Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
论文链接:https://arxiv.org/pdf/2307.06304
代码链接:
摘要
在计算机视觉模型处理图像之前,将图像缩放到固定分辨率的做法虽然普遍存在,但显然并非最优选择,至今尚未有人成功挑战这种做法。然而,诸如 Vision Transformer (ViT) 之类的模型提供了灵活的基于序列的建模方式,因此可以处理不同长度的输入序列。我们利用这一优势开发了 NaViT(Native Resolution ViT),它在训练过程中使用序列打包技术来处理任意分辨率和宽高比的输入。除了模型使用的灵活性之外,我们还展示了 NaViT 在大规模监督式和对比式图像-文本预训练中显著提升的训练效率。NaViT 可以高效地迁移到图像和视频分类、目标检测和语义分割等标准任务,并在鲁棒性和公平性基准测试中取得了更佳的结果。在推理阶段,输入分辨率的灵活性可以用来平滑地权衡测试时的成本和性能。我们相信,NaViT 标志着大多数计算机视觉模型所使用的标准 CNN 设计的输入和建模流程的突破,并为 ViT 的发展指明了一个充满希望的方向。
1.介绍
Vision Transformer (ViT) 的简单、灵活和可扩展性使其几乎成为卷积神经网络的普遍替代方案。该模型的核心在于一个简单的操作:将图像分割成多个图像块,每个图像块线性投影到一个 token 上。通常,输入图像会被调整为固定的正方形宽高比,然后分割成固定数量的图像块。
近期的研究探索了这种范式的替代方案:FlexiViT 在同一架构中支持多种图像块尺寸,从而能够平滑地调整序列长度,进而降低计算成本。这是通过在每个训练步骤中随机采样图像块尺寸,并采用一种调整大小的算法来实现的,该算法允许初始卷积嵌入支持多种图像块尺寸。Pix2Struct 引入了一种替代的图像块处理方法,该方法能够保持图像的宽高比,这对于图表和文档理解等任务尤为有用。
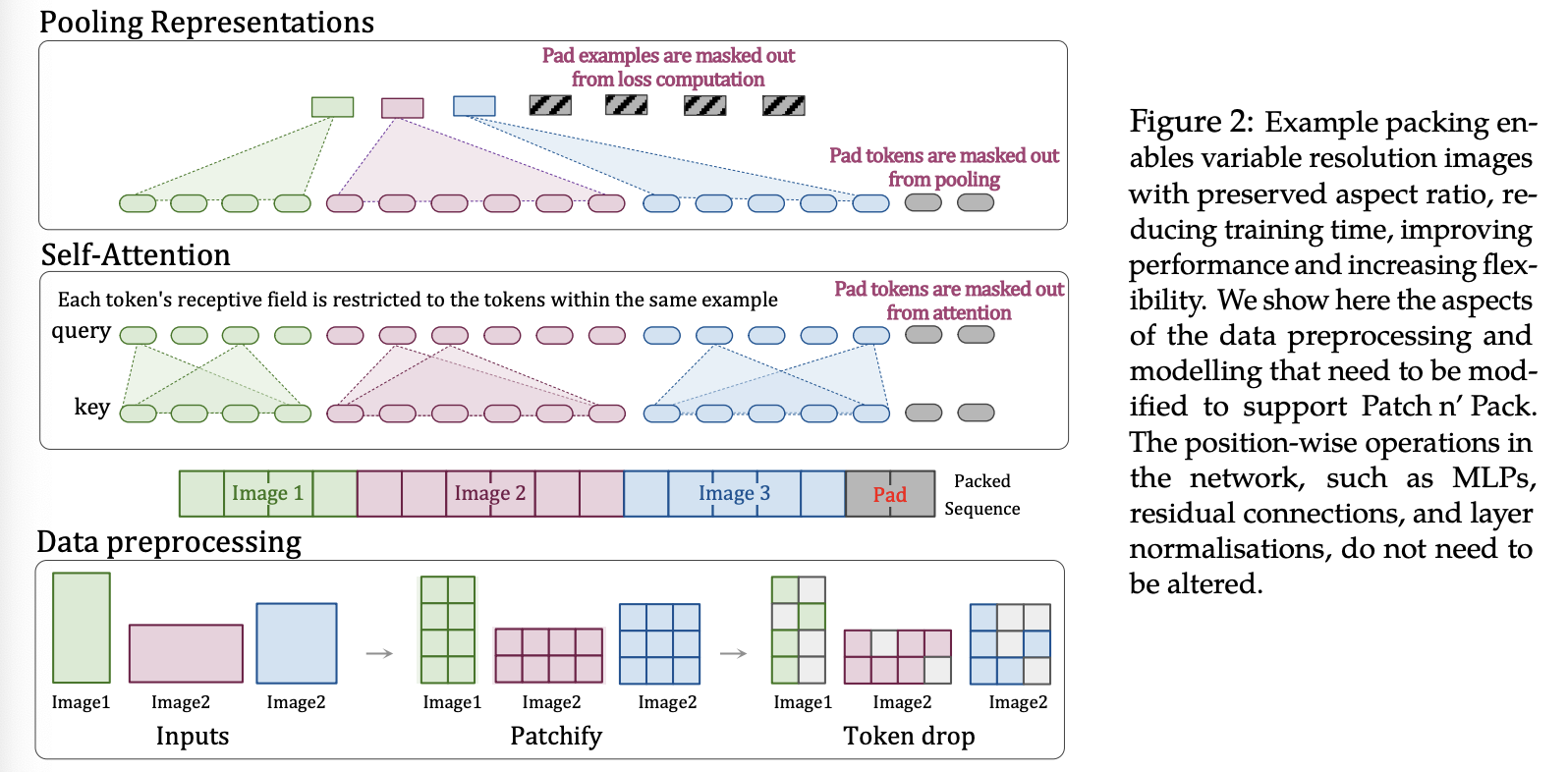
我们提出了一种替代方案,NaViT。它将来自不同图像的多个图像块打包成一个序列(称为 Patch n’ Pack),从而在保持宽高比的同时实现可变分辨率(图 2)。这种方法的灵感来源于自然语言处理中的样例打包,即把多个样例打包成一个序列,以便高效地训练不同长度的输入。
我们证明:(i) 在训练时随机采样分辨率可显著降低训练成本。(ii) NaViT 在广泛的分辨率范围内均能取得高性能,从而在推理时实现平滑的成本-性能权衡,并且可以以较低的成本适应新的任务。(iii) 通过样例打包实现的固定 batch size 引出了新的研究思路,例如保持纵横比的分辨率采样、可变 token 丢弃率和自适应计算。
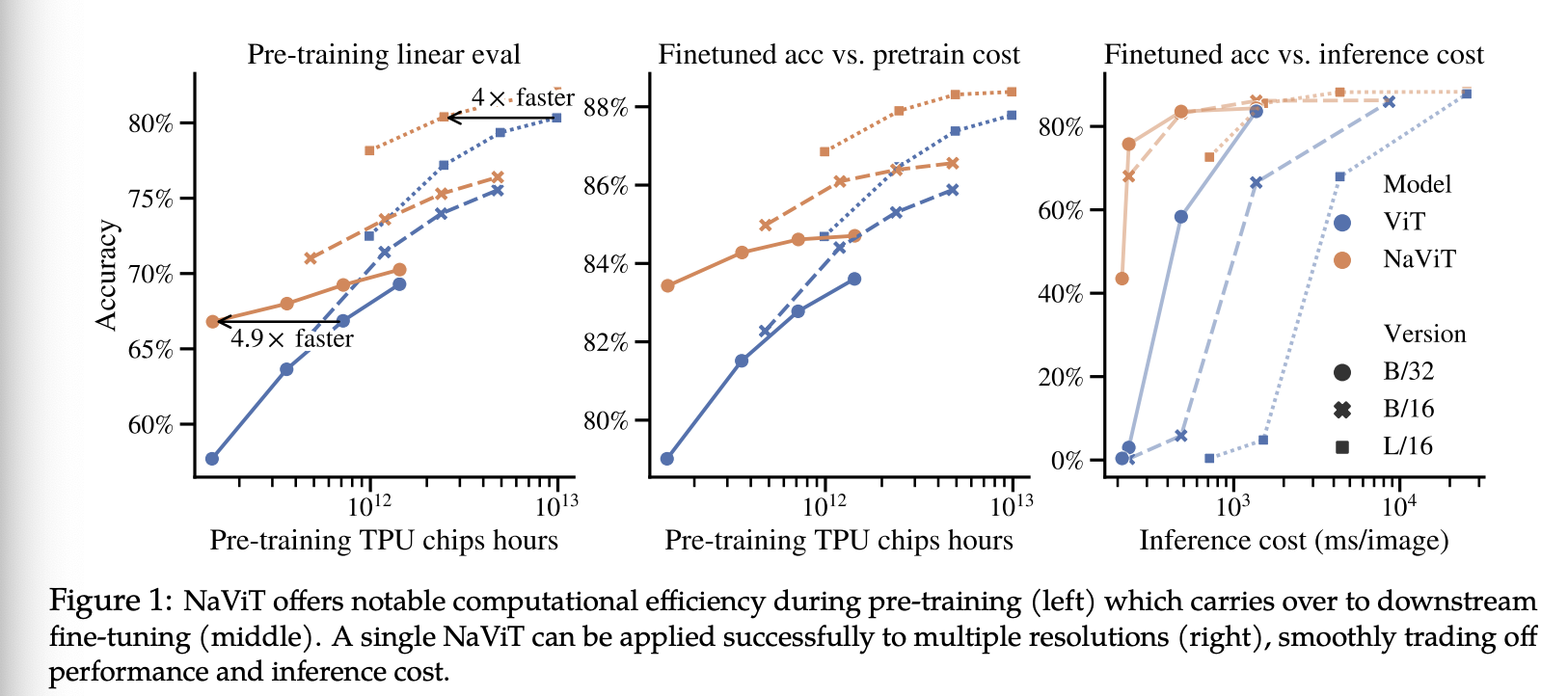
这些观察结果具有重要的实际意义。在固定的计算预算下,NaViT 的性能始终优于 ViT。例如,我们仅用四分之一的计算资源就达到了性能最佳的 ViT 的性能(图 1,左)。我们发现,在分配的计算预算内处理的训练样本数量的大幅增加是其性能优于 ViT 的主要原因——样本打包、可变分辨率输入和可变 token 丢弃使得 NaViT-L/16 在训练期间能够处理五倍于 ViT 的图像数量(表 2)。这种效率的提升也体现在微调过程中(图 1,中)。此外,通过在预训练和微调期间让 NaViT 接触多种分辨率,单个模型在各种分辨率下均表现出色,显著降低了推理成本(图 1,右)。
NaViT 的训练和适应效率以及灵活的推理能力,为视觉 Transformers 开辟了一条充满希望的道路。Patch n’ Pack 使计算机视觉系统能够超越当前数据和建模流程的限制,实现以往受限于固定批次形状的理念,从而为创新和发展开启新的可能性。
2.Method

深度神经网络通常使用 batch 输入进行训练和运行。为了在当前硬件上高效处理,这意味着 batch 形状固定,进而意味着计算机视觉应用中图像尺寸固定。再加上卷积神经网络固有的架构限制,导致人们通常采用调整图像大小或填充图像的方式来使其达到固定尺寸。然而,这两种方法都被证明存在缺陷:前者会降低性能,后者效率低下。对 ImageNet、LVIS 和 WebLI 这三个分别代表分类、检测和网络图像数据集的数据集进行分析,结果表明大多数图像通常并非正方形(图 3)。
在语言建模中,通常通过样例打包来绕过固定序列长度的限制:将来自多个不同样例的 token 组合成一个序列,这可以显著加速语言模型的训练。通过将图像视为图像块(token)序列,我们证明视觉Transformer模型也能受益于同样的范式,我们称之为Patch n’ Pack。利用这项技术,ViTs 模型可以在图像的“原生”分辨率下进行训练,我们将这种方法命名为 NaViT。
2.1 Architectural changes
NaViT 构建于原始 ViT 之上,但原则上可以使用任何处理 patch 序列的 ViT 变体。为了实现 Patch n’ Pack 功能,我们进行了以下架构修改。
Masked self attention and masked pooling。为了防止样本间相互关注,引入了额外的自注意力掩码。类似地,编码器之上的 mask 池化旨在池化每个样本内的 token 表示,从而为序列中的每个样本生成一个单一的向量表示。图 2 展示了如何通过 mask 控制注意力感受野。
Factorized & fractional positional embeddings。为了处理任意分辨率和宽高比,我们重新审视了位置嵌入。给定分辨率为 的正方形图像,一个图像 patch size 为 的标准 ViT 算法可以学习长度为 的一维位置嵌入。为了在更高分辨率 下进行训练或评估,需要对这些嵌入进行线性插值。
Pix2struct 引入了可学习的二维绝对位置嵌入,它学习大小为 的位置嵌入,并用每个图像 patch 的 坐标进行索引。这使得图像能够支持可变的宽高比,分辨率最高可达 。然而,在训练过程中,必须观察所有 坐标的组合。
为了支持可变宽高比并能轻松外推至未知分辨率,我们引入了分解式位置嵌入,将图像分解为分别对应 和 坐标的独立嵌入 和 。然后将它们相加(其他组合策略将在 3.4 节中探讨)。我们考虑两种方案:绝对嵌入,其中 是图像块绝对索引的函数;以及分数嵌入,其中 是 的函数,即图像上的相对距离。后者提供了与图像大小无关的位置嵌入参数,但部分模糊了原始宽高比,此时宽高比仅隐含在图像块的数量中。我们考虑了简单的学习嵌入 、正弦嵌入以及 NeRF 使用的学习傅里叶位置嵌入。
2.2 Training changes
Patch n’ pack 使 NaViT 训练中能够使用新技术。
Continuous Token dropping。为了加速训练,人们开发了 token 丢弃(在训练过程中随机省略输入图像块)技术。然而,通常情况下,所有样本中丢弃的 token 比例相同;而打包技术则允许连续丢弃 token,并且可以根据每幅图像调整 token 丢弃率。这使得在丢弃部分 token 的同时仍能保留一些完整图像,从而提高了训练吞吐量,并减少了训练集和推理集之间的差异。此外,通过打包技术,token 丢弃的分布可以根据预定义的计划在整个训练过程中发生变化。在3.3节中,我们将探讨不同的计划以及灵活 token 丢弃的优势。
Resolution sampling。NaViT 可以使用每幅图像的原始分辨率进行训练。或者,也可以在保持宽高比的前提下对总像素数进行重采样。在传统的 ViT 中,高吞吐量(使用较小的图像进行训练)和高性能(使用较大的图像进行训练,以便在评估时使用高分辨率图像)之间存在着矛盾。通常,模型会在较低分辨率下进行预训练,然后在较高分辨率下进行微调。NaViT 则更加灵活;它允许通过从图像尺寸分布中采样来进行混合分辨率训练,同时保持每幅图像的原始宽高比。这既可以提高吞吐量,又可以处理较大的图像,从而在模型大小和训练时长方面,显著提升性能,优于其他同等的 ViT 方法。第 3.2 节将探讨不同的采样策略以及用于预训练和微调的可变分辨率训练。
2.3 Efficiency of NaViT
在这里,我们讨论 Patch n’ Pack 对 NaViT 计算效率的一些影响。
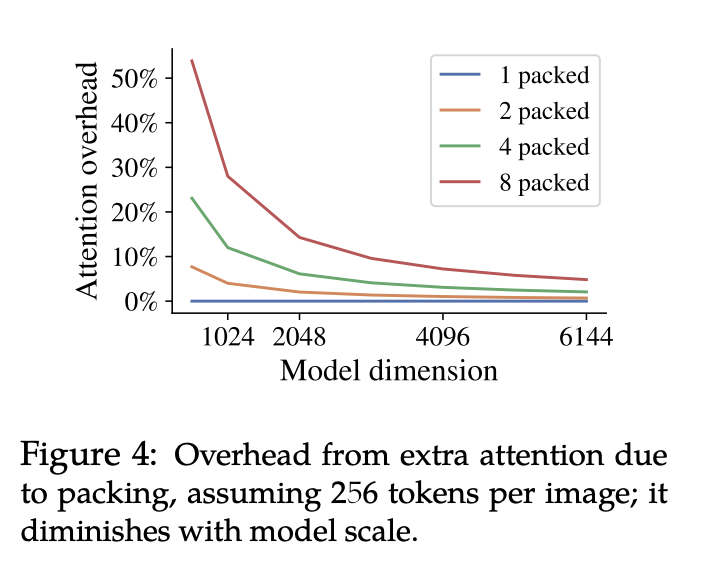
Self attention cost。当将多张图像打包成更长的序列时,注意力机制的 O(n²) 开销自然是一个需要考虑的问题。尽管许多工作致力于消除这种二次方缩放,但我们在此证明,随着 Transformer 隐藏层维度的增加,注意力机制在总开销(包括 MLP 的计算开销)中所占的比例会越来越小。图 4 展示了这一趋势,表明打包示例的开销相应减少。除了速度方面的考虑,自注意力机制的内存开销对于极长的序列来说也是一个挑战。然而,这一挑战也可以通过采用内存高效的方法来解决。
Packing, and sequence-level padding。包含多个样本的最终序列长度必须固定。我们采用附录 A.3 中讨论的贪婪打包方法;通常情况下,不存在长度刚好等于固定长度的样本组合,因此必须使用填充 token。例如,可以动态选择序列中最后一个样本的分辨率或 token 丢弃率,使其与剩余 token 的长度完全匹配;然而,我们发现通常只有不到 2% 的 token 是填充 token,因此这种简单的方法就足够了。
Padding examples and the contrastive loss。对于打包序列,逐 token 损失函数的实现非常简单。然而,许多计算机视觉模型使用样本级损失函数进行训练,通常应用于池化表示。首先,这需要对典型的池化头进行修改以适应打包。其次,必须从每个序列中提取多个池化表示。固定 batch size 要求我们假设,从包含 B 个序列的批次中,最多提取 个池化表示(即每个序列 个样本)。如果一个序列包含的图像超过 个,则多余的图像将被丢弃,从而浪费模型编码器的计算资源。如果一个序列的样本少于 个,则损失函数将处理大量的虚假填充表示。
后者是对比学习的一个问题,因为损失计算的时间和内存复杂度约为 O(n²)。为了避免这个问题,我们使用了分块对比损失,它通过在局部设备子集上进行计算并高效地积累全局 softmax 归一化所需的统计信息,从而避免了收集所有数据点进行 softmax 运算的需要。这使得 值可以很高(从而有效地利用模型编码器),而不会受到损失函数的限制。