WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent
论文链接:https://arxiv.org/pdf/2508.05748
代码链接:https://github.com/Alibaba-NLP/WebAgent
摘要
诸如 Deep Research 之类的网络 Agent 已展现出超越人类的认知能力,能够解决极具挑战性的信息搜索问题。然而,大多数研究仍然主要以文本为中心,忽视了现实世界中的视觉信息。这使得多模态 Deep Research 极具挑战性,因为与基于文本的 Agent 相比,此类 Agent 需要在感知、逻辑、知识以及使用更复杂工具方面拥有更强大的推理能力。为了突破这一限制,我们推出了 WebWatcher,一个用于 Deep Research 的多模态 Agent,它配备了增强的视觉语言推理能力。它利用高质量的合成多模态轨迹进行高效的冷启动训练,利用各种工具进行深度推理,并通过强化学习进一步增强泛化能力。为了更好地评估多模态 Agent 的能力,我们提出了 BrowseComp-VL,这是一个类似 BrowseComp 的基准测试,需要进行涉及视觉和文本信息的复杂信息检索。实验结果表明,WebWatcher 在四个具有挑战性的 VQA 基准测试中显著优于专有基线、RAG 工作流和开源 Agent,这为解决复杂的多模态信息搜索任务铺平了道路。
1.介绍
Deep Research Agent 代表着人工智能 (AI) 领域的一个新前沿。大语言模型 (LLM) 超越了静态提示,能够规划多步骤任务:发出搜索查询、阅读文档、浏览网页,并通过迭代推理优化答案。许多用于 Deep Research 的开源纯文本网页 Agent 已展现出超越人类的能力,能够与复杂的信息环境进行交互,并在 BrowseComp 和人类的最后考试 (HLE) 等高难度基准测试中取得了卓越的表现。然而,迄今为止的大多数进展仍然主要以文本为中心,忽略了现实世界场景中无处不在的丰富视觉信息。许多以研究为中心的日常任务,例如解读科学图表、分析图形或浏览视觉丰富的网页界面,都需要集成的视觉语言推理。虽然专有 Agent 已在该领域取得了长足进步,但多模态 Deep Research 仍未得到广泛探索,很少有 Agent 能够应对高难度的视觉语言 (VL) 任务。
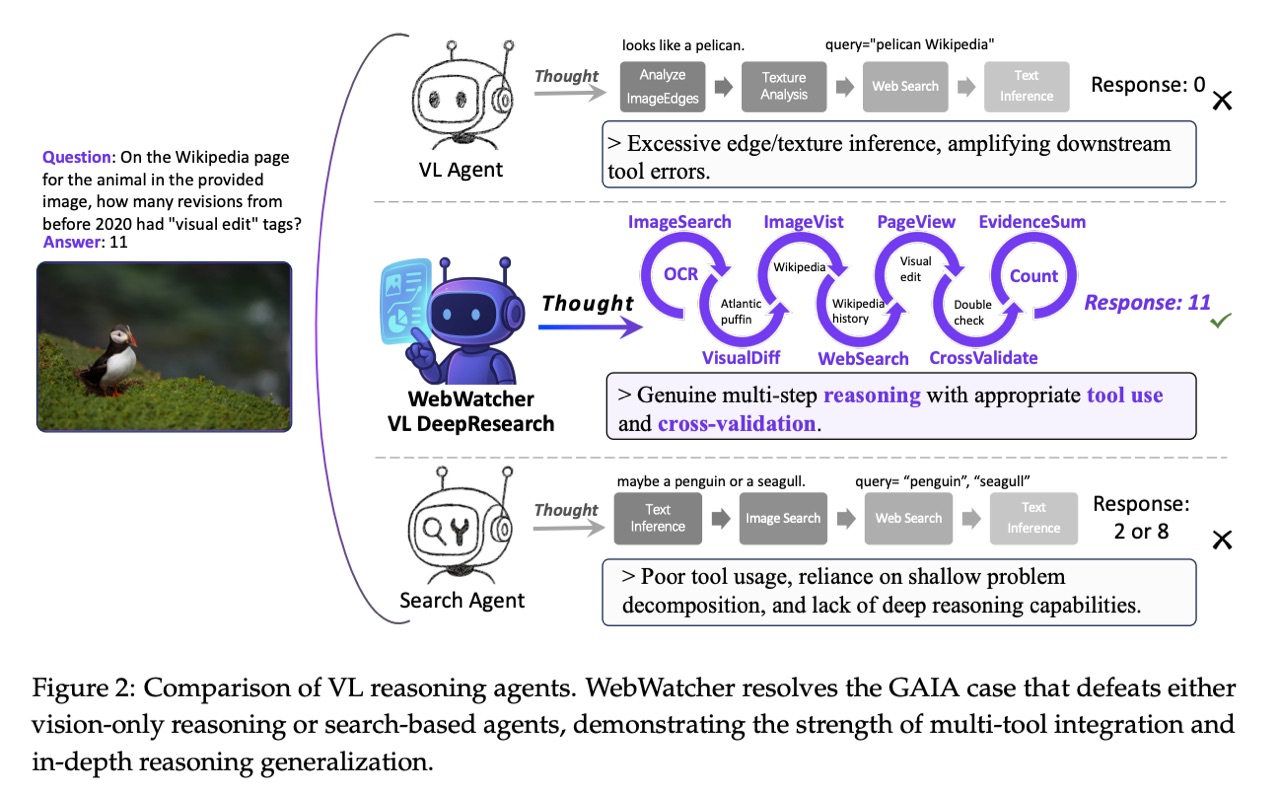
关键挑战在于,当前的多模态 Deep Research Agent 依赖于僵化的、模板驱动的流程,局限于特定场景,缺乏应对实际研究挑战所需的灵活推理能力。一方面,许多现有的视觉学习 Agent 主要依赖视觉工具进行基于图像的推理,例如光学字符识别 (OCR)、边界框提取、图像裁剪、视觉标注等。虽然视觉工具能够帮助 Agent 处理感知任务,但它们难以将视觉推理与深度文本理解和跨模态推理相结合,在处理需要复杂推理的高难度任务时显得力不从心。如图 2 所示,当面对来自 GAIA 的一个高难度案例时,单纯的视觉分析无法给出解决方案,这凸显了视觉学习 Agent 仍然局限于感知任务。另一方面,仅仅使用搜索工具将搜索 Agent 限制在检索任务上,并阻止它们解决复杂的现实世界任务。虽然检索增强推理可以处理许多基于知识的问题,但当答案隐含、需要结构化交互或需要额外计算时,它往往会失效。例如,有些问题需要执行代码来解释图表、进行分步计算,或浏览动态网页以提取最新或结构化内容。如图 2 所示,解决这种情况不仅需要搜索,还需要工具来点击相关链接并浏览生成的网页以收集必要的信息。
为了弥补这一差距,用于视觉学习 (VL) 的 Deep Research Agent 不仅需要具备强大的文本和视觉信息推理能力,还需要能够有效利用多种外部工具。因此,我们推出了 WebWatcher,一款具备 Deep Research 能力的视觉学习 (VL) Web Agent。
为了实现强大的文本和视觉信息推理能力,构建将高质量视觉内容与复杂推理相结合的数据至关重要。然而,目前大多数视觉问答 (VQA) 数据主要侧重于单步推理的视觉感知,缺乏支持高级 Agent 能力所需的规划复杂度和推理深度。因此,我们引入了一种 pipline 来生成有利于深入、多步推理和战略规划的训练数据,鼓励 Agent 综合两种模态的信息。重要的是,我们首先通过随机游走于各种网络资源来收集现实世界的知识,构建具有不可预测的多跳推理链的高难度问答 (QA) 示例,这与 BrowseComp 任务的信息搜索和组合特性非常相似。为了进一步提高复杂性,我们屏蔽了问题中的关键实体,用通用描述替换特定术语,迫使模型根据上下文推断关系。接下来,我们使用与大多数现有 QA 数据集兼容的自适应 QA-VQA 流程,将这些丰富的 QA 对转换为多模态 VQA 项目,从而实现多模态数据集的大规模扩展。最后,多阶段过滤过程确保生成数据的质量和清晰度。
此外,为了有效利用多种外部工具,我们首先实现了多种工具的集成,包括 Web 图像搜索、Web 文本搜索、网页访问、代码解释器和内部 OCR。然而,关键挑战在于获取高质量的推理轨迹。首先,最近的推理 Agent 生成的轨迹通常很长且模板化,多样性或跨任务适应性有限。其次,协调多个工具(每个工具都有不同的输入输出格式和推理角色)使得轨迹构建更加复杂。为了解决这个问题,我们开发了一个全自动流程,使用提示功能从 action-observation 序列构建推理轨迹。与手工制作的 CoT 式轨迹或基于模板的推理不同,我们的轨迹基于实际的工具使用行为,并反映了与复杂推理需求相一致的程序性决策。我们还将基于 LLM 的提示与基于规则的过滤相结合,以确保高质量。然后,我们使用反映跨工具深度推理的合成高质量轨迹对 Agent 模型进行微调,并通过强化学习算法 GRPO 进一步优化它。
最后,我们引入了一个颇具挑战性的 VQA 基准测试 BrowseComp-VL。它与 BrowseComp 的复杂性相似,但将其扩展到视觉领域,强调需要感知和超人信息收集能力的挑战。查询语句很长,采用 BrowseComp 风格,并经过实体混淆处理,要求 Agent 执行跨模态推理、彻底的信息搜索和高级规划才能解决。仅有感知是不够的。Agent 需要使用外部工具(例如网页搜索、图像检索和网页浏览)来收集和整合证据。
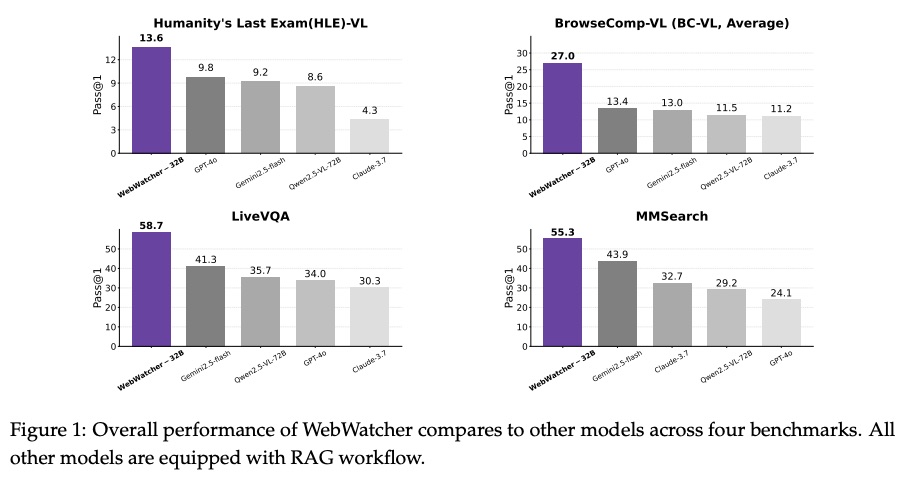
如图 1 所示,WebWatcher 在多个高难度基准测试(包括 HLE、LiveVQA、BrowseComp-VL 和 MMSearch)上均取得了优异的性能。它在四个推理基准测试中始终优于现有的开源多模态研究 Agent 和专有系统,并在感知基准测试 SimpleVQA 上表现出色。
2.Data Preparation
在本节中,我们介绍了我们的数据集构建方法,强调高质量数据、多步骤多模态推理以及与基于 Web 的 Agent 范式的强大兼容性。
2.1 Dataset Overview and Structure
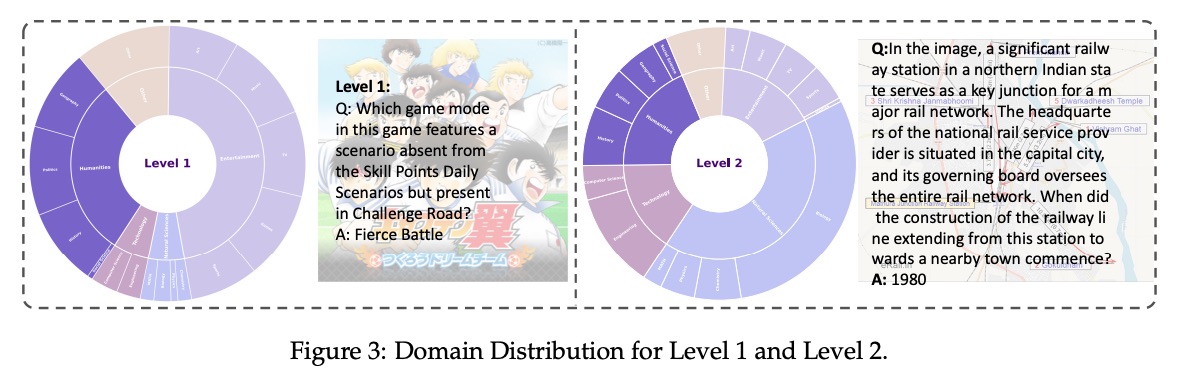
我们的数据集 BrowseComp-VL 专为在真实网络环境中运行的高级多模态推理 Agent 而设计。每个示例包含一张真实图像、一个需要跨模态推理的相关问题,以及关于底层实体和关系的辅助元数据。如图 3 所示,BrowseComp-VL 分为 5 个主要领域,包含 17 个细粒度的子领域,详见附录 B。主要领域包括娱乐、人文、科技、自然科学和其他。此外,我们定义了两个难度级别,以鼓励不同层次的推理能力:
- Level 1:问题需要多跳推理,但仍需参考明确的实体。虽然答案可以通过迭代检索步骤获得,但由于需要整合跨多个来源的信息,推理过程仍然十分复杂。
- Level 2:问题由故意模糊或模糊化的实体和属性构成。例如,具体日期被替换为模糊的句号,姓名被遮蔽,定量属性也被模糊化。这种设计引入了相当大的不确定性,要求 Agent 规划、比较和综合信息,而不是直接检索。
提示 LLM 直接从图像生成 VQA 问题是一种常见做法,但它通常会生成浅显的单跳查询,缺乏歧义性、结构化规划和更深层次的推理。此外,大多数现有的 VQA 数据集侧重于感知,很少将丰富的文本信息与知识密集型、多步骤推理相结合。为了解决这一限制,我们首先构建了一组多样化的、具有挑战性的文本 QA 对,专注于多跳推理和知识密集型问题。然后,我们将它们转化为 VQA 任务,并将它们与相关的视觉内容相结合。该流程生成了高质量的多模态数据,同时保持了视觉丰富度和文本推理的复杂性。
2.2 VQA Pairs Construction
2.2.1 Generate QA
Level 1。受 WebDancer 的 CRAWL-QA 启发,我们通过从权威且知识丰富的来源(例如 arXiv、GitHub 和 Wikipedia)收集根 URL 来提升推理的深度和广度。为了模拟类似人类的浏览行为,我们递归遍历每个根域内可访问的超链接。然后,我们使用 GPT-4o 从聚合内容中合成问答对。
Level 2。参照 WebSailor 的方法,我们通过用部分模糊描述替换精确引用来构建模糊实体查询。我们的方法重点关注那些无法通过直接查找获取答案,而是需要跨模态进行上下文推理和综合的情况。
我们设计了一个两阶段生成框架,包括:
- Nodes Selecting:给定一个初始维基百科页面,我们首先提示 GPT-4o 生成一个基于页面内容的基础问答对。页面标题作为根实体节点 。从 出发,我们通过遍历外部链接递归扩展超链接图,构建一个深度为 、分支因子为 的树,最终在整个遍历过程中总共有 个节点。在我们的实现中,我们设置 和 ,以确保足够的语义覆盖。 为了生成多样化的推理路径,我们从整棵树中采样多个子图。我们随机选择一个节点子集,并不断扩展,直到形成一个包含 个实体的子图。每个子图定义了一条从 到新选定的目标实体 的唯一推理路径,从而形成一个编码多跳关系的知识图谱。这些子图是生成不同问答对的基础。
- Query Generating:基于选定的子图和基本事实,我们首先提示 GPT-4o 生成一个标准形式,明确引用推理路径上的实体和关系。然后,将其转换为模糊版本,其中关键引用被替换为部分、模糊或定性的描述。这种设计鼓励多样化的推理模式,促使模型通过综合而非表面匹配来推断答案。
2.2.2 QA-to-VQA Conversion
Visual Context Construction for VQA。为了确保有效的视觉基础,我们首先滤除琐碎或过于模糊的目标实体 ,例如那些表示时间指称或领域外部概念的实体,这些实体缺乏足够的视觉基础。对于每个保留的实体 ,我们通过 Google SerpApi 检索一组网络图像 ,其中在我们的实现中 。生成的图像 作为构建多模态推理示例的视觉基础。与现有 VQA 基准中普遍存在的合成或合成图像不同,我们的图像严格真实,从而最大限度地减少了噪声并最大限度地提高了与现实世界任务的相关性。
Entity Masking and Question Transformation。为了从每个文本问答实例 构建基于图像的 VQA 对,我们使用 GPT-4o 进行基于提示的重写。令 表示包含明确提及目标实体 的原始文本问题。我们使用视觉参考 token (例如指示词(“这个实体”)或描述性短语(“图像中的物体”))对此提及进行掩蔽,以生成转换后的 VQA 查询 。同时,我们生成图像查询字符串 来指导 的过滤。然后将每个图像 与 配对,形成一个不同的 VQA 实例。因此,每个文本问答对都会生成 个多模态示例,从而从 n 个原始问题中生成总共 Kn 个 VQA 项。
2.3 Quality Control
为了确保 VQA 样本的高质量,我们采用了包括 Selector 和 Examiner 在内的三阶段过滤流程:
- Selector:首先,我们剔除转换后的 VQA 查询 与原始问题 相同的数据,并丢弃实体名称 或其别名明确出现在 中的情况,因为这些情况表明实体掩蔽或问题重写失败。其次,GPT-4o 会根据原始 QA 对 和转换后的 VQA 查询 评估每幅图像 。GPT-4o 会评估上下文对齐、语义契合度和视觉推理的合理性。相关性得分较低的实例将被过滤掉。
- Examiner:对于每个保留的图像查询对 ,GPT-4o 会被提示仅使用 的视觉内容和相关说明来回答合成查询 。如果回答不准确,则表明检索能力较弱或图像查询格式错误,因此此类查询 q 会被过滤掉。
此外,为了减轻因缺乏世界知识而产生的假阴性,模型在验证期间被授予访问可用图像标题的权限。
3.Trajectory Generation and Post-Training
我们使用监督微调 (SFT) 作为冷启动,基于自动化流程生成的高质量 ReAct 风格轨迹,教会 Agent 进行工具增强推理。然后,我们运用强化学习进一步优化工具使用和决策。
3.1 Automated Generation of Reasoning Trajectories
3.1.1 Multimodal Tools
我们为 WebWatcher 配备了一套外部工具,包括:(1)由 Google SerpApi 提供支持的 Web Image Search,用于检索相关图像、相应标题及其网页网址,以便更好地理解输入图像 ;(2)Web Text Search,用于开放域信息查找,检索查询的标题和网页网址;(3)来自 Jina 的访问,支持导航到特定 URL 获取网页摘要,并根据 LLM 操作中指定的“目标”进行定制;(4)Code Interpreter,支持符号计算和数值推理。(5)OCR,这是一个通过提示和 SFT 数据调用的内部工具,用于从输入图像中提取文本。完整的实现细节见附录 D。
3.1.2 Automated Trajectory Annotation
给定来自 BrowseComp-VL 的 VQA 实例 ,我们使用 GPT-4o 自动构建工具使用轨迹,模拟人类如何通过逐步尝试不同的工具来探索和推理问题。遵循 ReAct 的思路,每个轨迹 包含多个“思考-行动-观察”循环。具体而言,在每次迭代 中,语言模型将累积的上下文历史记录作为输入,并生成:
- Thought:Agent 的中间推理或计划,包含在 中;
- Action:工具调用包含在 中,最终答案包含在 中;
- Observation:环境返回的结果,位于 标签内。
动作空间 包括一组离散的工具使用动作 ,允许 Agent 检索外部信息、浏览网页和执行计算等。至关重要的是,完成动作通过返回最终答案并终止推理过程来表示任务完成。
形式上,长度为 的轨迹表示为:
其中每个动作 ,每个观测 反映了工具执行后的环境反馈。轨迹是基于内容的规划和工具选择的演示。
3.1.3 Trajectory Filtering and Quality Assurance
为了确保稳健且有指导性的监督,我们采用三阶段轨迹选择:
- Final Answer Matching。我们保留最终答案与真实答案 a 一致的轨迹 τ,确保整个工具使用步骤序列能够得到正确且完整的解决方案。
- Step-by-Step Consistency Check。我们使用 GPT-4o 来验证轨迹 中每个中间步骤的逻辑一致性。每一对 都会被审查,以确保工具调用与观察结果符合上下文和推理目标。包含幻觉内容、矛盾或无依据工具调用的轨迹会被舍弃。这避免了通过运气猜测而非有意义的工具使用得到正确答案的常见失败模式。
- Minimum Tool Usage Requirement。为了鼓励多步推理而非捷径,我们移除工具调用少于三次的轨迹 。这确保训练数据反映的是实质性、过程驱动的交互,而非琐碎或一步完成的结果。
3.2 Supervised Fine-Tuning as Cold Start
过滤后,得到的数据集由 条高质量工具使用轨迹组成。对于第 条轨迹中的第 步,WebWatcher 被训练来预测正确的工具使用动作 ,其条件是输入图像 、问题 ,以及所有先前的动作和观察结果 。如公式 (2) 所示,SFT 最大化目标动作 的对数似然:
其中 表示模型参数。
作为冷启动阶段,SFT 教会智能体有意义地使用工具,并遵循结构化的多步推理过程。
3.3 Reinforcement Learning
在 SFT 提供冷启动初始化的基础上,我们采用 Group-Relative Policy Optimization (GRPO),这是一种基于排序的 PPO 变体,用于进一步优化决策并适应复杂任务。具体而言,对于 VQA 查询 ,当前策略 生成一个由 条完整轨迹组成的集合 ,每条轨迹分配一个标量回报 。组相对优势在公式 (3) 中定义:
该方法在组内对奖励进行归一化,并消除了对单独价值函数的依赖。GRPO 目标定义为裁剪代理损失:
其中 是当前策略与先前策略之间的重要性采样比率, 是公式 (3) 定义的组相对优势, 是裁剪阈值, 表示相邻策略之间的 KL 散度。系数 控制 KL 惩罚的强度。该目标在促进稳定更新的同时,鼓励探索具有更高相对回报的轨迹。
每条轨迹 是一个包含 次工具调用的序列 。轨迹 首先接收一个二进制格式分数 ,若所有工具调用都符合预设模式,则取值为 1。之后,LLM 通过比较最终答案与真实答案,为轨迹提供一个语义准确度分数 。
总奖励 定义为:
其中 表示在格式分数 与准确性分数 之间的权重平衡。该设计鼓励智能体生成结构良好的工具调用,同时最终仍聚焦于任务完成。由于 只在每个 episode 结束时分配,因此公式 (3) 中的组相对归一化使得奖励分配更高效,避免了逐步塑形的依赖。
在我们的 GRPO 实现中,我们将 rollout 分组成 条轨迹,这为探索提供了足够的多样性,同时保持了有意义的相对优势,从而促进稳定的策略改进。