论文链接:https://huggingface.co/blog/gemma4
代码链接:
摘要
Google DeepMind 的 Gemma 4 系列多模态模型现已在 Hugging Face 上发布,支持您喜爱的各种智能体、推理引擎和微调库 🤗
这些模型堪称真材实料:采用 Apache 2 许可证,真正开源;拥有帕累托前沿竞技场评分,品质卓越;支持多模态(包括音频);并提供多种尺寸,可在各种设备上使用。Gemma 4 在前代产品的基础上进行了改进,并实现了各方面的无缝衔接。在我们使用预发布版本进行的测试中,Gemma 4 的强大功能给我们留下了深刻的印象,以至于我们很难找到合适的微调示例,因为它们开箱即用,性能已经非常出色。
我们与 Google 和社区合作,让这些工具无处不在:transformers、llama.cpp、MLX、WebGPU、Rust 等等,应有尽有。这篇博文将向您展示如何使用您最喜欢的工具进行构建,欢迎您分享您的想法!
What is new with Gemma 4?
与 Gemma-3n 类似,Gemma 4 支持图像、文本和音频输入,并生成文本响应。文本解码器基于 Gemma 模型,并支持长上下文窗口。图像编码器与 Gemma 3 的编码器类似,但进行了两项关键改进:可变宽高比和可配置的图像 token 输入数量,以便用户在速度、内存和质量之间找到最佳平衡点。所有型号均支持图像(或视频)和文本输入,而小型版本(E2B 和 E4B)还支持音频输入。
Gemma 4 有四种尺寸,所有底座和说明都经过了微调:

Overview of Capabilities and Architecture
Gemma 4 利用了之前 Gemma 版本和其他开源模型中使用的多个架构组件,并剔除了 Altup 等复杂或不确定的功能。这种组合旨在实现跨库和设备的高度兼容性,能够高效支持长上下文和代理用例,同时非常适合量化。
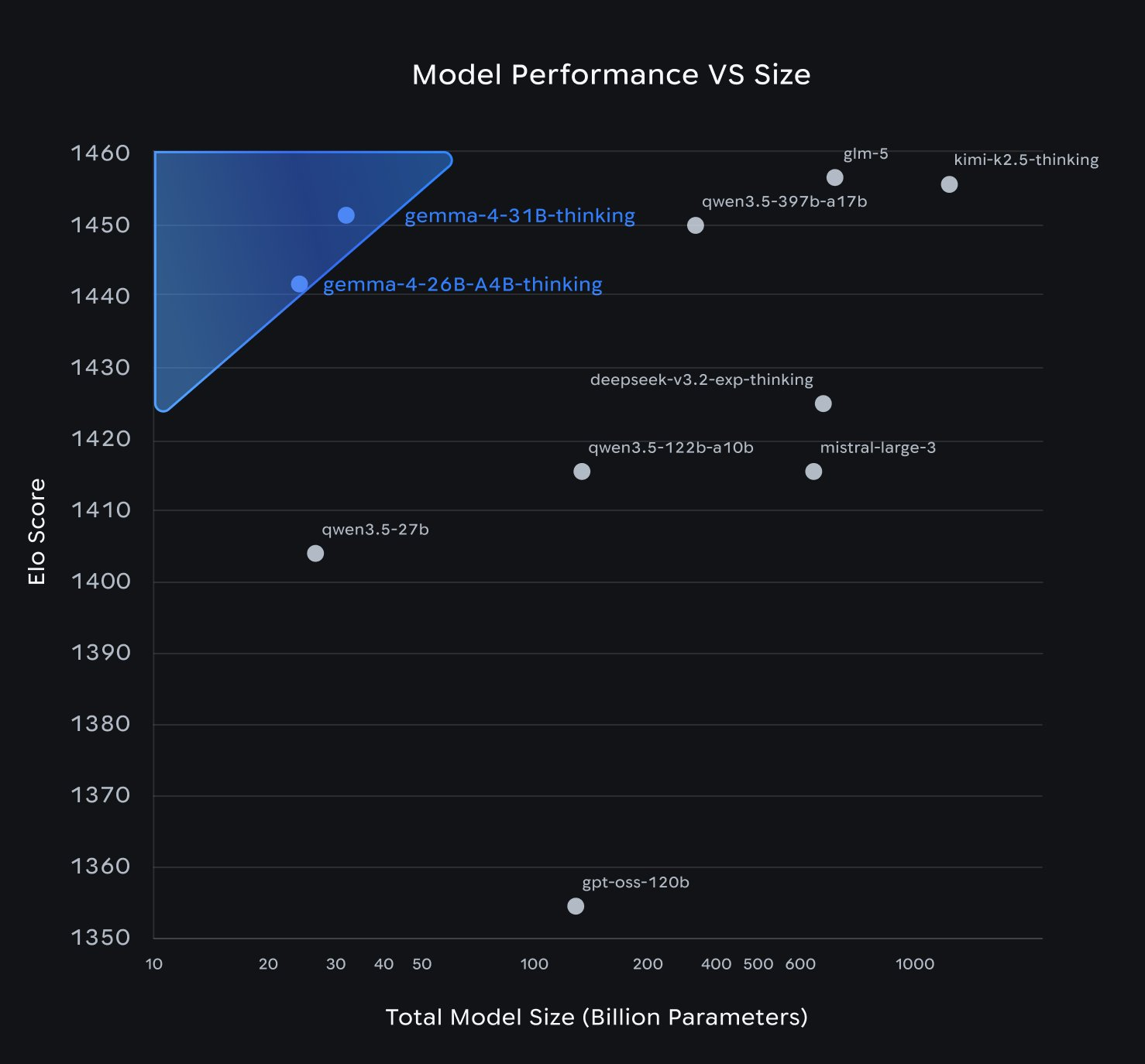
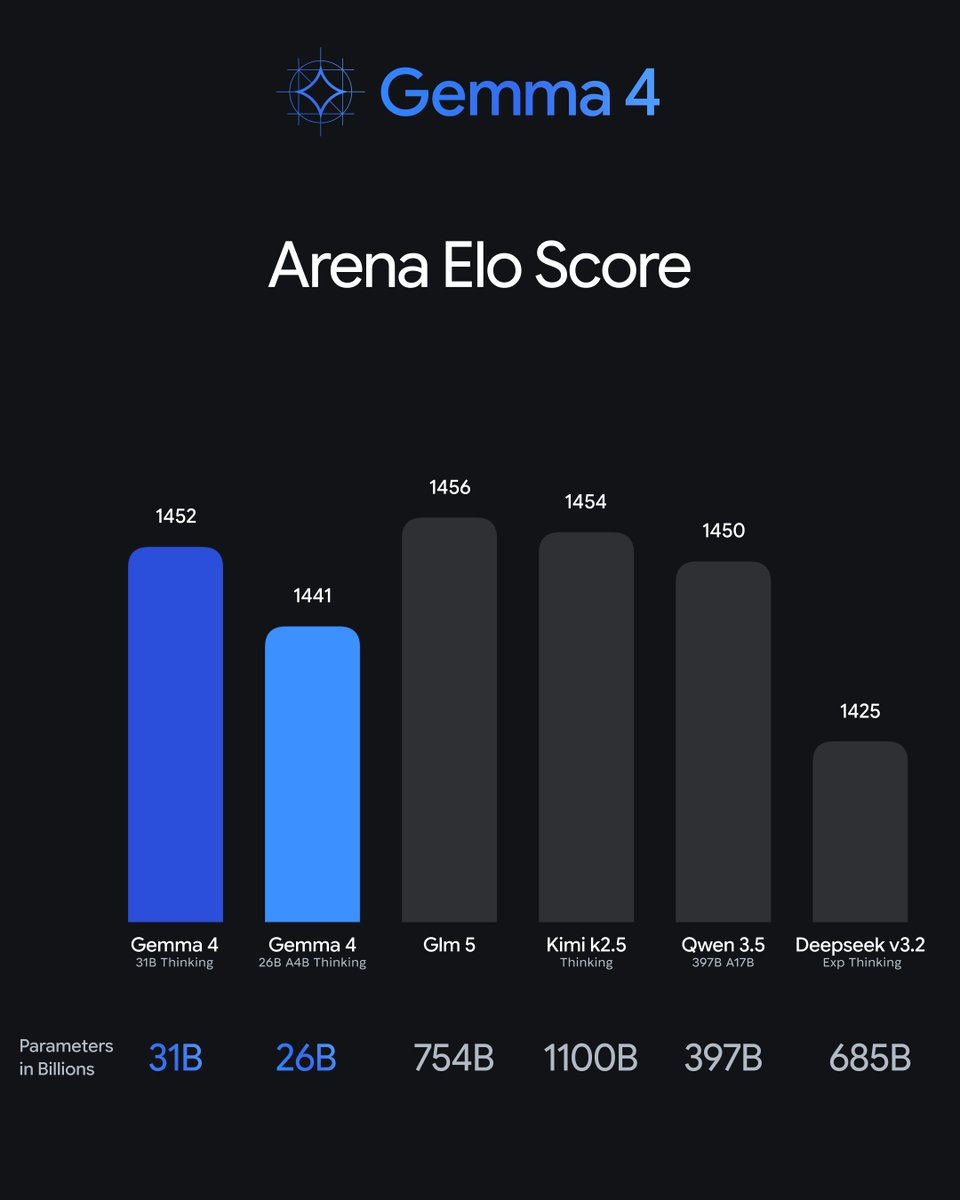
如上文基准测试所示,这种特征组合(结合训练数据和算法)使得 31B 密集模型能够达到 1452 的 LMArena 估计得分(仅文本),而 26B MoE 仅使用 4B 有效参数就达到了 1441 分🤯。正如我们将看到的,多模态操作至少在非正式和主观测试中,其效果与文本生成相当。
以下是Gemma 4的主要架构特点:
- 交替使用局部滑动窗口和全局全上下文注意力层。较小的密集模型使用 512 个 token 的滑动窗口,而较大的模型使用 1024 个 token 的滑动窗口。
- 双 RoPE 配置:标准 RoPE 用于滑动窗口层,比例 RoPE 用于全局层,以实现更长的上下文。
- Per-Layer Embeddings(PLE):第二个嵌入表,将一个小的残差信号输入到每个解码器层。
- 共享 KV 缓存:模型的最后 N 层重用来自前面层的 key-value 状态,消除冗余的 KV 投影。
- 视觉编码器:使用学习到的 2D 位置和多维 RoPE。保留原始宽高比,并且可以将图像编码为几种不同的 token 预算(70、140、280、560、1120)。
- 音频编码器:USM 风格的编码器,其基本架构与 Gemma-3n 中的编码器相同。
Per-Layer Embeddings (PLE)
Gemma 4 小型模型最显著的特征之一是 Per-Layer Embeddings(PLE),该特性此前已在 Gemma-3n 中引入。在标准的 Transformer 模型中,每个 token 在输入时都只有一个嵌入向量,并且残差流的所有层都基于相同的初始表示,这迫使嵌入向量预先加载模型可能需要的所有信息。PLE 在主残差流之外增加了一条并行的、低维的条件化路径。对于每个 token,它通过组合两个信号为每个层生成一个小型专用向量:一个 token 标识分量(来自嵌入查找)和一个上下文感知分量(来自对主嵌入向量的学习投影)。然后,每个解码器层使用其对应的向量,通过注意力机制和前馈之后的轻量级残差块来调制隐藏状态。这使得每一层都拥有自己的通道,仅在需要时才接收特定于 token 的信息,而无需将所有信息打包到一个预先存在的嵌入向量中。由于 PLE 的维度远小于主隐藏层的大小,因此只需付出适度的参数代价即可实现有意义的逐层特化。对于多模态输入(图像、音频、视频),PLE 的计算在软 token 合并到嵌入序列之前进行——因为 PLE 依赖于 token ID,而这些 ID 在多模态特征替换占位符后会丢失。多模态位置使用填充 token ID,从而有效地接收中性的逐层信号。
Shared KV Cache
共享 key-value 缓存是一种效率优化机制,可在推理过程中减少计算和内存消耗。模型的最后 num_kv_shared_layers 层不再计算自身的 key-value 投影,而是复用来自最后一个相同注意力类型(滑动或完全注意力)的非共享层的 key-value 张量。
实际上,这种机制对模型质量的影响微乎其微,同时在长时间上下文生成和设备端使用方面效率更高(无论在内存还是计算方面)。
Multimodal Capabilities
我们在测试中发现,Gemma 4 开箱即用,支持全面的多模态功能。我们不清楚具体的训练数据组合,但它在 OCR、语音转文本、目标检测和指向等任务中均表现出色。此外,它还支持纯文本和多模态函数调用、推理、代码补全和纠错。
这里,我们展示了一些不同模型规模下的推理示例。您可以使用此笔记本轻松运行这些示例。我们鼓励您尝试这些演示,并在博客下方分享您的体验!
Object Detection and Pointing
GUI detection
我们使用以下图像和文本提示测试 Gemma 4 在不同尺寸下检测和指向 GUI 元素的能力:“What’s the bounding box for the “view recipe” element in the image?”
有了此提示,模型会以 JSON 格式原生返回检测到的边界框——无需任何特殊指令或语法约束生成。我们发现这些坐标对应于 1000x1000 像素的图像尺寸,与输入尺寸相对应。
为了方便您理解,我们在下方可视化了输出结果。我们从返回的 JSON 中解析出边界框:json\n[\n {"box_2d": [171, 75, 245, 308], "label": "view recipe element"}\n]\n
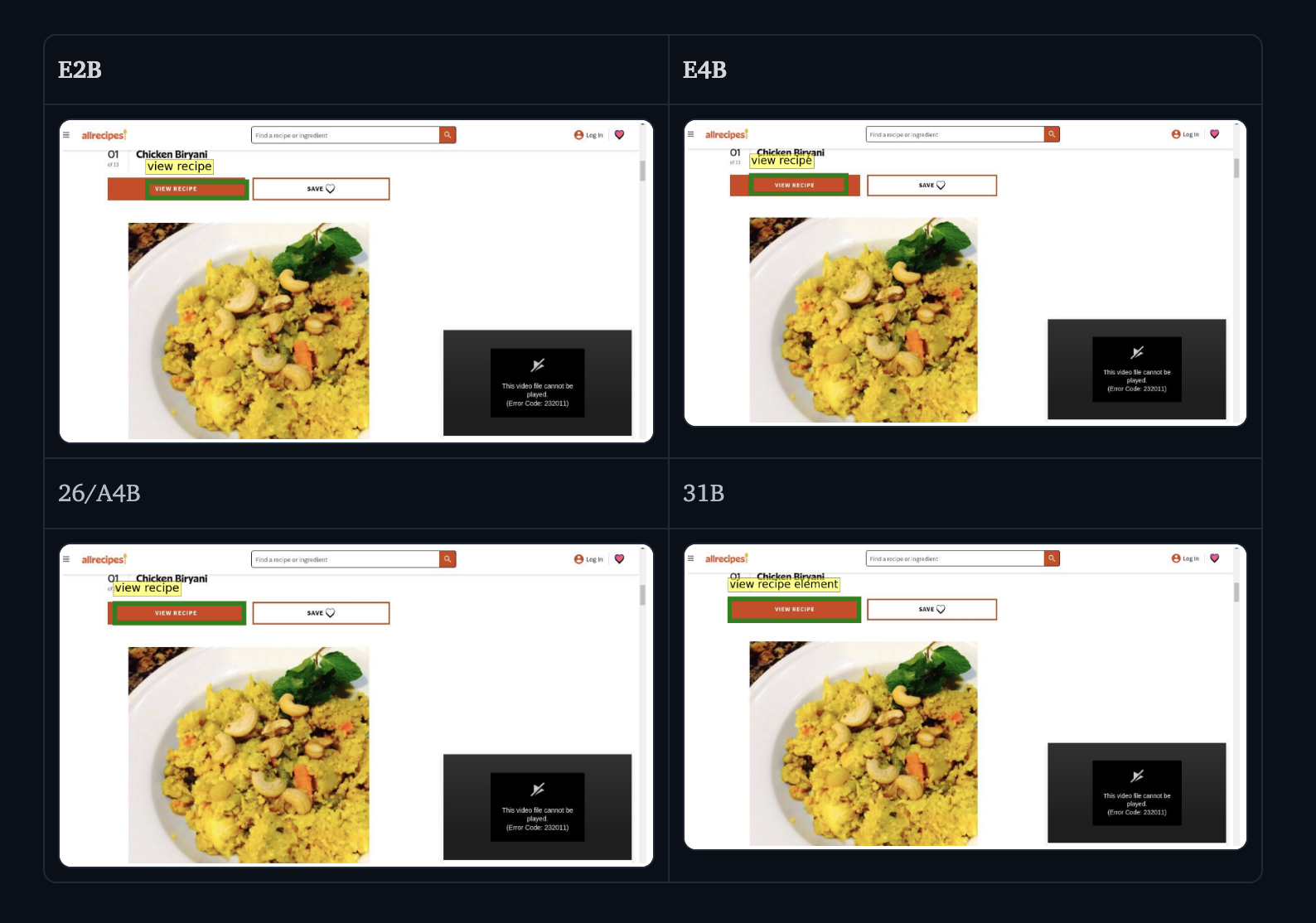
Object Detection
Video Understanding
Captioning
Audio Question Answering
Multimodal Function Calling
Benchmark Results
Gemma 4 模型在从推理和编码到视觉和长上下文任务等各种基准测试中均展现出卓越的性能。下图显示了模型性能与规模的关系,Gemma 4 模型构成了一个令人印象深刻的帕累托前沿: