BookRAG: A Hierarchical Structure-aware Index-based Approach
论文链接:https://arxiv.org/pdf/2512.03413
代码链接:https://github.com/sam234990/BookRAG
摘要
作为一种提升大语言模型(LLM)在问答(QA)任务中性能的有效方法,检索增强生成(RAG)通过从外部复杂文档中查询高度相关信息,引起了业界和学术界的广泛关注。然而,现有的RAG方法通常侧重于通用文档,忽略了许多现实世界文档(例如书籍、小册子、手册等)具有层级结构这一事实。这些层级结构从不同的粒度级别组织内容,导致其在问答任务中的性能不佳。为了解决这些局限性,我们提出了BookRAG,一种针对具有层级结构的文档的新型 RAG 方法。该方法利用逻辑层级结构并追踪实体关系来查询高度相关信息。具体而言,我们构建了一种名为 BookIndex 的新型索引结构。该索引结构通过从文档中提取层级树(作为文档的目录)来构建,并使用图来捕获实体之间错综复杂的关系,并将实体映射到树节点。利用 BookIndex,我们提出了一种受信息觅食理论启发的基于 Agent 的查询方法,该方法能够动态地对查询进行分类,并采用定制化的检索工作流程。在三个广泛应用的基准数据集上进行的大量实验表明,BookRAG 达到了目前最先进的性能,在检索召回率和 QA 准确率方面均显著优于基线方法,同时保持了具有竞争力的效率。
1.介绍
诸如 Qwen 3 和 Gemini 2.5 等型语言模型 (LLM) 彻底改变了问答 (QA) 系统。业界越来越多地采用 LLM 构建 QA 系统,以帮助用户并减少许多应用领域的人工工作量,例如财务审计、法律合规和科学发现。然而,直接依赖 LLM 可能会导致领域知识缺失,并生成过时或缺乏依据的信息。为了解决这些问题,检索增强生成 (RAG) 技术得到了广泛应用,它通过从外部来源检索相关的领域知识,并利用这些知识来指导 LLM 生成答案。另一方面,在实际的企业场景中,领域知识通常存储在长篇文档中,例如技术手册、API 参考手册和操作指南。此类文档的一个显著特点是它们遵循书籍的结构,具有复杂的布局和严谨的逻辑层次结构(例如,明确的目录、嵌套章节和多级节)。本文旨在设计一种有效的 RAG 系统,用于对篇幅较长、结构高度复杂的文档进行问答。
Prior works。现有的文档级问答(QA)的 RAG 方法通常分为两大类,如图1所示。第一类方法依赖于OCR(光学字符识别)将文档转换为纯文本,之后可以直接应用任何基于文本的 RAG 方法。在基于文本的 RAG 方法中,最先进的方法越来越多地采用基于图的 RAG,其中图数据作为外部知识源,因为它能够捕获丰富的语义信息和实体间的关系结构。如表1所示,GraphRAG 和 RAPTOR 是两种具有代表性的方法。具体来说,GraphRAG 首先从文本语料库构建知识图谱(KG),然后应用 Leiden 社群检测算法获得层次聚类。最后,为每个社群生成摘要,从而提供对整个语料库的全面、全局的概览。 RAPTOR 通过迭代地对文档块进行聚类,并在每个级别对其进行总结,构建递归树结构,使模型能够捕获语料库中细粒度和高层次的语义信息。
相比之下,第二种范式——布局感知分割(layout-aware segmentation),首先将文档解析成结构化的数据块,这些数据块保留了文档的原始布局和信息,例如段落、表格、图表或公式。这样做不仅避免了第一种范式中使用的固定块大小(这通常会导致信息碎片化),而且还保留了文档固有的结构信息。这些数据块通常具有多模态特征,一种典型的方法是应用多模态检索来获取与查询相关的内容。最近,该领域的一种先进方法 DocETL 提供了一个声明式接口,允许用户手动定义基于 LLM 的处理流程来分析检索到的数据块。这些流程由 LLM 驱动的操作和特定任务的优化组成。
Limitations of existing works。然而,这些方法存在两个根本性的局限性(简称 L):L1:无法捕捉文档结构和语义之间的深层联系。基于文本的方法无法捕捉文档的结构布局,导致存储在层级块中的重要关系丢失,例如嵌套在特定章节中的表格。虽然布局分段方法能够保留文档结构,但它们无法捕捉文档中不同块之间的关系,这限制了它们跨块进行多跳推理的能力,并最终影响其整体性能。L2:查询工作流的静态性。在实际的问答场景中,用户查询具有高度的异质性,从简单的关键词查找到需要整合分散在文档不同部分的证据的复杂多跳问题,不一而足。对不同的需求应用统一的策略(例如静态或手动预定义的工作流)效率低下;例如,复杂的查询通常需要问题分解,而简单的查询则不需要。
Our technical contributions。为了弥合这一差距,我们提出了 BookRAG,这是首个基于文档原生 BookIndex 的检索增强生成方法,旨在用于文档问答任务。具体而言,为了捕捉文档中关系的深层联系,BookIndex 通过两种互补的结构组织信息。首先,为了保留文档的原生逻辑层次结构,我们将解析后的内容块组织成一个层次树状结构,作为文档的目录。其次,为了捕捉这些内容块内部的复杂关系,我们构建了一个包含细粒度实体的知识图谱 (KG)。最后,我们将知识图谱实体映射到它们对应的树节点,从而统一了这两种结构。
然而,图上有效的多跳推理依赖于高质量的知识图谱,而知识图谱的质量常常受到实体歧义的影响(例如,名称不同的实体,如“LLM”和“大语言模型”)。为了解决这个问题,我们提出了一种新的基于梯度的实体解析方法,该方法分析候选实体的相似度分布。通过识别相似度得分的急剧下降,我们可以有效地区分和合并指称相同的实体,从而确保图的连通性并增强推理能力(L1)。
基于 BookIndex,我们通过实现基于 Agent 的检索来解决查询工作流的静态性问题(L2)。具体来说,我们的 Agent 首先根据用户查询的意图和复杂性对其进行分类,然后动态生成定制的检索工作流。基于信息觅食理论,我们的检索过程模拟觅食行为,利用选择器通过信息气味缩小搜索范围,并利用推理器定位高度相关的证据。
我们对三个广泛应用的数据集进行了大量实验,以验证我们提出的 BookRAG 的有效性和效率,并将其与几个最先进的基线方法进行了比较。实验结果表明,在所有数据集上,BookRAG 在检索召回率和 QA 准确率方面均始终表现出优异的性能。此外,我们的详细分析验证了我们关键特征(例如高质量的知识图谱和基于 Agent 的检索机制)的重要贡献。
我们总结我们的贡献如下:
- 我们引入了 BookRAG,这是一种新的方法,它通过将文档布局块的层次树与存储细粒度实体关系的知识图谱相结合,构建文档原生的 BookIndex。
- 我们提出了一种受信息觅食理论启发的基于 Agent 的检索方法,该方法动态地对查询进行分类,并配置最优的检索工作流程,以在文档中查找高度相关的证据。
- 在多个基准测试上进行的大量实验表明,BookRAG 的性能显著优于现有基线,在解决复杂的文档 QA 任务方面达到了最先进的性能,同时保持了具有竞争力的效率。
Outline。我们在第 2 节回顾了相关工作。第 3 节介绍了问题描述、IFT 和 RAG 工作流程。第 4 节介绍了我们 BookIndex 的结构及其构建方法。第 5 节介绍了我们基于 Agent 的检索方法,详细阐述了 BookRAG 结构化执行过程中使用的查询分类和算子。我们在第 6 节展示了实验结果和详细分析,并在第 7 节总结全文。
2.相关工作
本节回顾了相关工作,包括文档分析中的 LLM 和现代代表性的 RAG 方法。
LLM in document analysis。近年来,LLM 的进步为利用 LLM 进行文档数据分析提供了契机。由于LLM强大的语义推理能力,越来越多的研究致力于将非结构化文档(例如HTML、PDF和原始文本)转换为结构化格式,例如关系表。例如,Evaporate 利用 LLM 合成提取代码,无需大量人工标注即可经济高效地将半结构化网页文档转换为结构化数据库。此外,一些基于 LLM 的文档分析系统也被提出,旨在为标准数据管道赋予语义理解能力。例如,LOTUS 通过语义算子扩展了关系模型,允许用户使用LLM赋能的谓词(例如filter、join)对非结构化文本语料库执行类似 SQL 的查询。类似地,DocETL 引入了一个智能体框架来优化复杂的信息提取任务。此外,另一项研究提出将文档页面视为图像,从而直接分析或解析文档,并保留关键的布局和视觉信息。
RAG approaches。RAG 已被证明在许多任务中表现出色,包括开放式问答、编程上下文、SQL 重写和数据清洗。最初的 RAG 技术依赖于从外部知识库检索与查询相关的上下文,以缓解 LLM 的“幻觉”。近年来,许多 RAG 方法采用图结构来组织文档中的信息和关系,从而提高了整体检索性能。更多详情,请参阅近期关于基于图的 RAG 方法的综述。此外,智能体 RAG 范式也得到了广泛的研究,它利用自主智能体动态地协调和优化 RAG 流程,从而显著提高了推理的鲁棒性和生成保真度。
3.Preliminaries
本节将复杂文档 QA 的研究问题形式化,介绍基础信息觅食理论(IFT),并简要回顾 RAG 系统的一般工作流程。
3.1 Problem Formulation
我们研究复杂文档上的问答(QA)问题,旨在基于长文档回答用户查询。形式上,文档 表示为 个页面的序列 。这些页面包含一系列内容块 ,其中每个块 代表一个不同的元素(例如,文本片段、章节标题、表格或图像),这些元素按照章节逻辑层次结构组织。给定用户查询 ,目标是生成一个准确的答案 ,理想情况下,该答案应基于一组特定的证据块 。该任务被表述为开发一种方法 ,该方法将结构化文档和查询映射到最终答案:
其中 应该浏览顺序页面内容和 的逻辑层次结构,以综合出响应。
3.2 Information Foraging Theory
信息觅食理论(IFT)提供了一个框架,将信息获取过程比作动物觅食。该理论认为,用户会追踪被称为信息气味的线索(例如关键词或图标),在不同的内容集群(称为信息块,例如手册中的章节)之间导航。其目标是在最大程度获取有价值信息的同时,最大程度地减少付出,从而指导用户决定是继续留在当前信息块中,还是寻找新的信息块。
设想专家们正在一本大型技术手册中寻找特定问题的解决方案。他们首先提取与问题相关的关键词,这些关键词就像信息气味一样,引导他们找到一个或多个有价值的章节(信息块)。在这些信息块中,他们分析各种内容,提取出最终解答所需的精确知识。
3.3 RAG workflow
检索增强生成(RAG)系统通常采用两阶段框架。在离线索引阶段,非结构化语料库数据被组织成结构化索引,索引可以采用多种形式,例如向量数据库或知识图谱(KG)。随后,在在线检索阶段,系统根据用户查询 检索相关组件(例如文本块或子图),以指导 LLM 的生成。然而,这些通用工作流程通常将索引视为纯粹从内容中提取的结构,这可能会使其脱离文档的原始逻辑层次结构。相比之下,我们的方法旨在将这些检索结构与文档的原生树状拓扑结构深度整合。
4.BookIndex
本节介绍我们提出的 BookIndex,这是一个层级结构感知索引,旨在捕捉复杂文档中清晰的逻辑层级结构和错综复杂的实体关系。我们首先正式定义 BookIndex 的结构 (𝐵) 。随后,我们详细阐述其顺序的两阶段构建过程:(1) 树构建,解析文档布局以建立层级节点,每个节点按类型分类;(2) 图构建,从树节点中提取细粒度的实体知识,并通过一种新的基于梯度的实体解析方法对其进行细化。
4.1 Overview of BookIndex
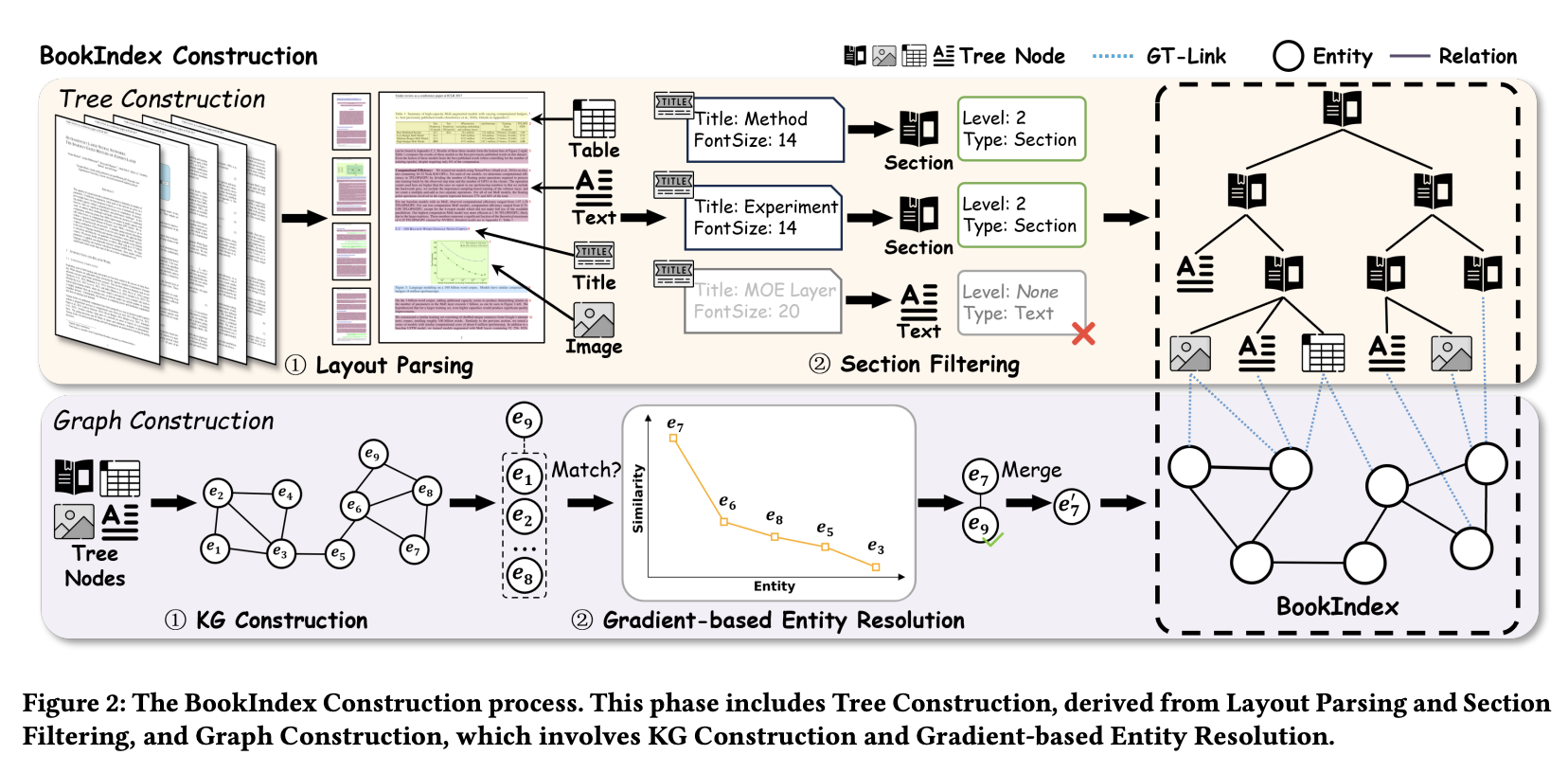
我们将 BookIndex 正式定义为三元组 。其中, 表示一个树状结构, 是从文档显式逻辑层次结构(例如,标题、章节、表格)中提取的节点集合, 表示它们的嵌套关系。 是一个知识图谱,它捕获了散布在文档中的细粒度实体 () 及其关系 ()。最后, 是图树链接 (GT-Link),它将 中的每个实体链接到 中从中提取该实体的特定树节点集合。这些链接对于捕捉文档中错综复杂的交叉关系至关重要。 中的层级树节点作为文档的原生信息块,为信息检索提供结构化的上下文。同时, 中的实体和关系通过 连接,如同丰富的信息线索,引导用户在这些信息块之间以及内部进行导航。
图 2 展示了我们的 BookIndex 示例。位于顶部的树状组件将文档组织成一个层级结构,其中文本、表格和图像等内容块作为叶节点嵌套在章节节点中。图状组件由从这些节点中提取的实体和关系组成。GT-Link(以蓝色虚线表示)将这些实体显式地连接回其对应的树状节点,从而将语义实体锚定在文档的逻辑层级结构中。
4.2 Tree Construction
第一阶段将原始文档转换为结构化的层次树 。这包括两个关键步骤:强大的布局解析和智能的章节过滤。
4.2.1 Layout Parsing。布局解析阶段使用布局分析和识别模型处理输入文档 (页面集合)。此步骤从文档页面中识别、提取和组织各种块(例如,文本、表格、图像)。输出是一个基本块序列 ,其中每个块 被定义为一个三元组。其中, 是原始内容(例如,文本、图像数据), 是初始的基于布局的类型(例如,标题、文本、表格、图像),而 是关联的布局特征向量(例如,“字体大小”、边界框)。
4.2.2 Section Filtering。接下来,章节过滤阶段处理此初始序列,以识别文档的逻辑层级结构。布局解析将块识别为标题,但不会分配其层级。因此,我们选择候选子集 (其中 )进行基于 LLM 的分析。为了处理极长的文档,此分析分批进行,每个批次保留一个包含高层章节信息的上下文窗口(以 为根节点)。LLM 分析候选子集的内容 和布局特征 ,以确定两个关键属性:它们的实际层级 和最终节点类型 (例如,如果 的层级为“无”,则将其重新分类为 )。这一步骤对于保持文档的逻辑层次结构至关重要,它可以纠正错误解析为标题的块,例如图像中的描述性文本或无边框表格标题。
最后,构建最终树 。节点集 由过滤和重分类过程中的所有块组成,其中每个节点 保留其内容 ( ) 和最终节点类型 ()(例如,文本、章节、表格和图像)。然后建立边集 ,表示父子嵌套关系。父子关系通过顺序遍历节点来推断,同时利用章节节点的确定层次级别 () 和文档的整体顺序来构建完整的树结构。
如图 2 所示,布局解析阶段识别出各种块,并将其类型标记为标题、文本、表格和图像。在章节过滤阶段,LLM 分析标题候选块(例如,“Method”、“Experiment”和“MOE Layer”)。“Method”和“Experiment”(字体大小均为 14)被正确识别为 “Level: 2” 的章节节点。相反,“MOE Layer”(字体大小为 20)被解析器错误地标记为标题,LLM 将其重新分类为“Level: None”的文本节点。此更正对于保持文档的逻辑层次结构至关重要。完成此过程后,所有过滤和分类的节点将根据其确定的级别和文档顺序组装成最终的树状结构。
4.3 Graph Construction

一旦树 建立起来,我们就可以通过从树节点中提取和提炼实体来填充知识图谱 。
4.3.1 KG Construction。我们遍历先前构建的树 中的每个节点 。对于每个节点 ,我们基于其内容 和最终节点类型 提取一个子图 。此提取过程依赖于模态类型:如果节点仅包含文本,则使用语言学习模型 (LLM) 提取实体和关系;而对于包含视觉元素的节点(例如,),则使用视觉语言模型 (VLM) 提取视觉知识。至关重要的是,对于提取的每个实体 ,都会记录其来源树节点 ,这对于构建最终映射 至关重要。
此外,为了保留特定逻辑类型(例如,表格、公式)的结构语义,我们的流程首先创建一个独立的、类型化的实体(例如,表示表格本身的 )。从该节点内容中提取的其他实体都链接到这个主节点。具体来说,对于表格节点,行标题和列标题也被显式地提取为独立的实体,并通过“包含于”关系链接到 。
4.3.2 Gradient-based Entity Resolution。正如文献所示,构建良好的知识图谱对于文档问答至关重要。提取过程中一个常见的挑战是,由于缩写、共指或在不同文档章节中出现频率不同,同一个概念实体常常被分割成多个不同的实体。这就需要一个强大的实体解析(ER)过程,来识别并合并这些碎片化的实体,从而完善原始知识图谱。
然而,传统的实体解析(ER)方法计算量巨大。它们通常设计用于跨多个数据源的批量处理(通常称为脏实体解析),旨在通过找到所有可能的匹配对来确保实体解析的准确性。这个过程通常需要找到所有检测到的匹配的传递闭包。也就是说,为了将多个实体(例如 A、B 和 C)明确地合并为同一个概念,理想情况下,系统必须比较所有可能的匹配对(“A-B”、“A-C”和“B-C”)以确认它们的等价性。这会导致成对比较的数量呈平方级(),当依赖 LLM 进行高精度判断时,这个过程会变得极其缓慢且计算量巨大。
为了解决这个问题,我们采用了一种基于梯度的实体关系(ER)方法,该方法针对单个文档(简化为干净的 ER)进行操作,并在提取每个新实体 时逐步执行 ER。这使得二次批处理问题转化为一个更简单的重复查找任务:确定单个新实体 在数据库中已处理实体中的位置。当将 与其 最相关的候选实体重新排序时,这种增量过程会产生两种截然不同的、可观察的评分模式:
- Case A: New Entity。如果 是一个新的概念实体,则它与所有现有实体的相关性得分将普遍较低,不显示明显的梯度或区分模式。
- Case B: Existing Entity。如果 是现有实体的别名,则其得分将显示与真实匹配项(或一小部分等效别名)高度相关。由于重排序器固有的判别能力局限性,这个初始的高相关性集合有时可能包含多个相似实体。随后,高相关性集合之后通常会出现急剧下降(较大的“梯度”),然后过渡到逐渐下降的不相关实体集合。
我们基于梯度的 ER 算法正是为了检测这种急剧下降(案例B的特征)而设计的,从而能够有效地分离出高相关性集合。随后,当在该集合中识别出多个相似实体时,我们会使用 LLM 进行更精细的区分,从而在不进行二次比较的情况下将其与“无梯度”情况(案例A)区分开来。
算法 1 展示了上述实体解析过程。对于一个新实体 ,我们首先从向量数据库 DB 中检索其 个候选实体 ,然后由重排序模型 对这些候选实体相对于 进行重新排序,并根据其得分 进行排序(第 1-3 行)。我们使用得分最高的候选实体 初始化选择集 Sel,并将初始得分设置为 (第 4 行)。然后,我们遍历剩余的已排序候选实体(第 5-8 行)。核心逻辑检查当前得分 是否仍在先前得分的梯度阈值 内(即,)。如果分数下降幅度较小(通过检查),则将候选实体 添加到 Sel 中,并更新分数(第 7-8 行);否则,一旦检测到分数急剧下降,循环即终止(第 8 行)。最后,算法做出决策(第 9-14 行)。如果选择集 Sel 与 完全相同,则表明所有候选实体都通过了梯度检查。这对应于情况 A,即分数缺乏区分能力(也就是说, 与所有候选实体的相似度相同),因此将 添加为新实体(第 9-10 行)。反之,如果发现梯度(即 ),则表明为情况 B。然后,我们从 Sel 中选择规范实体 ,如果重排序器识别出多个别名,则使用 LLM(第 13 行),并将 与其合并(第 12-14 行)。最后返回更新后的 和 DB(第 15 行)。
例如,以图 2 中的示例为例,当处理新实体 时,首先将其与知识图谱中已有的实体进行比较。如图中相似度曲线(橙色线)所示, 与 具有较高的相似度,随后与其他实体(如 、 和 )的相似度急剧下降。我们基于梯度的选择过程识别出 是 的唯一高置信度匹配项。因此, 与 合并,从而将整合后的信息添加到知识图谱中,最终合并后的实体为 。
Graph-Tree Link (GT-Link)。GT-Link 的形式化是为了完善 BookIndex 。如知识图谱构建阶段所述,对于每个新提取的实体 ,都会记录其源树节点 。GT-Link 随后在实体解析过程中得到完善:当实体 合并到规范实体 时, 的源节点集会更新,以包含所有先前与 关联的源节点。此聚合过程创建了最终映射 ,该映射将 中的实体与其在 中的结构位置(节点)集双向链接起来。
5.Agent-based Retrieval
现实世界中的文档查询通常十分复杂,需要进行模态类型过滤、语义选择和多跳推理等操作。为了解决这个问题,我们在 BookRAG 中提出了一种基于 Agent 的方法,该方法能够智能地规划和执行对 BookIndex 的操作。我们首先介绍整体工作流程,并阐述两个核心机制:基于 Agent 的规划(用于制定策略)和结构化执行(包括基于 IFT 和生成原则的检索过程)。
5.1 Overall Workflow
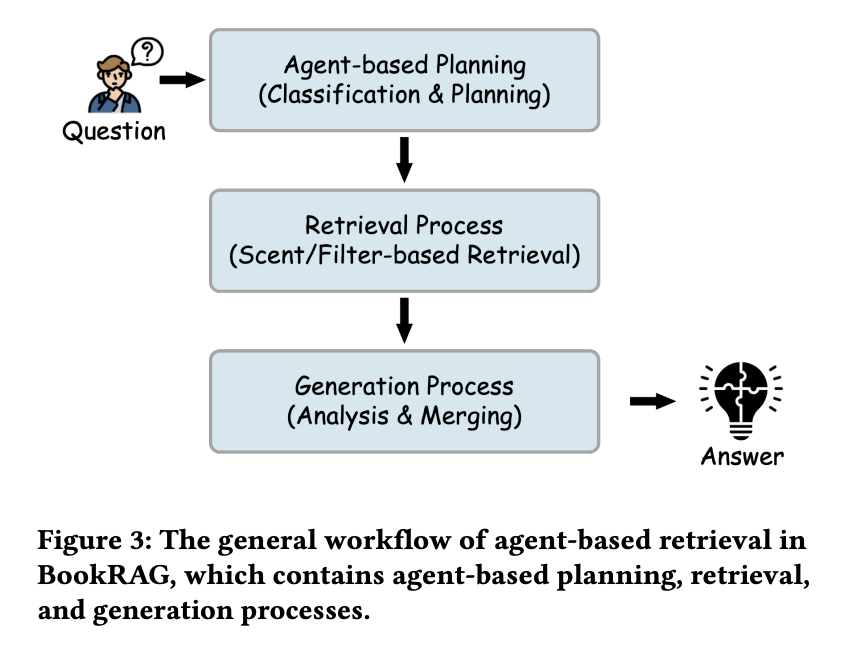
如图 3 所示,基于 Agent 的检索的整体工作流程遵循三阶段流程,旨在系统地解决用户的查询。
1. Agent-based Planning。BookRAG 首先执行分类与规划。此阶段旨在区分简单的基于关键词的查询和需要分解与分析的推理问题。例如,“Transformer 在处理长程依赖关系方面与 RNN 有何不同?”这样的查询无法通过单个关键词检索来解决。因此,规划阶段首先进行查询分类。基于此分类以及为 BookIndex 预定义的一组算子,它会生成一个具体的算子规划,从而有效地指导检索和生成策略。
2. Retrieval Process。在操作方案的指导下,检索过程执行基于气味/过滤器的检索。此阶段遍历 BookIndex ,利用基于气味的检索原则(例如,跟踪 中的相关实体)查找信息,或采用各种过滤器(例如,模态类型)来优化选择。经过推理后,BookRAG 从图书索引中获取高度相关的检索信息块集。
3. Generation Process。最后,所有检索到的信息进入分析与合并的生成阶段。该阶段会将这些(通常是零散的)证据进行综合,进行最终分析,并形成连贯的回应。
5.2 Agent-based Planning
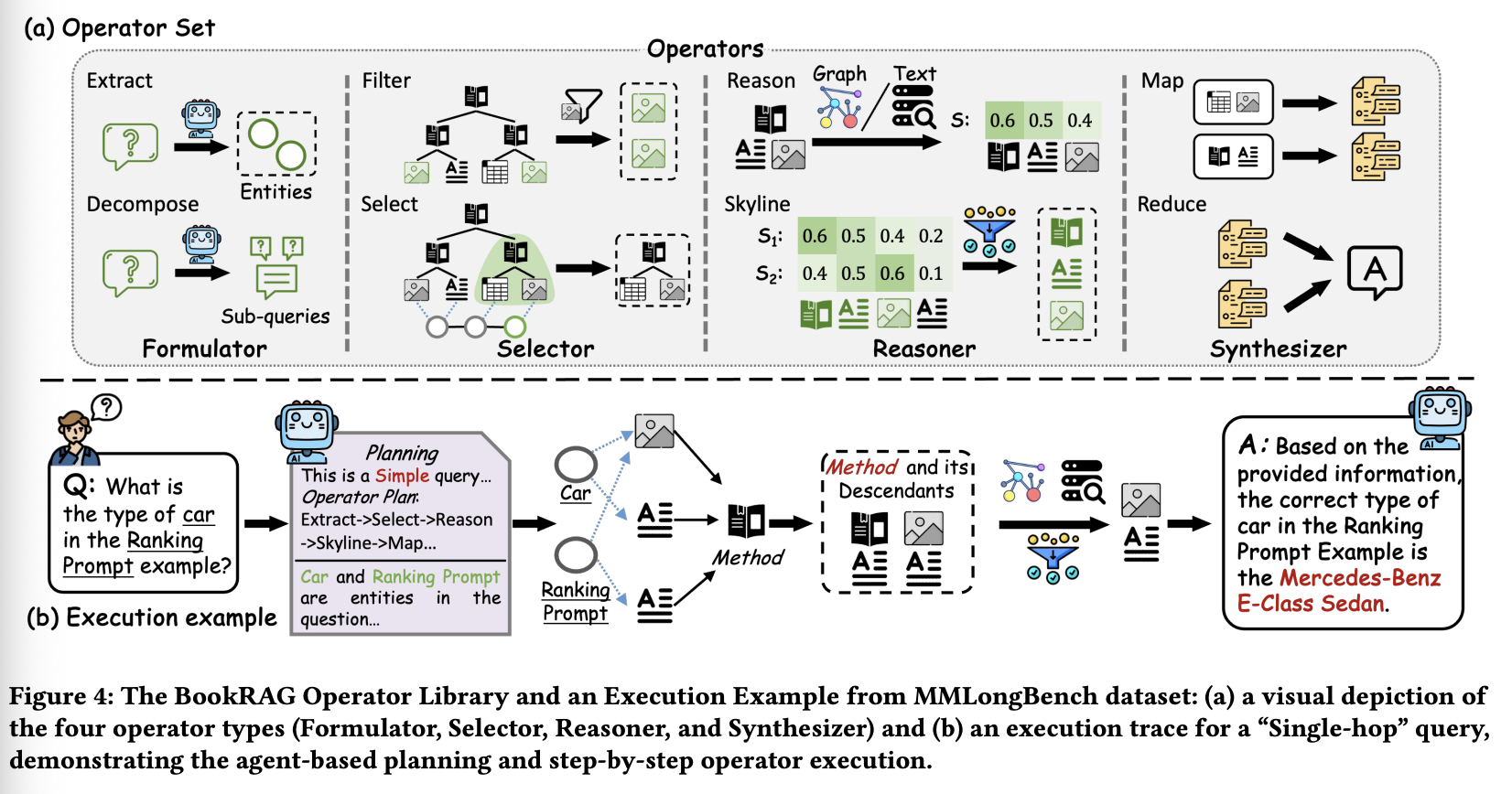
Planning 阶段是 BookRAG 的核心,旨在智能地导航我们的BookIndex 。为了支持灵活的检索,我们定义了四种类型的算子:公式生成器 (Formulator)、选择器 (Selector)、推理器 (Reasoner) 和合成器 (Synthesizer)。这些算子可以任意组合,形成定制的执行管道,每个管道都具有可调节的参数。BookRAG 会动态配置和组装这些算子,以适应不同类别查询的具体需求。此过程包含两个顺序步骤:首先,Agent 执行查询分类以确定合适的解决方案策略,然后生成特定的算子计划。
• Query Classification。为了实现 Agent 策略选择,我们重点关注三种具有代表性的查询类别,这些类别根据其固有的复杂性和操作需求进行定义(表 2):单跳查询、多跳查询和全局聚合查询。这种分类至关重要,因为每种类别都需要不同的解决方案策略。例如,单跳查询通常只需要通过基于气味的检索操作获取一条信息。相比之下,全局聚合查询通常需要在多种过滤条件下分析内容,通常涉及对文档不同部分进行一系列过滤和聚合操作。此外,BookRAG 的设计具有可扩展性,可以通过集成其他算子来处理更广泛的查询类型。
• BookIndex Operators。为了执行特定分类的策略,我们设计了一组针对BookIndex 的算子 ()。这些算子如图 4(a) 所示,并在表 3 中详细说明,它们定义了 Agent 可以针对不同查询类别执行的操作集。我们将它们分为四类,并按顺序进行描述:
❶ Fomulator。这些是基于 LLM 的操作符,用于准备要执行的查询。此类别包括 Decompose,它将复杂查询分解为一组更简单、可操作的子查询 。它还包括 ,它使用 LLM 从查询文本中识别关键实体 ,并将它们链接到知识图谱 中的相应实体。
这里, 是原始用户查询,而 和 分别表示用于指导 LLM 进行分解和提取任务的提示。
❷ Selector。该算子从 BookIndex 中筛选或选择特定的内容范围。 和 直接应用在计划过程中生成的显式约束 (例如,模态类型、页面范围)。这些算子作用于树 ,生成一个过滤后的子集 ,其中谓词 对每个节点都成立:
相比之下, 和 通过检索以特定章节节点为根的子树来定位连续的文档片段。此过程首先在指定深度识别一组目标章节节点 ,其中 由通过 GT-Link 链接到实体 或由 LLM 选择的章节组成。然后,它检索这些目标的所有后代节点,以形成选定的节点集 :
❸ Reasoner。该算子分析并优化选定的树节点。 从实体 开始,对从选定节点 提取的子图 执行多跳推理。从检索到的实体出发,它使用 PageRank 算法计算子图 上的实体重要性向量 。然后,这些实体得分通过 GT-Link 矩阵 映射到树节点,从而导出最终的树节点重要性得分向量 。
评估树节点内容与查询 的语义相关性,并为每个节点分配一个相关性得分 。 使用 Skyline 算子,根据这些多个标准(例如 和 )过滤节点,仅保留在指定评分维度上不被任何其他节点支配的节点。
❹ Synthesizer。该算子负责内容生成。 算子对检索到的特定信息片段进行分析,生成部分答案。 算子通过聚合来自多个来源的信息(例如部分答案或检索到的证据集合),综合生成最终连贯的答案。
• Operator Plan。在将查询 () 分类到其类别 () 之后,Agent 的最终任务是生成一个可执行计划 。该计划是一个特定的算子序列 ,这些算子选自我们的算子库 ,其参数根据 动态实例化。该过程可表述如下:
该计划遵循针对每个类别量身定制的结构化工作流程:



5.3 Structured Execution
在规划阶段之后,BookRAG 执行生成的流程 。此执行阶段体现了信息觅食理论 (IFT) 的认知原则,有效地将抽象的文本查询转化为具体的操作。具体来说, 算子模拟了“导航到信息块”的行为,将庞大的文档空间缩小到相关的范围。随后, 算子执行“块内意义构建”,分析并提炼这些聚焦范围内的信息。最后, 基于处理后的证据生成答案。这种设计通过确保计算资源仅集中于高价值的数据块,最大限度地降低了注意力成本。
Scent/Filter-based Retrieval。执行过程首先缩小范围。与信息流理论 (IFT) 一致, 算子通过追踪“信息气味”(例如,问题中的关键实体)或应用显式过滤器约束来识别相关的“补丁”。此过程将完整的节点集 缩小到聚焦的节点子集 :
这种预选过程最大限度地减少了噪声,并确保后续推理仅应用于高度相关的上下文,从而优化了搜索成本。随后,在这一聚焦范围内,推理器算子使用多个维度(例如图拓扑结构和语义相关性)评估节点。然后,我们使用 来获得最终的检索集。与固定的 top-k 检索不同,Skyline 算子保留了节点的帕累托前沿,保留了至少在一个维度上有价值的节点,同时舍弃了被支配的节点:
Analysis & Merging Generation。在最后阶段, 算子通过汇总精炼后的证据生成连贯的答案:
算子对单个证据块或子问题(来自 Decompose)进行细粒度分析,生成中间结果。 算子随后聚合这些部分结果,例如分解后的子查询的答案或来自全局过滤器的统计计数,以构建最终响应。这种分离确保系统能够有效地处理详细的内容提取和高层次的推理合成。
为了说明这一端到端流程,图 4(b) 展示了一个“单跳”查询的执行轨迹:“排名提示示例中的汽车类型是什么?”。在规划阶段,Agent 对查询进行分类并生成特定的工作流。随后,它通过 识别关键实体(例如,“汽车”),通过 检索相关节点,通过推理和 过滤对其进行细化,最后使用 合成答案。
6.Experiments