论文链接:https://arxiv.org/pdf/2509.13237
代码链接:
摘要
大语言模型 (LLM) 现在通过生成扩展的思维链来解决多步骤问题。在此过程中,它们通常会在给定的每个问题内重新推导相同的中间步骤,从而增加 token 使用量和延迟。上下文窗口的这种饱和会减少探索的能力。我们研究了一种简单的机制,该机制通过模型自身对先前轨迹的元认知分析,将重复的推理片段转换为简洁、可重复使用的“行为” (name + instruction)。这些行为存储在“行为手册”中,该手册在推理时将它们提供给上下文中的模型,或通过有监督微调将它们提炼为参数。这种方法在三种不同的设置中实现了改进的测试时推理 - 1)Behavior-conditioned inference:在推理上下文中提供 LLM 相关的行为可将推理 token 数量减少多达 46%,同时匹配或提高基线准确度; 2) Behavior-guided self-improvement:无需任何参数更新,模型即可利用自身过去解决问题尝试中的行为来改进其未来的推理能力。这比单纯的批判-修改基线模型的准确率高出 10%;3) Behavior-conditioned SFT:与 vanilla SFT 相比,基于行为条件化推理轨迹的 SFT 在将非推理模型转换为推理模型方面更为有效。总之,这些结果表明,将缓慢的推导转化为快速的过程提示,能够帮助 LLM 记住如何推理,而不仅仅是记住要得出什么结论。
1.介绍
通过生成长而深思熟虑的思维链,LLM 在数学、编程和其他多步骤任务方面取得了快速进展。然而,这种能力暴露出结构性低效:每个新问题都会触发无处不在的子程序的重构(例如,有限级数求和、大小写拆分、单位转换),从而增加 token 的使用量和延迟。例如,假设 LLM 在解决一个问题时推导出有限几何级数公式。当另一个问题需要类似的推理时,它能否避免从头开始重新推导?当前的推理循环缺乏一种机制,将频繁重新发现的模式转化为紧凑、可检索的形式。
我们引入了一种 metacognitive 路径,用于提取并重用这些模式。给定一个问题,模型首先求解它,然后反思其轨迹以识别可推广的步骤,最终生成一组行为——简短、可操作且具有规范名称的指令。这些行为构成了一个可搜索的手册(程序性记忆),可以在测试时结合上下文提供,也可以通过有监督微调将其内化。这提供了一个将冗长的推导转化为快速思考的框架。
与存储陈述性事实的典型记忆/检索增强生成 (RAG) 系统不同,这本手册针对的是有关如何思考的程序性知识。这种程序性记忆与大多数现有的 LLM 的“记忆”附加组件(包括 RAG)形成鲜明对比,后者针对的是诸如事实问答等任务的陈述性知识。它并非由精选文档或知识图谱组装而成,而是由模型本身生成。它源于模型自身的元认知循环:批判自身的思维链,并将重复的推理模式抽象为行为。
我们评估了所提框架的三个实例。(i)Behavior-conditioned inference:提供通过解决上下文问题获得的行为,导致推理链使用的 token 减少多达 46%,同时提高或保持 MATH 和 AIME 基准的强劲性能(ii)Behavior-guided self-improvement:在解决问题时,为模型提供对其自身从过去对该问题的尝试中提取的行为的访问权限,与简单的自我改进基线相比,准确率可提高多达 10%。(iii)Behavior-conditioned SFT:对基于行为条件推理生成的推理轨迹进行训练,可以产生比在普通轨迹上训练的模型更准确、更简洁的模型,尤其是在将非推理模型转变为推理模型时。
贡献:
- 我们将行为形式化为通过对解决方案轨迹进行元认知反思而发现的命名的、可重复使用的推理指令。
- 我们介绍了一种三步方法来使用 LLM 从其自身的推理轨迹中提取行为(第 3 节)。
- 我们开发了三种利用这些行为的设置:Behavior-conditioned inference、Behavior-guided self-improvement 和 Behavior-conditioned SFT。(第 4 节)
- 我们提供了基于行为的方法在三种环境中有效性的实证证据,并根据 MATH 和 AIME-24/25 等具有挑战性的数学基准进行了评估(第 5 节)。
- 我们讨论了所提出的框架的一些局限性和挑战——例如,在长解决方案中缺乏动态行为检索、使用超出数学的行为、构建跨各个领域的大规模行为手册等。
通过将频繁重复发现的步骤转化为简洁的程序,行为手册可以帮助 LLM 记住如何思考。这一简单的推理栈补充提高了 token 效率,并指明了一条构建随时间推移积累程序性知识的模型的途径。
1.1 Paper Outline
本文首先描述了行为管理的流程(第 3 节),然后介绍了利用行为改进推理的各种方法(第 4 节)。实验部分描述了相应的实验结果。第 5.1 节展示了在 MATH 和 AIME 数据集上进行行为条件推理的结果,结果表明,与普通推理相比,所提出的方法表现出相似或更高的性能,同时将 token 使用量减少了高达 46%。第 5.2 节介绍了自我改进实验,其中行为引导方法将行为作为可扩展自我改进的经验教训,与基线自我改进方法相比,在最高考虑 token 预算 16,384 的情况下,准确率提高了 10%。最后,SFT 实验(第 5.3 节)表明,与使用原始推理轨迹执行 SFT 相比,使用行为条件推理为 SFT 生成推理轨迹可以产生更强大的推理模型。
2.相关工作
Efficient Reasoning with LLMs。强化学习后的长格式思维链 (CoT) 提示使最近的 LLM 能够解决数学、逻辑和代码中的高度复杂问题。尽管 CoT 让模型“大声思考”几秒钟或几分钟,但越来越多的文献试图在保持准确性的同时缩短这些轨迹。Skeleton-of-Thought 方法首先起草一个大纲,然后并行扩展每个项目符号;TokenSkip 训练模型完全省略冗余 token;Dynasor 插入提前退出探测,一旦连续的探测就停止生成答案;MinD 将模型限制为跨越多个轮次的简洁单轨迹块。我们所提出的方法与效率目标相同,但在两个方面有所不同:(i)我们没有明确地训练模型变得简洁——在模型将重复的推理片段抽象为可重用的行为后,效率就会出现;(ii)这些行为也提高了解决方案的质量,如 SFT 实验(第 5.3 节)所示,其中对行为条件生成的轨迹的训练优于对长格式扩展思维链轨迹的训练。
Metacognitive abilities of LLMs。元认知是指人类“关于思考的思考”。Didolkar et al. (2024) 提出,LLM 中元认知的一个类似之处是从 LLM 的 CoT 中提取可复用的“技能”,并表明前沿 LLM 可以从任务数据集中提取有意义的技能目录。Shah et al. (2025) 的论文通过要求问题涉及技能组合,使用 LLM 提取的此类技能目录来创建更难的数学问题。Kaur et al. (2025) 对指令遵循技能也采取了类似的方法。He et al. (2025) 使用技能类别来研究较小语言模型中的上下文学习。我们工作的创新之处在于运用元认知思维来帮助推理模型处理更长、更复杂的推理轨迹。
Memory in LLMs。目前,LLM 的记忆实现主要依赖于模型可搜索的外部事实知识存储(例如维基百科)。检索增强生成在推理时从该事实记忆中提取段落,并根据证据条件调整解码器,以回答知识密集型问题。最近,检索已被直接融入多步推理中,ReAct 和 IR-CoT 等方法交织“思考→检索→思考”循环以减少幻觉。这些记忆实现主要存储与真实情况相关的陈述性知识,而非思考方式。程序性知识——通过重复获得的技能和惯例——在很大程度上仍未被探索。我们提出的行为手册是 LLM 此类程序性记忆的一个实例:它捕捉从重复推理模式中提炼出的操作策略,并将其存储起来以备将来重用。
3.Behaviors from Reasoning traces
推理型 LLM 会发出一条长的思维链(CoT),我们也将其称为推理轨迹。我们将行为定义为从 LLM 思维链中提炼出的可复用技能——一段简洁的知识。此类行为可以跨任务调用,从而使测试时推理更快、更准确。每个行为都表示为一个 (name, instruction) 对。例如:
本节的其余部分描述了从 LLM 生成的推理轨迹中推导行为的过程。
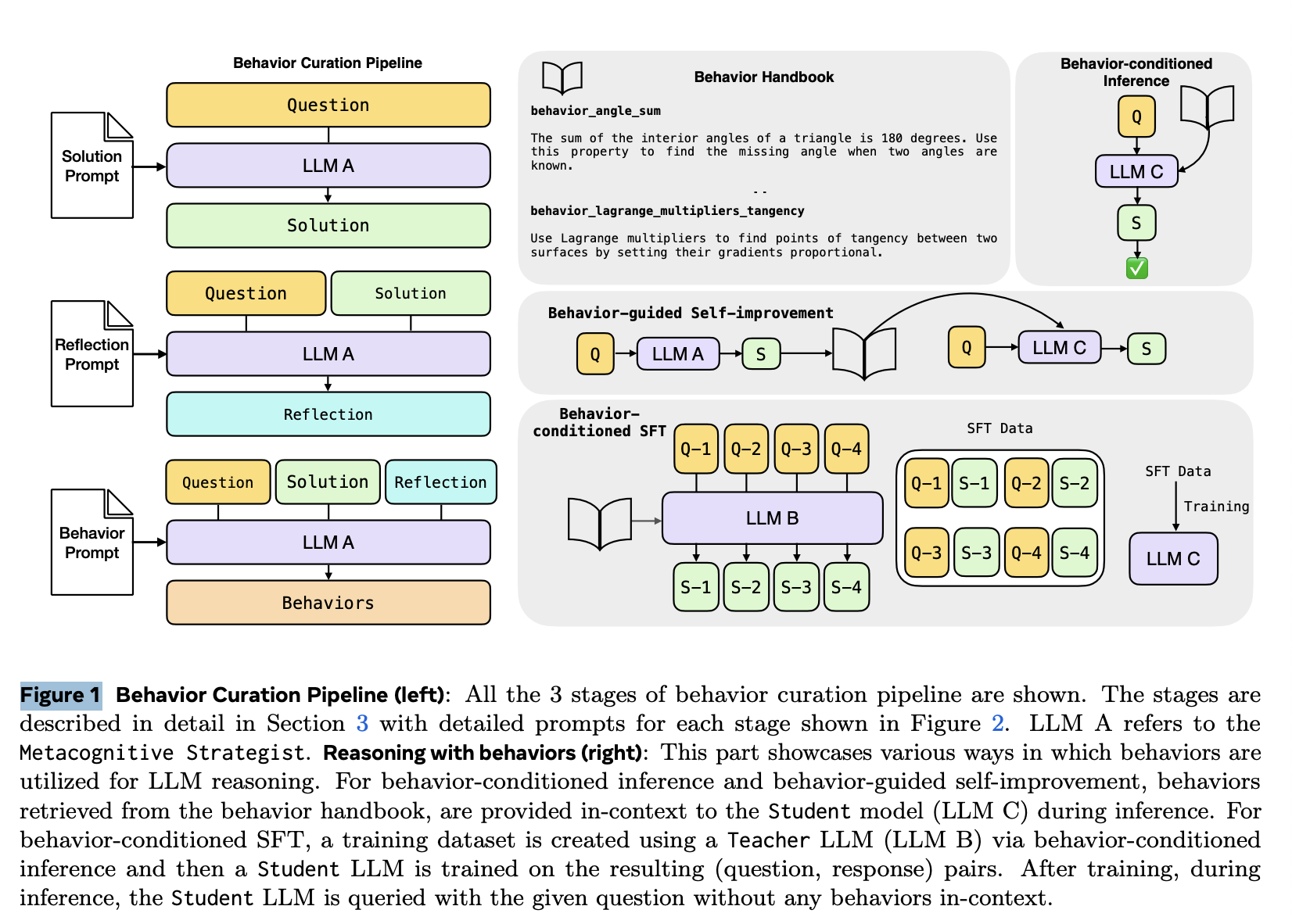
图 1 描绘了整个流程。该框架将 LLM 分为 3 个不同的角色:1)Metacognitive Strategist (LLM A),从自身的推理轨迹中提取行为;2)Teacher (LLM B),为 SFT 训练生成数据;3)Student (LLM C),其要么通过行为条件推理或行为条件 SFT 的辅助进行推理。我们将在以下章节中深入探讨每个角色。首先,我们来描述 Metacognitive Strategist 的工作原理。
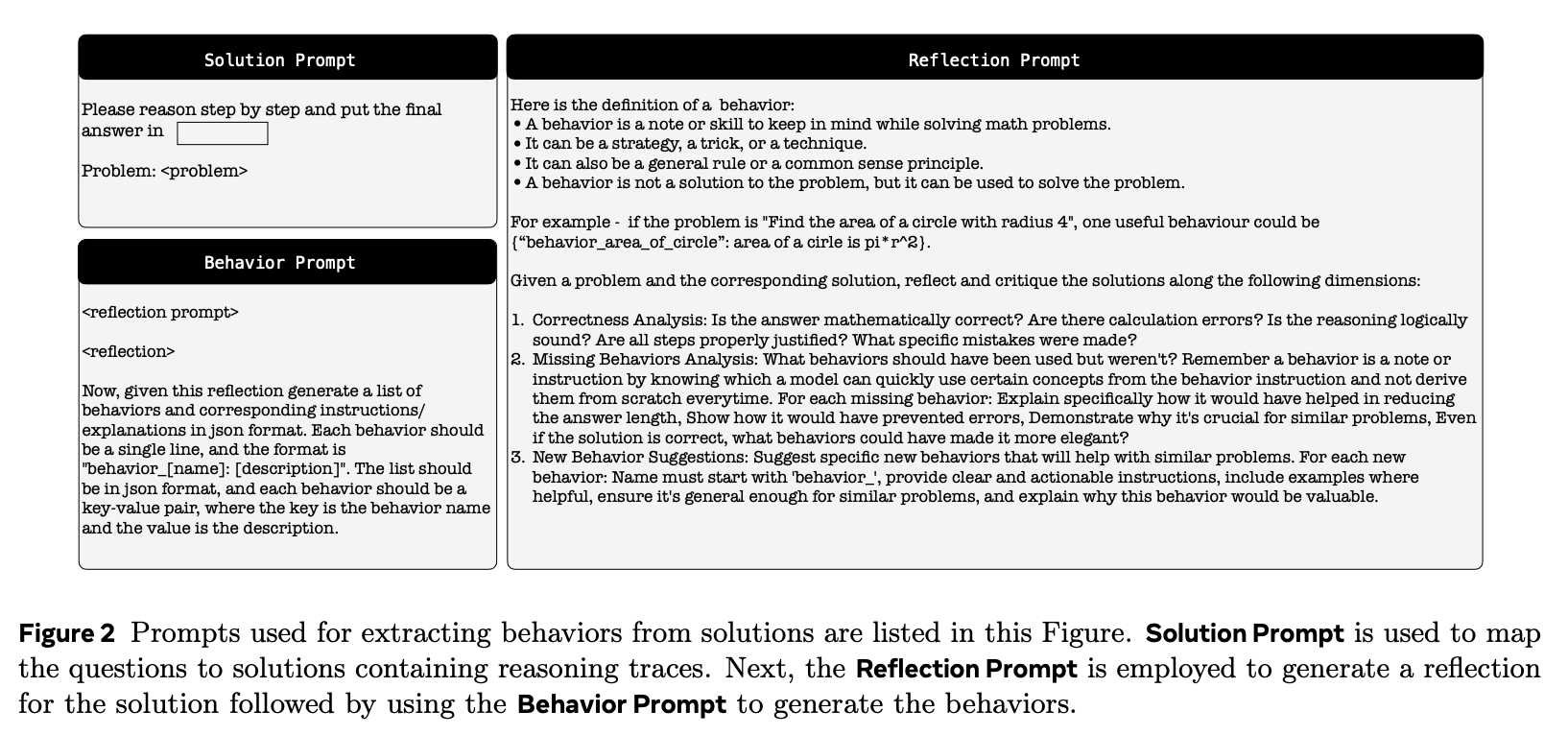
Extracting Behaviors。为了提取行为,Metacognitive Strategist 会针对给定问题生成一个解决方案,该解决方案包含推理轨迹和最终答案。此交互的提示如图 2 所示(解决方案提示)。然后,问题-解决方案组合再次输入 Metacognitive Strategist,以生成反思,评估推理是否逻辑合理、答案是否正确,以及是否可以提炼出任何新的可重复使用的行为以简化未来的问题解决(参见图 2 中的反思提示)。最后,通过另一个提示,Metacognitive Strategist 将问题、解决方案和反思转换为一组 (name, instruction) 行为,并将其附加到不断增长的行为手册中(参见图 2 中的行为提示)。图 1 中的行为手册面板展示了从 MATH 和 AIME-24 数据集 中提取的两个示例行为。
DeepSeek-R1-Distill-Llama-70B(R1-Llama-70B)被用作 Metacognitive Strategist。
4.Behavior-Guided Reasoning
本节讨论了利用行为手册进行可扩展和高效推理的各种方法。
4.1 Behavior-conditioned inference
利用这些行为的一个直接方法是,让 Student LLM 在推理过程中访问这些行为的上下文,如图 1 所示。我们称之为行为条件推理 (BCI)。给定一个问题 ,该方法首先从行为手册中检索相关行为 。然后将这些行为、其对应的指令以及问题输入 LLM,以生成解决方案。
图 3 中列出了用于 BCI 的具体提示。检索函数的形式取决于具体的用例,该函数用于从行为手册中检索给定问题的相关行为。例如,在 MATH 数据集中,检索函数基于主题匹配——对于给定主题的问题,检索该主题的行为。这对于 MATH 数据集来说是可行的,因为所有 训练集和测试集问题都用 7 个主题之一进行注释。因此,可以使用获取行为手册中行为的问题主题对其进行分类。其他数据集(例如 AIME–24, 25)无法进行此类检索。在这种情况下,基于嵌入的检索用于检索相关行为。对于给定问题,选择按嵌入空间中余弦相似度排序的前 K 个行为。有关此检索函数的更多详细信息,请参见第 5.1 节。有关每个实验所用检索函数的形式的更多信息,请参见第 5 节,并与相应的实验一起描述。
4.2 Behavior-guided self-improvement
自我提升是指给定模型改进自身推理能力的能力。为了实现这一点,模型会根据特定问题的推理轨迹,将行为反馈到上下文中,作为解决相同问题或新问题的经验教训或提示。其实现方式与 BCI 的实现方式紧密相关,并使用相同的提示。此过程如图 3 所示。 Student LLM 与 Metacognitive Strategist 相同。
4.3 Behavior-conditioned supervised fine-tuning
行为条件推理仍然需要检索步骤,并在测试时额外添加提示 token,以提醒模型应该使用哪些行为。我们通过基于 BCI 生成的数据对给定模型进行微调,将行为内化,从而消除了这种开销。我们称之为行为条件有监督微调 (BC-SFT)。Metacognitive Strategist 生成行为,teacher 使用 BCI 生成数据,student 则根据这些数据进行微调。具体流程如下:
- Metacognitive Strategist 使用第 3 节中的管道提取每个问题的行为,然后由 teacher 使用 BCI 为每个问题生成行为条件响应。
- student 模型根据结果 (question, behavior-conditioned response) 对进行微调。
该流程如图 1 所示,更多细节将在 5.3 节中阐述。student 模型不再需要行为提示;它会自发地调用已学习的行为。这种蒸馏设置将 teacher 刻意的、带有行为注释的推理转化为学生快速、直观、低 token 的响应。这种设置也使我们能够评估行为条件推理在为非推理模型赋予推理能力方面的有效性。