Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory
论文链接:https://arxiv.org/pdf/2504.07952
代码链接:http://github.com/suzgunmirac/dynamic-cheatsheet
摘要
尽管当前的语言模型 (LM) 在复杂任务上表现出色,但它们通常运行于 vacuum 状态:每个输入 query 都被单独处理,无法保留来自先前尝试的思考结果。在此,我们提出了 Dynamic Cheatsheet (DC),这是一个轻量级框架,它赋予黑盒语言模型 (LM) 持久且不断发展的记忆。DC 使模型能够在推理时存储和重用累积的策略、代码片段和通用的解决问题的观点,而无需反复重新发现或提交相同的解决方案和错误。这种测试时学习无需明确的真实标签或人工反馈,即可显著提升一系列任务的性能。利用 DC,Claude 3.5 Sonnet 在 AIME 数学考试中,一旦开始在各个问题中保留代数观点,其准确率就提高了一倍以上。同样,在模型发现并重用基于 Python 的解决方案后,GPT-4o 在 24 点游戏谜题上的成功率从约 10% 提升至 99%。在容易出现算术错误的任务中,例如平衡方程式,DC 通过调用先前验证过的代码,使 GPT-4o 和 Claude 达到了近乎完美的准确率,而它们的基线则停滞在 50% 左右。除了算术挑战之外,DC 在知识密集型任务中也显著提高了准确率。Claude 在 GPQA-Diamond 中提高了 9%,在 MMLU-Pro 工程和物理问题中提高了 8%。至关重要的是,DC 的记忆是自我管理的,专注于简洁、可迁移的片段,而不是完整的文本,从而促进了元学习并避免了上下文膨胀。与微调或静态检索方法不同,DC 可以动态调整语言模型解决问题的技能,而无需修改其底层参数,并提供了一种持续改进响应和减少常规错误的实用方法。总体而言,我们的研究结果表明,DC 是一种很有前途的方法,可以用持久记忆来增强 LM,链接孤立推理事件与人类认知的累积、经验驱动学习特征之间的鸿沟。
1.介绍
现代大语言模型 (LLM) 可以处理复杂的推理任务,回答各种问题,并生成海量文本。然而,它们仍然存在一个关键的局限性:一旦部署,这些模型就会在部署前就被固定下来,并且通常不会保留过去推理过程中的问题、成功或错误的显式或隐式记忆。它们会从头开始处理每个新问题,通常会重新得出相同的见解,并再次犯同样的错误。相比之下,人类认知建立在渐进学习的基础上,不断将新的经验和解决方案内化为持久的心智模型。
在本文中,我们提出了 Dynamic Cheatsheet (DC),这是一个简单直观的框架,它赋予黑盒大语言模型 (LLM) 在推理时持久且不断演化的记忆。与传统的检索增强生成系统不同,DC 并非通过微调权重(例如,通过动态评估或领域自适应)或从海量静态语料库中检索事实,而是动态地整理一个包含可重用策略、解决方案草图和代码片段的紧凑库。无论是在每次 query 之前还是之后,DC 都使系统能够决定存储哪些课程、丢弃哪些课程以及如何优化现有条目——从而有效地从成功和失败中“学习”。这是一种灵活的在线学习方法,使黑盒大语言模型 (LLM) 能够自我改进,而无需任何明确的 ground truth 标签或人工反馈。
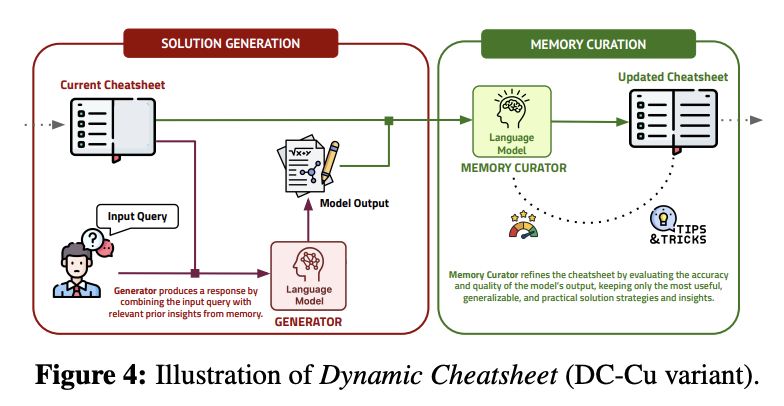
DC 的整体工作流程直观且引人注目。在 DC 的一个版本 (DC-Cu.) 中,当收到新的 query 时,语言模型 (LM) 首先会查询其外部存储器,查看是否存储了任何先前的思考、策略或相关的模型解决方案。然后,它会将检索到的洞察与其自身的内部推理能力相结合,提出解决方案。生成答案后,它会进入整理阶段,更新记忆:如果该方法看起来正确、有用或实用,DC 会将其编码到记忆中,以备将来使用;如果出现错误,DC 可能会修改或修剪错误的启发式方法。所有这些都无需基于梯度的参数更新,因此计算开销保持在较低水平,并且与黑盒 API(例如 GPT-4 或 Claude)的兼容性也得到了完全保留。参见图 4。
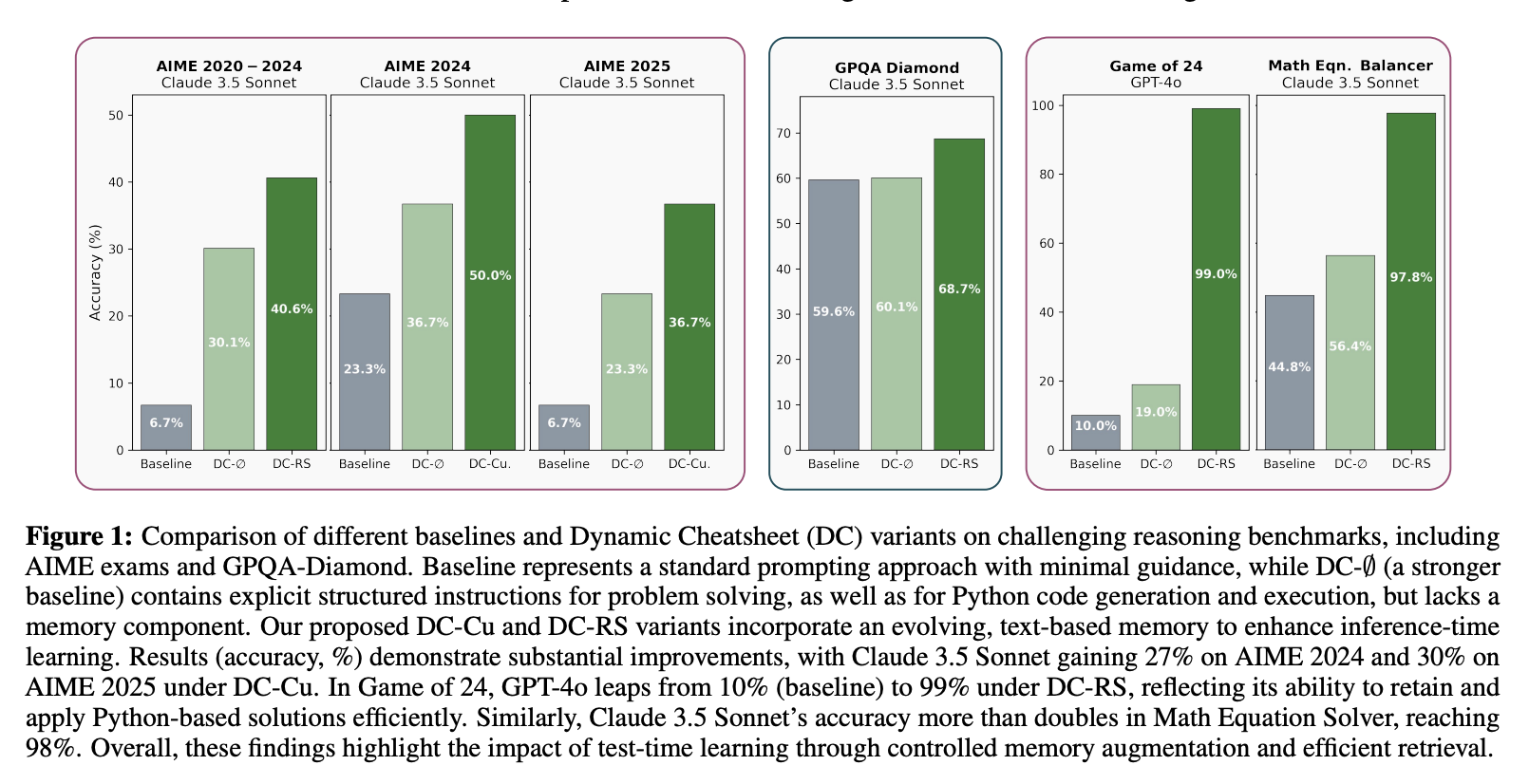
我们在多个具有挑战性的基准测试中测试了 DC,并观察到它提升了性能并减少了重复性错误。在 AIME 2024 上,通过保留代数和组合思考,Claude 3.5 Sonnet 的准确率从 23% 跃升至 50%,是其基线得分的两倍多。同样,它在 AIME 2025 上也获得了 30% 的准确率。值得注意的是,这些改进在知识密集型任务中也同样有效。在测试专业领域问题的 GPQA-Diamond 中,DC 将 Claude 的得分提升了 9% 以上。在 MMLU-Pro 工程与物理测试中,通过允许模型保留公式和通用问题解决模式的“工具包”,DC 的性能提升高达 8%。
一个更引人注目、更令人信服的例子是“24 游戏”,这道题要求解题者将四位数字组合成一个等于 24 的算术表达式。GPT-4o 的基准性能(10%)在 DC 下提升到了 99%。在测试序列的早期,该模型发现一个高效的 Python 暴力破解解题器可以消除所有手动猜测。存储这段代码后,GPT-4o 只需将其检索用于后续查询,即可完全避免手动计算。我们在“数学方程式平衡器”中也看到了类似的模式,GPT-4o 和 Claude 通过“调用”一种简单的基于代码的方法,而不是手动进行数字操作,将准确率从 45-50% 飙升至 98-100%。
尽管如此,DC 并非万能药。我们发现,像 GPT-4o-mini 这样的小型模型从 DC 中获益有限。这些模型在这些具有挑战性的任务中生成的正确解太少,导致记忆中充斥着有缺陷或不完整的策略。更糟糕的是,它们难以优化记忆的内容。DC 可以增强那些已经能够生成高质量输出的模型的优势,但无法修复推理过程中的基础缺陷。
我们还注意到,DC 与简单的“附加整个对话历史记录”式上下文学习方法不同。在 DC 下,记忆经过精心设计,侧重于简洁、实用且可迁移的知识,而非原始记录。这可以防止上下文长度膨胀,并有助于确保重复检索仍然易于处理。事实上,DC 的部分贡献在于形式化了一种选择性、渐进式记忆机制——存储刚好足以解决下一组任务的信息,而不会被不断增长的文本缓冲区淹没。
2.Dynamic Cheatsheet (DC) Methodology
DC 的核心在于包含一个外部非参数记忆,它会随着 LLM 的推理过程而演化。DC 并非对底层权重进行微调,而是在测试时跟踪模型的成功和失败,然后选择性地存储启发式方法、策略或简短的文本信息,以便在未来的实例中指导 LLM。值得注意的是,这种方法尊重了许多商业 LLM API 的黑盒特性:无需基于梯度的更新,并且模型的核心参数保持不变。
2.1 DC: Building Blocks and Iterative Loop
DC 框架由两个核心模块组成:生成模块和设计模块。这两个模块可以轻松地在同一个语言模型(提示不同)或单独的语言模型上运行。
2.1.1 Solution Generation with Memory
假设输入序列为 ,其中每个 表示一个新查询或问题,该查询或问题取自同一分布 (在线学习中的典型场景)。我们不知道分布 。在第 步,模型同时获得新查询 和当前记忆状态 ,后者捕获了从先前成功和失败中收集到的知识。我们将解决方案生成器表示为 :
这里, 是模型生成的候选解。 有助于调整模型,使其能够重用或调整先前记忆的解决方案、见解、技术或启发式方法。
2.1.2 Memory Curation Step
在生成器生成 的答案 之后,设计器 会更新记忆的当前内容:
在记忆设计过程中, 主要考虑:(i)新产生的答案的实用性和普遍性(即,如果 是正确的或提供了有价值且可推广的见解,则将其提炼为适合以后参考的形式),(ii)改进或删除现有的记忆条目(即,如果现有的记忆条目不正确或被更有效或更通用的策略取代,Cur 可能会删除或更新它),以及(iii)整个记忆的清晰度和紧凑性(即,合并记忆条目以保留简洁、高影响力的参考和启发式方法)。
无法访问真实标签;因此,它必须在更新记忆之前自行评估解决方案的正确性和效率。在我们的实验中,我们指示单个模型执行这一关键步骤。然而,在实践中, 可以实现为一系列步骤,通过不同的提示指示多个工具和模型来验证解决方案的有效性和效率,并将原始解决方案文本转换为更通用、更可靠、更高效的策略、见解和代码片段。
我们将上述 DC 的这个版本称为 DC-Cu(DC-Cumulative 的缩写)。在 DC-Cu 下,系统首先根据当前记忆(公式 1)生成解决方案,然后通过累积扩展和细化迄今为止的记忆项来更新记忆(公式 2)。然而,与下一部分将要讨论的 DC-RS 不同,DC-Cu 不包含检索组件。
2.2 DC with Retrieval & Synthesis (DC-RS)
DC-Cu 有两个潜在缺点。首先,它会在处理输入查询后更新记忆,而不是在生成响应之前对其进行优化。这意味着模型在推理解决方案时缺乏从当前查询中汲取新见解的机会。其次,除非明确地将过去的输入输出对保留在记忆中,否则 DC-Cu 不会存储或重新访问它们。这种遗漏导致模型无法直接检索和利用历史响应,而这在涵盖不同主题或领域的基准测试(例如 GPQA-Diamond)中尤其有用。
为了解决这些问题,DC-RS 修改了记忆更新的顺序,并在设计过程中引入了检索机制 。 允许模型从其知识库中检索最相关的过去输入输出对。通过在响应之前优化记忆并在需要时检索先前案例,DC-RS 增强了模型的适应性和推理效率。
DC-RS 首先从之前见过的样本中检索前 k 个最相似的输入及其模型生成的输出,我们将其表示为 (或简称为 )。然后,它将这些选定的样本 以及最新的记忆内容 传递给设计器,以更新记忆,即得到 。最后,给定 和 ,它使用生成器生成 。我们将所有这些步骤总结如下:
2.3 Baselines
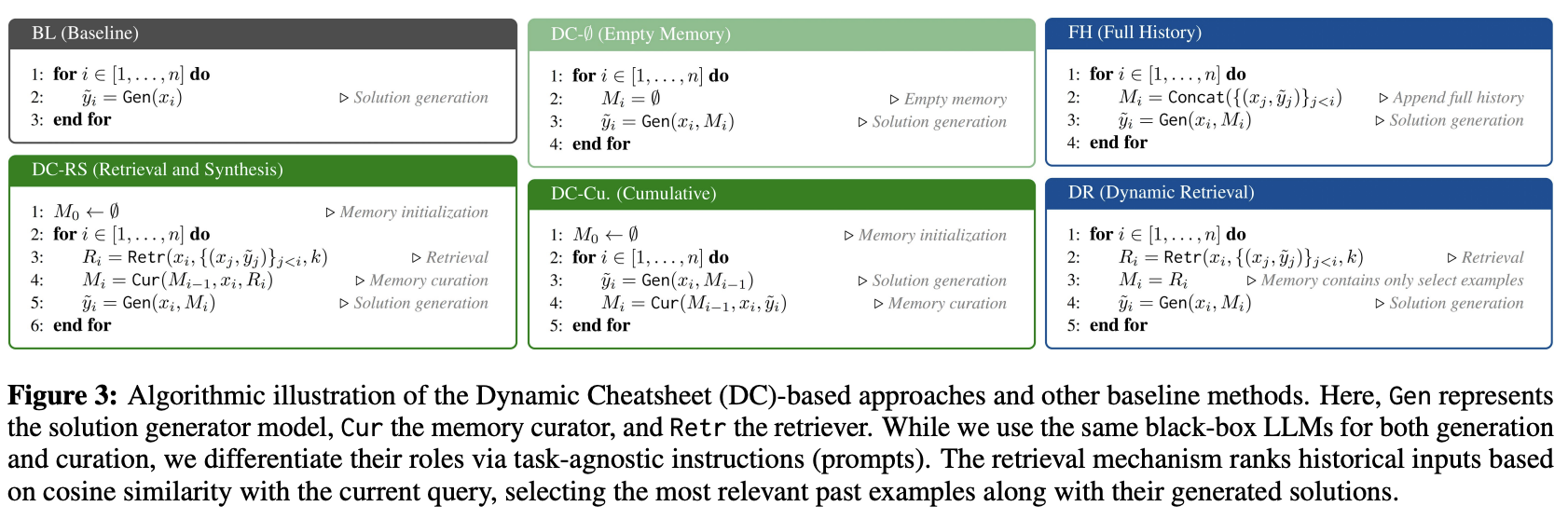
为了量化记忆驱动的测试时间学习的效果,我们将 DC 及其变体与四个基线进行比较:
(1)Baseline prompting (BL)。这种简单的“vanilla”提示方法,指令极少,只是简单地提示模型,没有任何迭代记忆或检索机制。它体现了传统的一次性推理。
(2)DC-∅ (empty memory)。为了隔离记忆管理的影响,此 DC 基线始终保持记忆内容有效为空。DC-∅ 使我们能够衡量随着时间的推移,纯粹通过存储和重用知识所带来的性能提升。虽然没有持续的知识存储或策略重用,但此方法遵循图 13 中的说明,因此是一个强大的基线。
(3)Full-History Appending (FH)。这是一种简单的方法,它将整个对话历史记录附加到模型输入中,而无需任何整理或截断。FH 可能会超出上下文窗口的限制,并包含冗余或低价值的信息,但尽管如此,它仍然为主动整理内容的方法提供了有用的比较。
(4)Dynamic Retrieval (DR)。最终的基线模型使用检索,但不进行整理。具体来说,对于每个新查询,它会检索过去最相似的交互,并直接将它们逐字粘贴到提示中。DR 可以帮助模型看到相关的输入-输出对,但不能直接整理任何抽象或广义的解决方案。
图 3(上图)包含本文考虑的所有主要方法和基线的伪代码。