ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
论文链接:https://arxiv.org/pdf/2509.25140
代码链接:
摘要
随着大语言模型 Agent 在现实世界中扮演持续性角色并得到日益广泛的应用,它们自然会遇到源源不断的任务流。然而,一个关键的局限性在于它们无法从累积的交互历史中学习,这迫使它们舍弃宝贵的洞察并重复过去的错误。我们提出了一种名为 ReasoningBank 的新型记忆框架,它从智能体自我判断的成功和失败经验中提炼出可泛化的推理策略。在测试阶段,Agent 从 ReasoningBank 中检索相关记忆以指导其交互,然后将新的学习成果整合回记忆库,从而随着时间的推移不断提升自身能力。基于这种强大的经验学习机制,我们进一步引入了记忆感知测试时扩展(MaTTS),它通过扩展智能体的交互经验来加速和丰富这一学习过程。通过为每个任务分配更多计算资源,智能体可以生成丰富多样的经验,从而为合成更高质量的记忆提供丰富的对比信号。更高质量的记忆反过来又指导更有效的扩展,从而在记忆和测试时扩展之间建立起强大的协同作用。在网页浏览和软件工程基准测试中,ReasoningBank 的性能始终优于现有的仅存储原始轨迹或成功任务例程的记忆机制,显著提升了有效性和效率;MaTTS 进一步放大了这些优势。这些发现确立了基于记忆的经验扩展作为一种新的扩展维度,使 Agent 能够随着涌现行为的自然出现而进行自我演化。
1.介绍
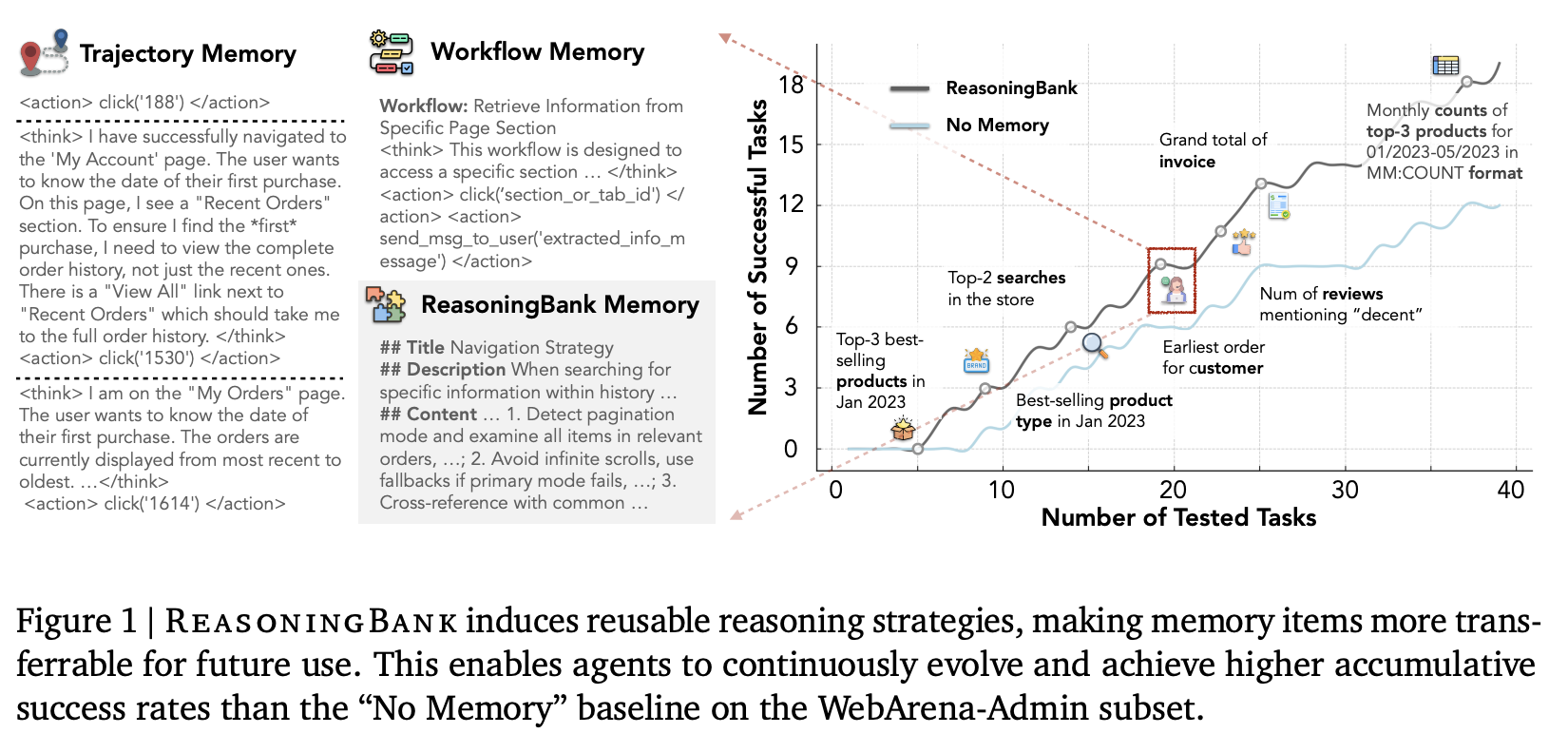
大语言模型(LLM)的快速发展显著加速了 LLM Agent 的开发,而 LLM Agent 对于处理需要与环境进行多步骤交互的复杂现实世界任务至关重要,例如网页浏览和计算机使用。随着这些 Agent 越来越多地被部署在持久、长期运行的角色中,它们在其生命周期内自然会遇到源源不断的任务。然而,它们大多无法从跨任务积累的经验中学习。由于每个任务都是孤立处理的,它们注定会重复过去的错误,忽略相关问题中的宝贵见解,并且缺乏自我进化的能力,无法随着时间的推移提升 Agent 系统的能力。这凸显了构建能够从过去经验中学习的记忆感知型 Agent 系统的必要性。
近年来,Agent 记忆的研究主要集中在存储过往交互以供重用。虽然这些方法很有用,但它们通常仅限于利用原始轨迹或常见的成功例程(例如工作流程、程序)。这些方法存在两个根本缺陷。首先,它们无法提炼出更高层次、可迁移的推理模式。其次,由于过分强调成功经验,它们忽略了智能体从自身失败中吸收蕴含的宝贵教训。因此,现有的记忆设计往往局限于被动记录,而无法为未来的决策提供可操作、可推广的指导。
为了弥合这一差距,我们提出了 ReasoningBank,一种用于 Agent 系统的新型记忆框架。ReasoningBank 能够提炼并组织 Agent 自身判断的成功和失败经验中的记忆项,而无需任何真实标签。如图 1 所示,它不仅捕捉成功经验中的有效策略,还捕捉失败经验中的关键预防教训,并将它们抽象成一系列可操作的原则。这一过程在一个闭环中运行:当面对新任务时,智能体从 ReasoningBank 中检索相关记忆以指导其行动。之后,新的经验会被分析、提炼并整合回 ReasoningBank,从而使 Agent 能够持续演进并提升其战略能力。
以 ReasoningBank 为强大的经验学习器,我们研究经验扩展,旨在建立记忆和测试时扩展之间的强大协同作用。我们并非通过增加任务数量来扩展经验广度,而是专注于通过对每个任务进行更深入的探索来扩展经验深度。我们在并行和串行设置中引入了记忆感知测试时扩展(MaTTS),它能够生成多样化的探索以提供对比信号,从而使 ReasoningBank 能够合成更具泛化的记忆。这在记忆和测试时扩展之间建立了一种协同作用:高质量的记忆引导扩展后的探索朝着更有前景的路径发展,而生成的丰富经验则强化了记忆。这种正反馈循环将记忆驱动的经验扩展定位为 Agent 的一种新的扩展维度。
我们对具有挑战性的网页浏览基准测试(WebArena、Mind2Web)和软件工程基准测试(SWE-Bench-Verified)进行了大量实验。结果表明,我们的方法在有效性(相对提升高达 34.2%,图 4(b))和效率(交互步骤减少 16.0%,表 1)方面均优于基线方法。具体而言,ReasoningBank 与 MaTTS 的协同效应最佳,使其成为实现内存驱动型体验扩展的关键组件。
我们的贡献有三方面:(1) 我们提出了 ReasoningBank,这是一个新的记忆框架,它超越了以往仅限于原始轨迹或仅包含成功案例的例程,能够从成功和失败的经验中提炼出可泛化的推理策略。(2) 我们引入了 MaTTS,它在记忆和测试时尺度之间建立了强大的协同作用,将记忆驱动的经验确立为 Agent 的一种新的尺度维度。(3) 我们通过大量的实验证明,我们的方法不仅比现有方法提高了有效性和效率,而且还使智能体能够从失败中学习,并随着时间的推移发展出越来越复杂、涌现式的推理策略。
2.Related Work
Memory for LLM Agents。记忆已成为现代 Agent 系统中不可或缺的模块,它利用过往信息来提升系统性能。现有的记忆系统以多种形式组织和存储信息,包括纯文本、潜在知识嵌入和结构化图。除了记忆内容之外,这些方法通常还涉及检索机制(例如语义搜索)和记忆管理策略(例如更新)。近年来,随着强化学习(RL)在 LLM Agent 中的蓬勃发展,RL 也被用于 Agent 系统的记忆管理。虽然大多数研究主要侧重于个性化和长上下文管理,但本文的研究方向是利用过往经验作为记忆进行学习,这对于开发自进化 Agent 系统至关重要。与以往强调重用成功轨迹或流程化工作流的工作不同,ReasoningBank 存储的是高级策略和推理提示。通过将经验抽象成可重用的推理单元,ReasoningBank 使 Agent 不仅能够从成功案例中进行泛化,还能从失败中学习,从而为测试时学习提供更丰富的指导。此外,我们率先探索了记忆感知测试时间扩展,其中 ReasoningBank 与来自丰富探索轨迹的各种信号协同工作。
Agent Test-Time Scaling。测试时扩展(TTS)已展现出强大的有效性,并已成为端到端问题解决(例如编码和数学推理)中广泛采用的实践方法。其中,常用的方法包括 best-of-N 解法、集束搜索法以及利用验证器。然而,其在多轮交互场景(尤其是智能体任务)中的应用仍有待深入探索。现有研究主要借鉴了推理任务的经验,并对 Agent 系统的不同维度进行了扩展,包括每个动作的搜索空间、多智能体系统中的 Agent 数量以及与环境的交互次数。我们发现,这些研究均未考虑 Agent 记忆在扩展中的作用,即智能体可以从过去的经验中学习以指导未来的决策。我们的工作通过引入记忆感知测试时扩展(MaTTS)拓展了这一研究方向。正如我们将在实证结果(§4.3 和 §4.4)中展示的那样,记忆带来的好处远不止于计算扩展,记忆和扩展能够协同作用,从而提升系统性能。
3.Methodology
在本节中,我们介绍问题设置(§3.1),并提出我们提出的 ReasoningBank(§3.2),在此基础上,我们进一步开发记忆感知测试时间扩展(MaTTS)(§3.3)。
3.1 Problem Formulation
Agent Configuration。本文的研究范围聚焦于基于 LLM 的 Agent。Agent 策略 由骨干 LLM 、记忆模块 和动作空间 参数化,简记为 。Agent 需要通过与环境交互来执行任务,这可以看作是一个序列决策过程。形式上,环境的转移函数定义为 ,其中 表示状态, 表示 在时间 选择的动作。我们主要关注网页浏览和软件工程(SWE)任务。 是网页浏览任务的网页导航操作集合,也是 SWE 任务的 bash 命令集合, 是推理库,初始值为空。对于每个给定的任务,Agent 生成一个包含 步的轨迹 ,其中观测值 来自当前状态 。观测值可以是网页浏览任务中基于文本的网页可访问性树,也可以是软件工程任务中的代码片段。Agent 需要通过 生成一个动作 。在实现过程中,记忆模块 会将相关的记忆作为 的附加 system prompt 提供。
Test-Time Learning。我们关注测试时学习范式,其中任务 query 序列 以流式方式到达,即每个qeury 都会被揭示,并且必须按顺序完成,无法访问后续 query。在这种情况下,测试时没有可用的真实标签,因此 Agent 必须仅利用自身的历史轨迹和自我验证来不断进化,而不能依赖外部标签。这种流式设置凸显了两个关键挑战:(i)如何从历史轨迹中提取和保留有用的记忆,以及(ii)如何有效地利用这些记忆来处理未来的 qeury,以避免重复发现已经成功的策略或重蹈覆辙。
3.2. ReasoningBank
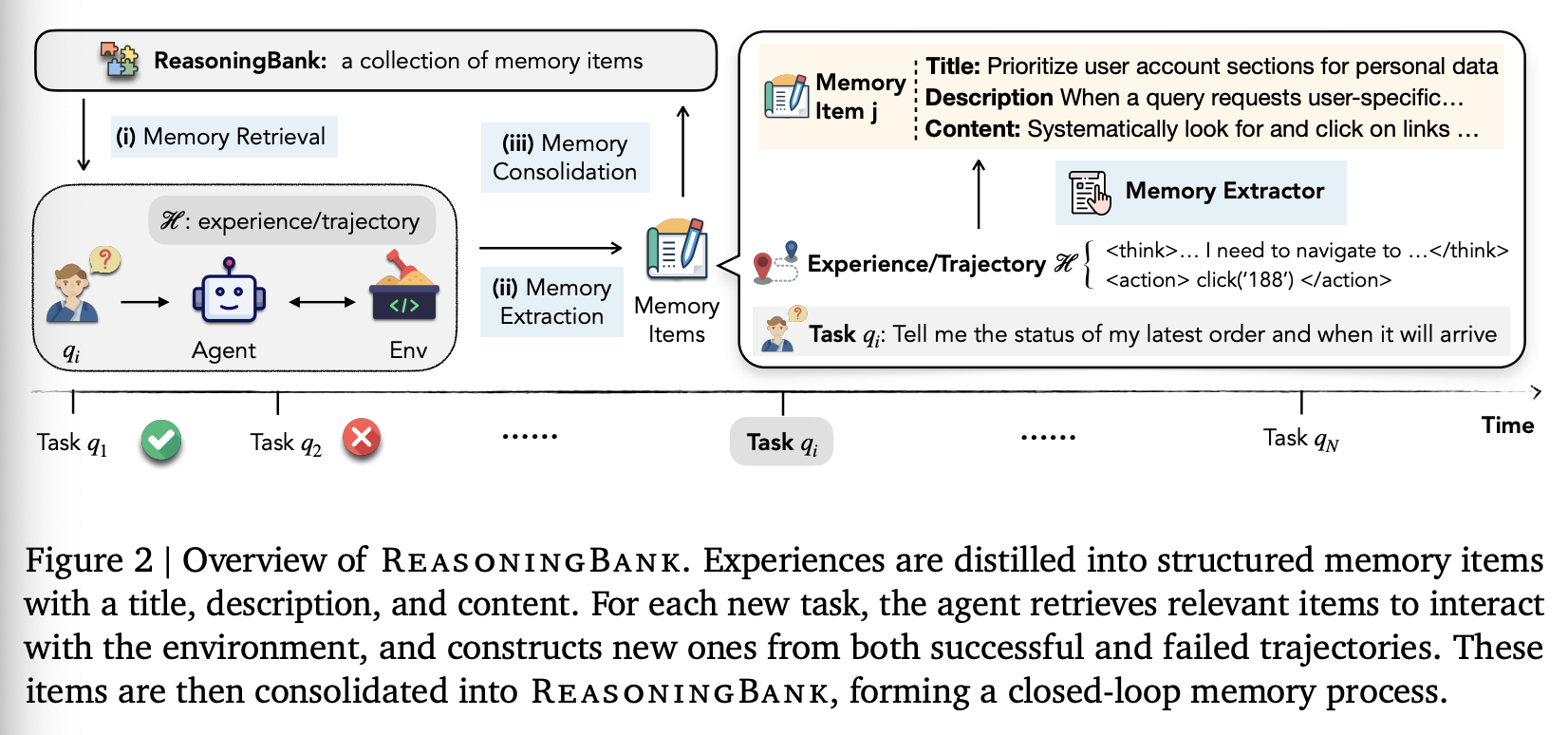
过去的原始轨迹(或经验)虽然全面且独到,但通常过于冗长且杂乱,无法直接应用于当前用户的 qeury。如图 2 所示,ReasoningBank 将过去经验中的有用策略和推理提示提炼成结构化的记忆项,并存储起来以供将来重用。
Memory Schema。ReasoningBank 中的记忆项是根据过往经验设计和生成的结构化知识单元,它们抽象化了底层执行细节,同时保留了可迁移的推理模式和策略。每个记忆项包含三个部分:(i)title,作为简洁的标识符,概括核心策略或推理模式;(ii)description,提供记忆项的简短概括(一句话);(iii)content,记录从过往经验中提取的精炼推理步骤、决策依据或操作见解。这些记忆项既易于人类理解,又具有很强的实用性。
Integration of ReasoningBank with Agents。配备 ReasoningBank 的 Agent 可以利用精心整理的可迁移策略库来指导决策。这使得 Agent 能够回忆起有效的洞察,避免先前观察到的陷阱,并更稳健地适应未知的查询。集成过程分为三个步骤:(i)记忆检索,(ii)记忆构建,以及(iii)记忆巩固,如图 2 所示。在记忆检索阶段,Agent 使用当前查询上下文查询 ReasoningBank,通过基于嵌入的相似性搜索来识别 top-k 个最相关的经验及其对应的记忆项。检索到的记忆项会被注入到 Agent 的 system prompt 中,确保决策建立在有用的过往经验之上。当前查询任务完成后,我们将执行记忆构建以提取新的记忆项。第一步是获取已完成轨迹正确性的 Agent 信号:我们采用 LLM 作为评判器,在不参考任何真实值的情况下,根据查询和轨迹将结果标记为成功或失败。基于这些信号,我们应用不同的提取策略:成功的经验提供已验证的策略,而失败的经验则提供反事实信号和陷阱,有助于完善安全防护措施。在实践中,我们为每条轨迹/经验提取多个记忆项,详见附录 A.1。最后,记忆整合通过简单的加法运算将这些项整合到 ReasonBank 中,从而维护一个不断更新的记忆项库。详细信息见附录 A.2。这些步骤共同构成了一个闭环过程:Agent 利用过去的经验,从当前任务中构建新的记忆,并不断更新其记忆,从而在测试学习场景中实现持续进化。
3.3 MaTTS: Memory-aware Test-Time Scaling
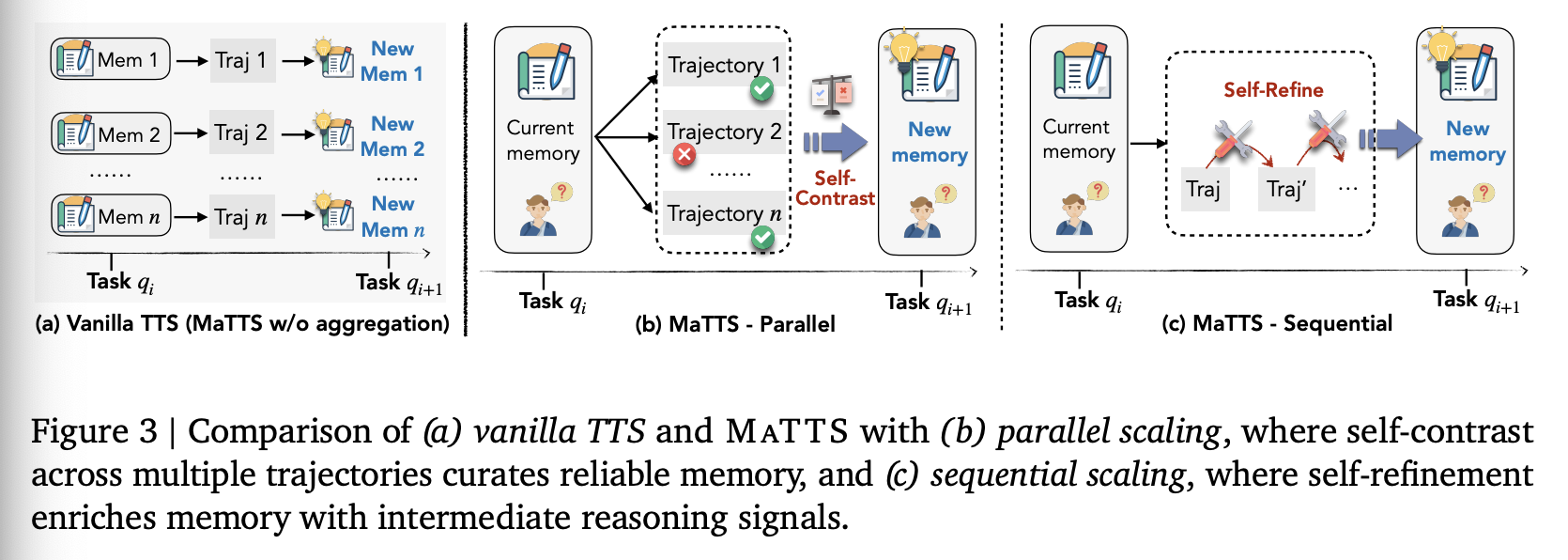
ReasoningBank 能够从经验中学习,从而将更多经验转化为更大的改进。测试时扩展最近作为一种提升 LLM Agent 性能的有效策略展现出巨大的潜力,它通过分配额外的推理时计算来生成丰富的探索历史。图 3(a) 展示了 ReasoningBank 与测试时扩展的直接结合,其中更多轨迹被独立地转换为更多记忆项。然而,这种原始方法并非最优,因为它没有利用同一问题上重复探索所产生的固有对比信号,从而限制了测试时扩展带来的性能优势。为了解决这个问题,我们提出了记忆感知测试时扩展(MaTTS),一种将测试时扩展与 ReasoningBank 相结合的新方法。与原始方法不同,MaTTS 会主动学习扩展过程中生成的大量成功和失败轨迹,从而更有效地管理记忆。我们为 MaTTS 设计了两种互补的实例化方式:并行扩展和顺序扩展,如图 3(b) 和 3(c) 所示,详细实现见附录 A.3。
Parallel Scaling。在并行设置中,我们根据检索到的记忆项,为同一 query 生成多条轨迹。通过比较和对比(自我对比)不同轨迹,Agent 可以识别一致的推理模式,同时过滤掉虚假解决方案。这一过程使得从对同一查询的多次尝试中能够更可靠地整理记忆,从而促进多样化的探索。
Sequential Scaling。在初始完成后,我们遵循自我细化的原则,在单一路径内迭代地完善其推理过程。在此过程中,自我完善过程中生成的中间笔记也被用作宝贵的记忆信号,因为它们记录了推理尝试、修正和可能未出现在最终解决方案中的见解。
我们定义扩展因子 ,它表示并行扩展的轨迹数和顺序扩展的细化步骤数。借助 ReasoningBank,并行和顺序策略都具备记忆感知能力,确保在测试时分配的额外计算量能够转化为更易迁移、更高质量的记忆,供后续任务使用。