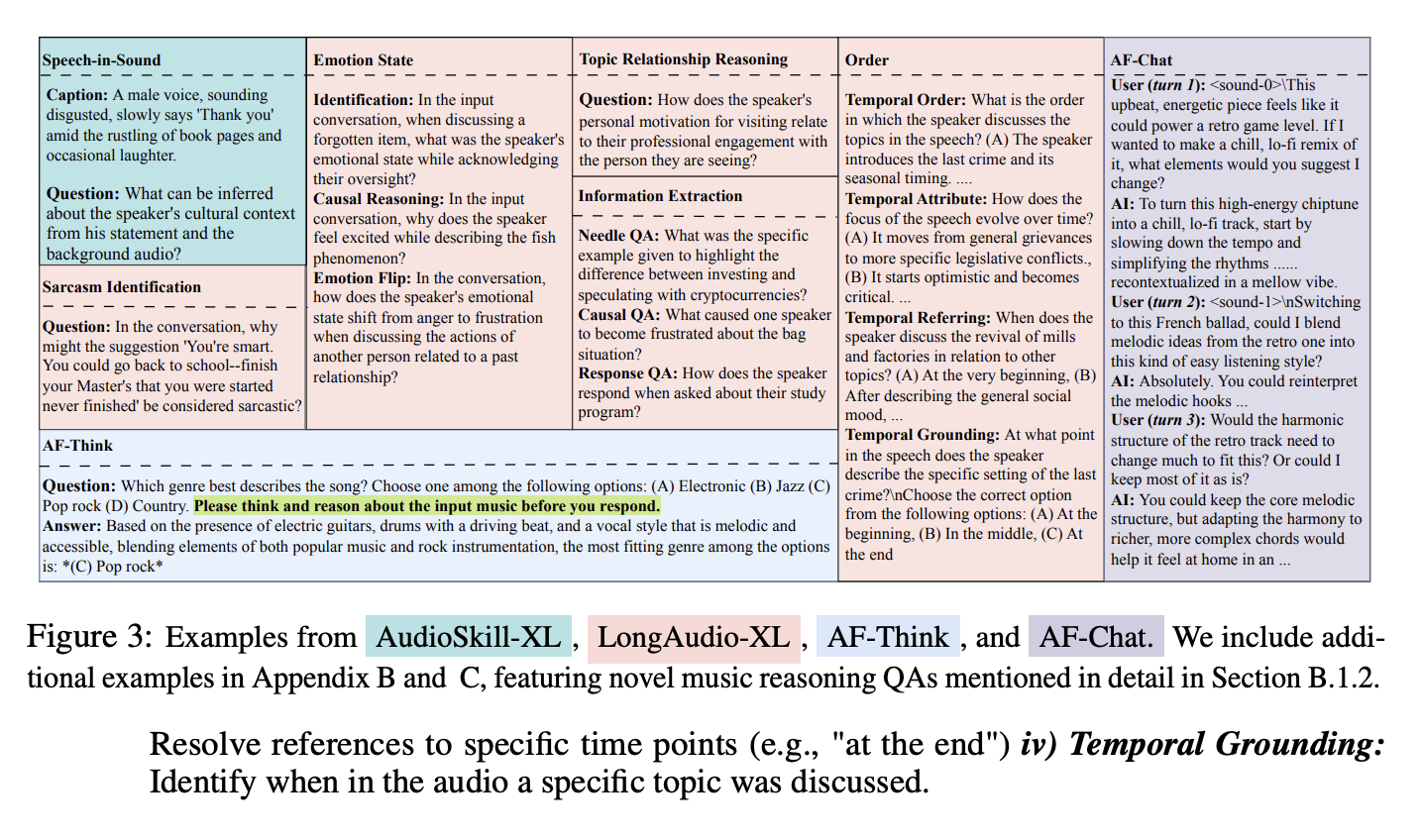
据我们所知,尽管长语音问答(即音频≥30秒)与长篇对话理解、会议摘要和叙事理解等实际应用息息相关,但此前的研究尚未对其进行探索。为了弥补这一不足,我们扩展了现有的 LongAudio 数据集(专注于声音和音乐),纳入了超过 100 万个以推理为重点的长篇语音问答样本(30秒至10分钟)。我们从各种来源收集音频,包括:单人语音:LibriSpeech(有声读物)、EuroParl、VoxPopuli(议会辩论);多人对话:Spotify Podcasts、Switchboard、Fisher(二元通话)、MELD、DailyTalk、MMDialog(自然对话)。我们按时间顺序合并连续的短片段,以构建更长、更连贯的音频。我们构建了涵盖各种技能的 QA 数据,如图 3 所示:
- Sarcasm Identification:通过分析内容、语气和情感线索来推断讽刺。
- Emotional State Reasoning:i) 识别:确定说话者在特定话语中的情绪。ii) 因果推理:利用对话背景识别说话者情绪状态背后的原因。iii) 情绪转变:解释谈话过程中说话者情绪状态的变化。
- Topic Relationship Reasoning:了解两个想法或主题在整体论述中是如何关联的。
- Information Extraction (IE):i) Needle QA:针对特定话语或演讲部分进行有针对性的 QA(例如,实体或事实提取、一般知识联系)。ii) Causal QA:确定上下文中特定话语的原因。iii) Response QA:提取一个说话者如何回应另一个说话者的陈述。iv) Topic QA:确定演讲或对话的主要主题。
- Summarization:生成演讲内容的简明摘要。
- Order:i) 时间顺序:理解演讲中主题的顺序;ii) 时间属性:理解主题如何随时间变化;iii) 时间引用:解析对特定时间点的引用(例如,“在最后”)iv) 时间基础:确定音频中何时讨论特定主题。
4.3 AF-Think: Towards flexible, on-demand reasoning
最近的研究表明,让 LLM 进行类似于思维链 (CoT) 提示的“思考”,可以提升 LLM 的推理性能,尤其是在编码和数学等复杂任务中(例如 DeepSeek-R1、OpenAI-o1)。视觉 MLLM 也受益于这种范式。在音频领域,Audio-CoT、Audio-Reasoner 和 R1-AQA 等早期尝试探索了 CoT 式推理,但通常收益有限,并且涉及复杂或低效的训练程序。此外,与 [73] 中的发现一致,我们观察到深度、显式思考并不总能提高音频理解任务的性能。
在 AF3 中,我们采用了一种轻量级的思考机制,并进行了两项关键改进:(i) 我们创建了 AF-Think,这是一个包含 25 万道基于多项选择题 (MCQ) 的问答题的数据集,在答案之前会包含简短且可控的思考。这些额外的思考内容作为答案的前缀,平均长度约为 40 个字,为音频问答提供了简洁而有效的上下文(如图 3 所示)。(ii) 我们没有对 CoT 进行明确的后训练,而是在问答提示中添加了一个特殊的后缀(如图 3 所示)。我们将 AF-Think 纳入了 Stage 3.5 的训练组合中,并相对于标准问答数据进行了提升。这使得 AF3 能够仅在提示时进行思考,从而提供灵活、按需的额外推理。
为了生成 AF-Think,我们首先从 AudioSkillsXL 和 LongAudio-XL 中采样一组多项选择推理问答题(最初仅包含正确选项作为答案)。接下来,我们用输入音频、问题和答案提示 Gemini 2.0 Flash,以生成简短的思考前缀。我们发现,与从零开始生成 CoT 相比,Gemini 在以真实答案为指导时,幻觉更少,推理更准确。我们将此过程限制在高质量数据集上,并过滤掉噪声实例。
4.4 AF-Chat: Multi-turn Multi-audio Chat Data
虽然单轮单音频问答训练使 LALM 能够对单个音频输入进行推理,但要实现自由形式、多轮多音频对话,则需要专门的聊天对齐微调阶段,类似于 LLM 使用的指令微调阶段。当需要跨轮次整合多个音频输入时,聊天会变得更加复杂,需要模型跟踪上下文,推理过去和当前输入之间的关系,并生成连贯的后续内容。尽管聊天非常重要,并且是 LLM 最常用的应用,但由于缺乏开放的高质量训练数据,这项功能在 LALM 中仍未得到充分探索。
为了弥补这一差距,我们推出了 AF-Chat,这是一个高质量的微调数据集,包含 75,000 个多轮多音频聊天实例。平均而言,每个对话包含 4.6 个音频片段和 6.2 个对话轮次,范围为 2-8 个音频片段和 2-10 个轮次。为了构建此数据集,我们从 Speech-in-Sound Caps(用于语音和声音)以及 Music4All 和 MSD(用于音乐)中提取数据。我们遵循两步筛选流程:首先,对于每个种子音频,我们结合使用字幕、NV-Embed-v2 嵌入和基于 FAISS 的聚类(详见附录 E.2)来识别其语义上最相似和最不相似的前 8 个片段。对于每个对话,我们都将音频限制在这个池子中。这种有针对性的聚类方法确保每个实例都来自一个多样化但语义连贯的音频池,从而比随机音频选择产生质量更高的对话。
接下来,我们使用精心设计的专家样本(图 36 和 35)提示 GPT-4.1 在以下约束条件下生成自然的多轮聊天会话:(i) 模型可以选择相似/不相似音频的任意子集(最多 10 轮),并优先考虑对话质量;(ii) 并非所有轮次都需要新的音频——鼓励后续提问和澄清问题;(iii) 后续轮次可以参考之前的音频或回复,以模拟真实的对话基础。AF-Chat 的设计基于大量的内部人工研究,以反映用户如何自然地与音频语言模型交互。因此,它提供了丰富多样的监督,用于校准 LALM 来处理复杂、情境化且自然的音频对话。最后,我们为测试集(称为 AF-Chat-test)选择了 200 个高质量样本,并确保这些实例中的音频包含训练期间未见过的音频片段。
5.Audio Flamingo 3 Training Strategy
AF3 采用五阶段策略进行训练,旨在通过增加音频上下文长度、提升数据质量和多样化任务来逐步增强其能力。附录 11 提供了每个阶段使用的完整数据集列表。
阶段 1:对齐预训练。在此阶段,我们仅训练音频 adpter 层,同时保持音频编码器和 LLM 不变。此步骤将编码器表征与语言模型对齐。阶段 2:编码器微调。此阶段的主要目的是使 AF-Whisper 适应不同的数据集,并扩展和提升其音频理解能力。我们在保持 LLM 不变的情况下对音频编码器和 adapter 进行微调。在阶段 1 和阶段 2 中,音频上下文长度均限制为 30 秒,并且训练使用以识别为重点的数据集(例如,分类、字幕和 ASR)。阶段 3:全面微调。此阶段的主要目的是强调 LALM 的推理和技能习得。如前所述,由于特定技能数据在短音频上易于扩展,因此我们在此阶段仍然坚持使用短音频,并使用高质量的基础和 QA 数据集以及我们提出的 AudioSkills-XL。但是,为了适应 AudioSkills 中中等长度的音频,我们现在将音频上下文长度增加到 2.5 分钟。阶段 3.5 结束时生成的模型称为 AF3。阶段 3.5:上下文扩展和思考。此阶段侧重于扩展上下文长度并鼓励 CoT 式推理。除了阶段 3 的数据混合之外,我们还结合了 LongAudio-XL 和 AF-Think。我们采用基于 LoRA 的训练(类似于 LTU 和 GAMA),方法是冻结模型的原始权重并为 LLM 训练 LoRA adapter。这种方法允许最终用户根据需要灵活地增强模型的推理和长上下文理解能力。阶段 4:聊天和语音微调。此阶段侧重于实现多轮、交互式和基于语音的对话。我们在我们提出的 AF-Chat 数据集上对整个模型进行微调,以使 AF3 具备对话式音频理解和回复生成功能。第 4 阶段结束时生成的模型称为 AF3-Chat。