论文链接:https://arxiv.org/pdf/2602.15763
代码链接:https://github.com/zai-org/GLM-5
摘要
我们提出了 GLM-5,这是一个旨在将 Vibe Coding 范式过渡到智能体工程的新一代基础模型。GLM-5 基于其前代产品的智能体、推理和编码 (ARC) 能力,并采用 DSA 来显著降低训练和推理成本,同时保持长上下文保真度。为了提升模型对齐和自主性,我们实现了一种新的异步强化学习基础设施,通过将生成与训练解耦,大幅提高了后训练的效率。此外,我们还提出了新的异步智能体强化学习算法,进一步提升了强化学习的质量,使模型能够更有效地从复杂的长时程交互中学习。凭借这些创新,GLM-5 在主要的开放基准测试中取得了最先进的性能。最重要的是,GLM-5 在实际编码任务中展现了前所未有的能力,在处理端到端软件工程挑战方面超越了以往的基线模型。代码、模型和更多信息可在 https://github.com/zai-org/GLM-5 获取。
1.Introduction
追求通用人工智能(AGI)不仅需要扩展模型参数,还需要从根本上重新思考智能效率和自主改进的架构。随着 GLM-4.5 的发布,我们证明了将智能体、推理和编码(ARC)能力整合到单一的专家模型(MoE)架构中,可以在各种基准测试中获得最先进的结果。然而,随着大语言模型(LLM)从被动的知识库向主动的问题求解器转变,计算成本和实际应用适应性的双重挑战——尤其是在复杂的软件工程中——已成为主要的瓶颈。
我们隆重推出 GLM-5,这是我们为克服这些障碍而设计的下一代旗舰模型。GLM-5 在性能和效率方面实现了范式转变,在包括 ArtificialAnalysis.ai、LMArena Text 和 LMArena Code 在内的主要公开排行榜上均取得了领先地位。更重要的是,GLM-5 重新定义了实际编码的标准,展现了前所未有的能力,能够处理复杂的端到端软件开发任务,远远超出了 SWE-bench 等传统静态基准测试的范围。
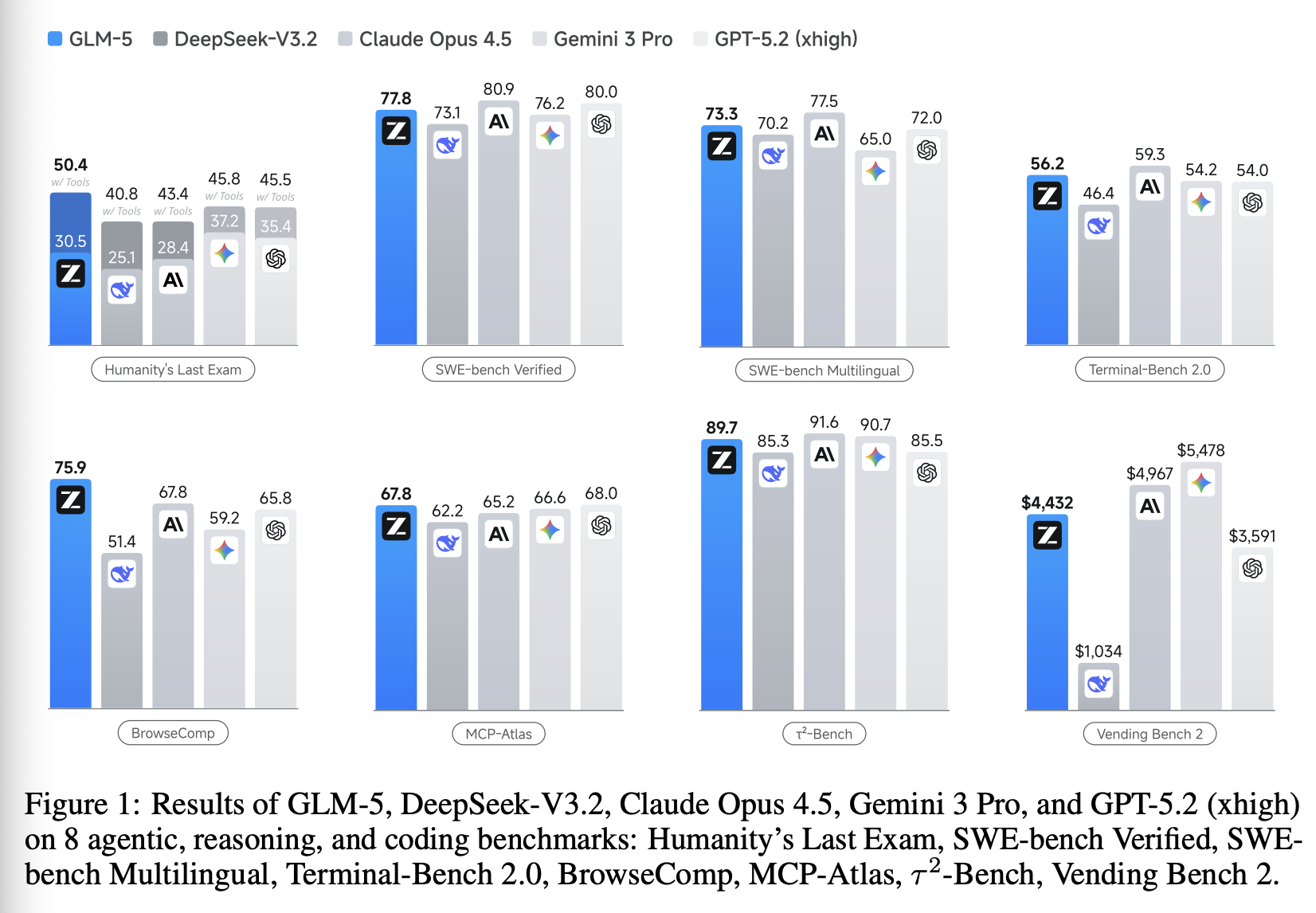
Results。图 1 展示了 GLM-5、GLM-4.7、Claude Opus 4.5、Gemini 3 Pro 和 GPT-5.2 (xhigh) 在 8 个智能体、推理和编码基准测试中的结果:Humanity’s Last Exam、SWEbench Verified、SWE-bench Multilingual、Terminal-Bench 2.0、BrowseComp、MCP-Atlas、τ2-Bench 和 Vending Bench 2。平均而言,GLM-5 比我们之前的版本 GLM-4.7 提升了约 20%,与 Claude Opus 4.5 和 GPT-5.2 (xhigh) 的性能相当,并且优于 Gemini 3 Pro。
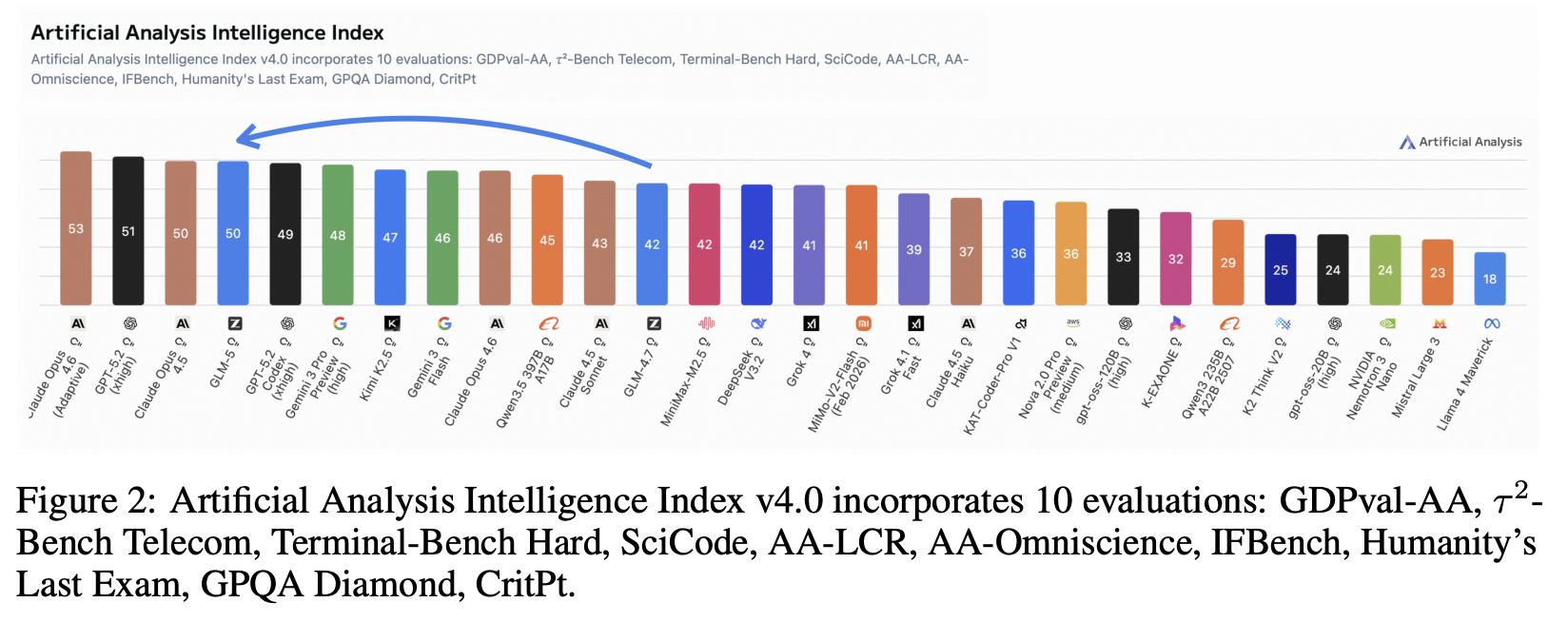
GLM-5 在人工智能指数 v4.0 中获得 50 分,成为新的开放权重模型领跑者(参见图 2),较 GLM-4.7 的 42 分大幅提升 8 分,这主要得益于其在智能体性能和知识/幻觉方面的改进。这是开放权重模型首次在人工智能分析智能指数 v4.0 中获得 50 分。

由加州大学伯克利分校发起的 LMArena 是一个透明的共享平台,旨在通过数百万个真实任务(包括写作、编码、推理、设计、搜索和创作)来评估和比较前沿人工智能的能力,并结合人类的判断。大量的人机交互能够产生反映真实世界实用性的信号,这使其区别于其他静态基准测试。图3显示,GLM-5在文本竞技场和代码竞技场中再次位列开源模型榜首,并且总体性能与Claude-Opus-4.5和Gemini-3-pro不相上下。
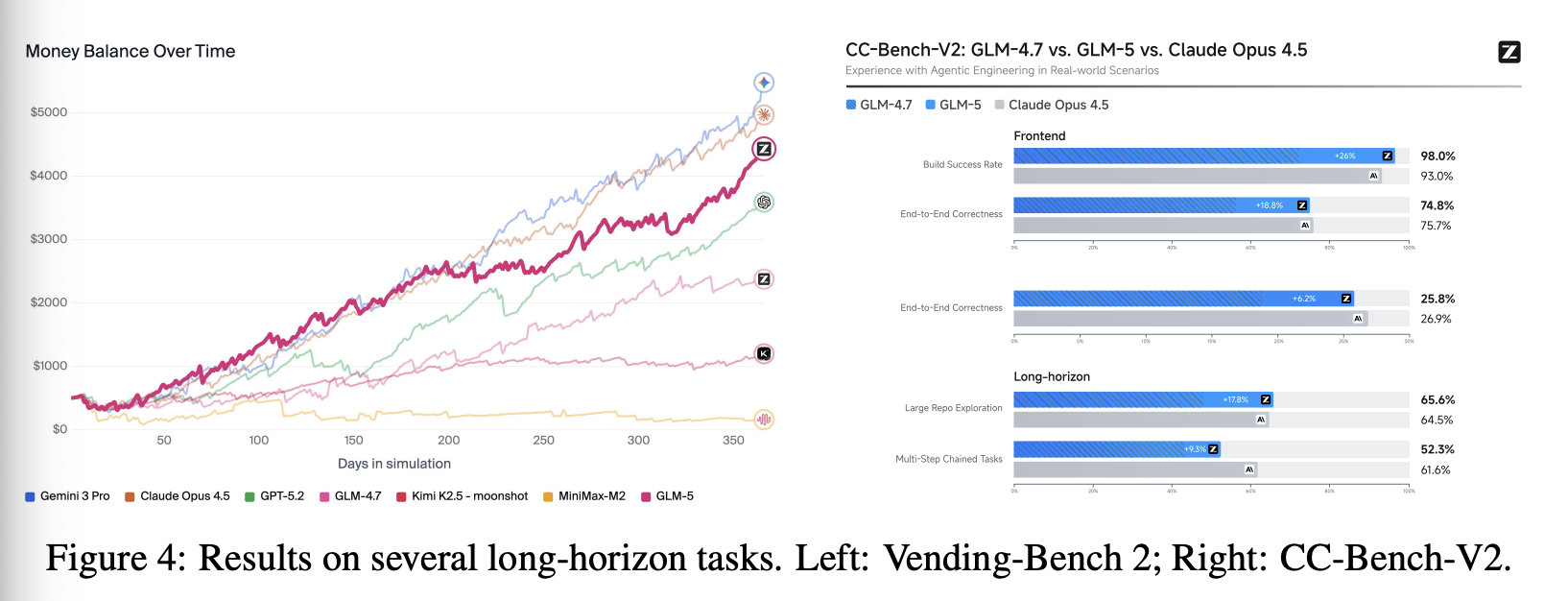
智能体的长期一致性变得越来越重要。编码智能体现在可以自主编写代码数小时,人工智能模型能够完成的任务范围和时长也可能不断扩大。我们使用两个基准测试:Vending-Bench 2 和 CC-Bench-V2,来评估 GLM-5 完成长期任务的能力。Vending-Bench 2 是一个用于衡量人工智能模型在长期运营业务方面性能的基准测试。模型的任务是运营一个模拟的自动售货机业务一年,并根据其最终的银行账户余额进行评分。图 4(左)显示,GLM-5 在所有开源模型中排名第一,最终账户余额为 4,432 美元。它接近 Claude Opus 4.5 的水平,展现出强大的长期规划和资源管理能力。图 4(右)进一步展示了我们内部评估套件 CC-Bench-V2 的结果。 GLM-5 在前端、后端和长期任务中明显优于 GLM-4.7,缩小了与 Claude Opus 4.5 的差距。
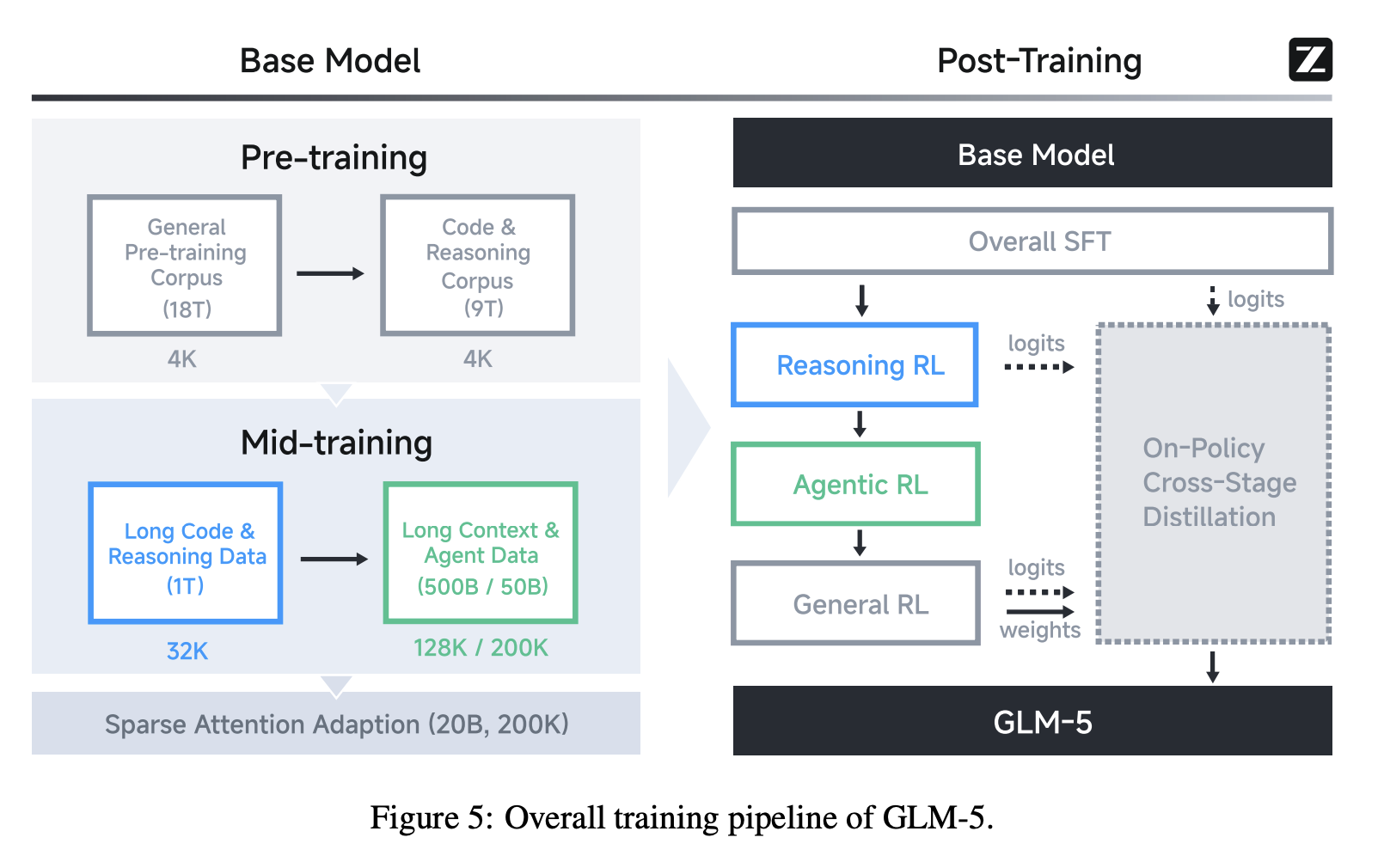
Methods。图 5 展示了 GLM-5 的整体训练流程。我们的基础模型训练始于一个庞大的 27 万亿 token 语料库,早期重点训练代码和推理能力。随后,我们采用了一个独立的中期训练阶段,逐步将上下文长度从 4K 扩展到 200K,尤其关注长上下文的智能体数据,以确保模型在复杂工作流程中的稳定性。在后训练阶段,我们超越了标准的 SFT(结构化框架训练)。我们实现了一个顺序强化学习流程——首先是推理强化学习,然后是智能体强化学习,最后是通用强化学习。至关重要的是,我们在整个过程中都使用了 On-Policy Cross-Stage Distillation 技术,以防止灾难性遗忘,确保模型在保持其敏锐推理能力的同时,成为一个强大的通用模型。总而言之,GLM-5 性能的飞跃得益于以下技术贡献:
- 首先,我们采用了DSA(DeepSeek Sparse Attention),这是一种新的架构创新,能够显著降低训练和推理成本。虽然 GLM-4.5 通过标准的 MoE 架构提高了效率,但 DSA 允许 GLM-5 根据 token 重要性动态分配注意力资源,从而大幅降低计算开销,同时又不影响长上下文理解或推理深度。借助 DSA,我们将模型参数扩展到744B,并将训练 token 预算扩展到 28.5T 个词元。
- 其次,我们构建了一个全新的异步强化学习基础设施。基于“slime”框架和 GLM-4.5 中初始化的解耦式 rollout 引擎,我们的新基础设施进一步将生成与训练解耦,从而最大限度地利用 GPU。该系统能够大规模探索智能体轨迹,避免了以往阻碍迭代速度的同步瓶颈,显著提高了强化学习后训练流程的效率。
- 第三,我们提出了一系列新型异步智能体强化学习算法,旨在提升自主决策的质量。在 GLM-4.5 中,我们利用迭代自蒸馏和结果监督来训练智能体。对于GLM-5,我们开发了异步算法,使模型能够持续地从多样化的、长时程的交互中学习。这些算法经过专门优化,能够提升模型在动态环境中的规划和自纠错能力,从而直接促成了我们在实际编码场景中的优势。
- 最后,GLM-5 的另一项技术贡献在于,它从一开始就针对中国 GPU 生态系统进行了全栈适配。我们已成功完成了深度优化,涵盖了从底层内核到上层推理框架的各个层面,覆盖了包括华为昇腾、Moore Threads、海光、寒武纪、昆仑鑫、MetaX和Enflame在内的七大国内主流芯片平台。
凭借这些进步,GLM-5 不仅是一个更强大的模型,而且为下一代人工智能代理提供了更高效、更实用的基础。我们向社区发布 GLM-5,以进一步推进高效、自主通用智能的发展。
2. Pre-Training
与 GLM-4.5 类似,GLM-5 的基础模型也经历两个阶段:预训练阶段用于培养通用语言和编码能力,中期训练阶段用于培养智能体和长上下文能力。我们扩展了 GLM-5 所有训练阶段的训练 token 预算,基础模型的总 token 数达到 28.5 万亿。
2.1 Architecture
Model size scaling。GLM-5 可扩展至 256 位专家,并将层数减少到 80 层,以最大限度地减少专家并行通信开销。这使得模型参数量达到 744 B(其中 40B 为活跃参数),是 GLM-4.5 总参数量(355 B,其中 32 B 为活跃参数)的两倍。
Multi-latent Attention。通过采用减少的 key-value 向量,Multi-Latent Attention (MLA) 可以达到 Grouped-Query Attention (GQA) 的效果,但对于长上下文序列,可以提供更优异的 GPU 内存节省和更快的处理速度。
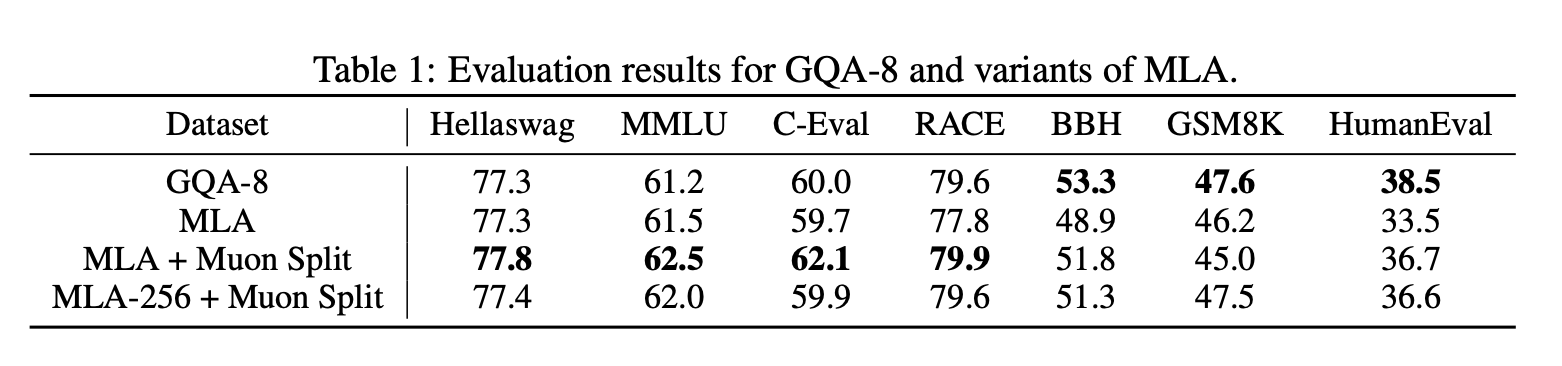
然而,在我们使用 Muon 优化器的实验中,我们发现具有 576 维潜在 KV-cache 的 MLA 的性能无法与具有 8 个 query 组的 GQA(记为 GQA-8,具有 2048 维 KV-cache)相媲美。为了克服性能差距,我们提出了一种改进 GLM-4.5 中 Muon 优化器的方法。在原方法中,我们对多头 query、key 和 value 的上投影矩阵 、 和 应用了矩阵正交化。而我们则将这些矩阵拆分为更小的矩阵,分别对应不同的注意力头,并对这些独立的矩阵应用矩阵正交化。该方法称为 Muon Split,它允许不同注意力头的投影权重以不同的尺度进行更新。如表 1 所示,该方法有效地提升了 MLA 的性能,使其与 GQA-8 的性能相当。在实践中,我们还发现,使用 Muon Split 时,GLM-5 的注意力 logits 的规模在预训练期间保持稳定,而无需任何裁剪策略。
MLA 的另一个缺点是解码过程中计算量大。在解码过程中,MLA执行 576 维的点积运算,高于 GQA 的128维计算量。虽然 DeepSeek-V3 中的注意力头数量是根据H800的 roofline 选择的,但这并不适用于其他硬件。考虑到 MLA 在训练和预填充过程中采用的多头注意力(MHA)风格,我们将注意力头的维度从 192 增加到 256,并将注意力头的数量减少1/3。这样既保持了训练计算量和参数数量不变,又降低了解码计算量。表1中标记为 MLA-256 的变体在 Muon Split 上的性能与MLA相当。
Multi-token Prediction with Parameter Sharing。多 token 预测 (MTP) 可以提升基础模型的性能,并作为推测解码的草稿模型。然而,在训练过程中,预测接下来的 n 个 token 需要 n 个 MTP 层。因此,MTP 参数和 KV-cache 的内存使用量与推测步骤的数量呈线性关系。相比之下,DeepSeek-V3 使用单个 MTP 层进行训练,并在推理过程中预测接下来的 2 个 token。训练和推理结果之间的差异会降低第二个 token 的接受率。因此,我们提出在训练过程中共享 3 个 MTP 层的参数。这样既能保持草稿模型的内存开销与 DeepSeek-V3 一致,又能提高接受率。表 2 显示,在我们的私有提示集上,对于相同数量的推测步骤 (4),GLM-5 的接受长度比 DeepSeek-V3.2 更长。

2.1.1 Continued Pre-Training with DeepSeek Sparse Attention (DSA)
我们在训练中使用了 DSA。DSA 的核心理念是用动态、细粒度的选择机制来替代传统的密集型 注意力机制——后者在处理 128K 个上下文时计算成本极高。与固定模式(例如滑动窗口)不同,DSA 会“观察”内容来判断哪些 token 是重要的。从研究者的角度来看,DSA 最引人注目之处在于它通过从密集型基础模型进行持续预训练的方式引入。这避免了从头开始训练的“天文数字”成本。过渡过程遵循两阶段策略:“密集型预热和稀疏型训练自适应”。DeepSeek-V3.2-Exp 保持了与其密集型前身相同的基准性能,证明了长上下文中 90% 的注意力条目确实是冗余的。对于长序列,DSA 将注意力计算量降低了大约 1.5-2 倍,这对于我们正在构建的推理密集型智能体来说至关重要,因为它能够以一半的 GPU 成本处理 128K 个上下文。
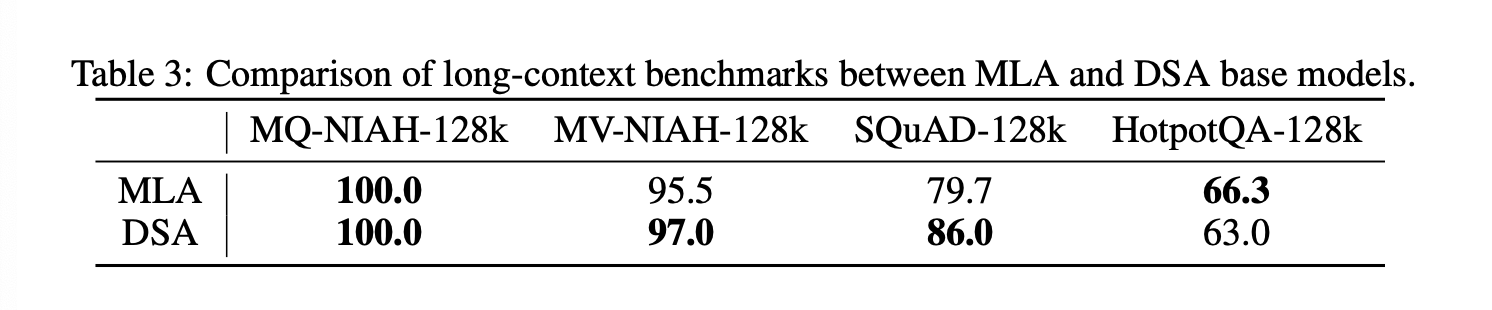
DSA 训练从中期训练结束时的基础模型开始。预热阶段包含 1000 个步骤,每个步骤使用 14 个序列(每个序列包含 202,752 个 token)进行训练,最大学习率为 5e-3。稀疏自适应阶段使用中期训练的训练数据和超参数,并处理 200 亿个 token。虽然训练预算远小于 DeepSeek-V3.2(9437 亿个 token),但我们发现这足以使 DSA 模型自适应到与原始 MLA 模型性能相当的水平。如表 3 所示,DSA 模型的长上下文性能与 MLA 模型接近。为了进一步验证 DSA 训练的有效性,我们分别使用相同的 SFT 数据集对 DSA 和 MLA 模型进行微调,发现两个模型在训练损失和评估基准方面表现一致。
2.1.2 Ablation Study of Efficient Attention Variants
除了 DSA 之外,我们还探索了几种基于 GLM-9B 的替代高效注意力机制。基线模型在所有 40 层中采用分组查询注意力,并使用 128K 个 token 的上下文窗口进行了微调。我们评估了以下方法:
- Sliding Window Attention (SWA) Interleave:在整个网络中均匀应用全注意力层和窗口注意力层的固定交替模式。
- Gated DeltaNet (GDN):一种线性注意力变体,它用门控线性递归代替二次 softmax 注意力计算,将注意力的计算成本从序列长度的二次方降低到线性。
在此基础上,我们提出两项改进:
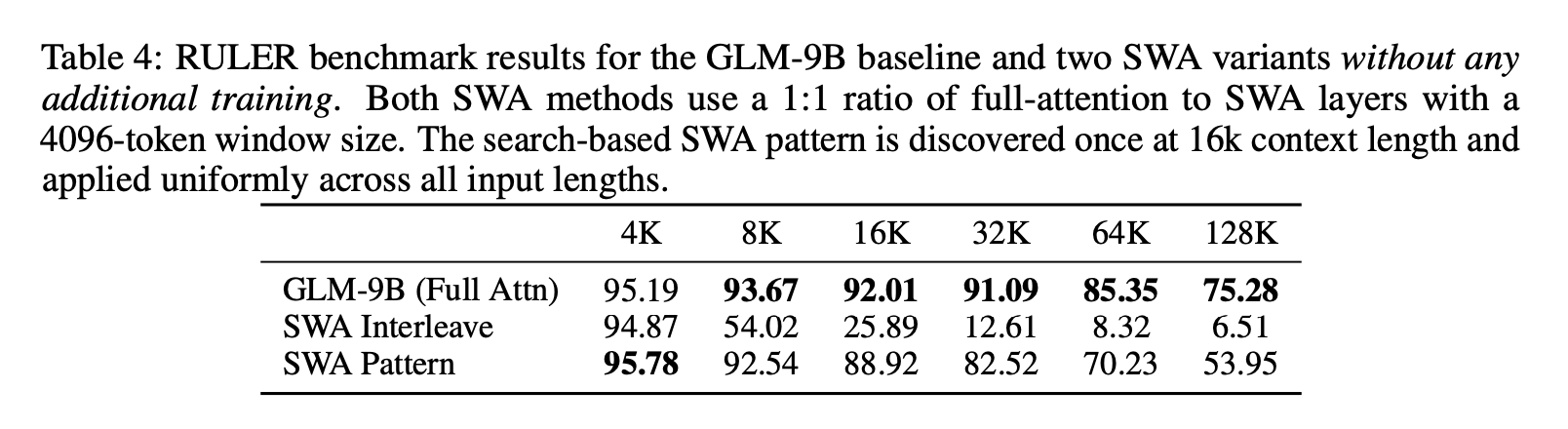
- SWA Pattern (Search-Based):受 PostNAS 的启发,我们提出了一种基于搜索的自适应方法,该方法在保持其余层完全注意力机制的同时,识别出用于 SWA 转换的最佳层子集。我们采用集束搜索策略来确定能够最大化长上下文下游任务性能的配置。为了降低计算成本,我们仅在 16K 上下文长度下进行搜索,并将得到的模式推广到所有其他输入长度。具体来说,我们使用 8 的 beam size,每步优化两层;对于 GLM-9B(40 层),该过程大约需要 10 步即可收敛。在每一步中,候选模式在 16K 上下文长度的 RULER 基准测试上进行评估,并将前 8 个候选模式保留到下一步。最终得到的模式为 SFSSFFSSSFFFFSSFSFFFFFFSFSFSSFSSFSFSSFSSS,其中 S 和 F 分别表示 SWA 层和完全注意力层。如表 4 所示,这种基于搜索的配置显著优于固定交错方法。值得注意的是,尽管该模式仅在 16K 时进行了优化,但它表现出强大的长度泛化能力,在所有测试的上下文长度中都保持有效。
- SimpleGDN:本文提出了一种极简的线性化策略,旨在最大程度地复用预训练权重,并改进了 GDN 的持续训练自适应能力。我们完全移除了 Conv1d 和显式门控模块,而是将预训练的 query、key 和 value 投影权重直接映射到线性递归公式中。这种简化方法无需额外的参数,同时保留了线性注意力机制的效率优势。
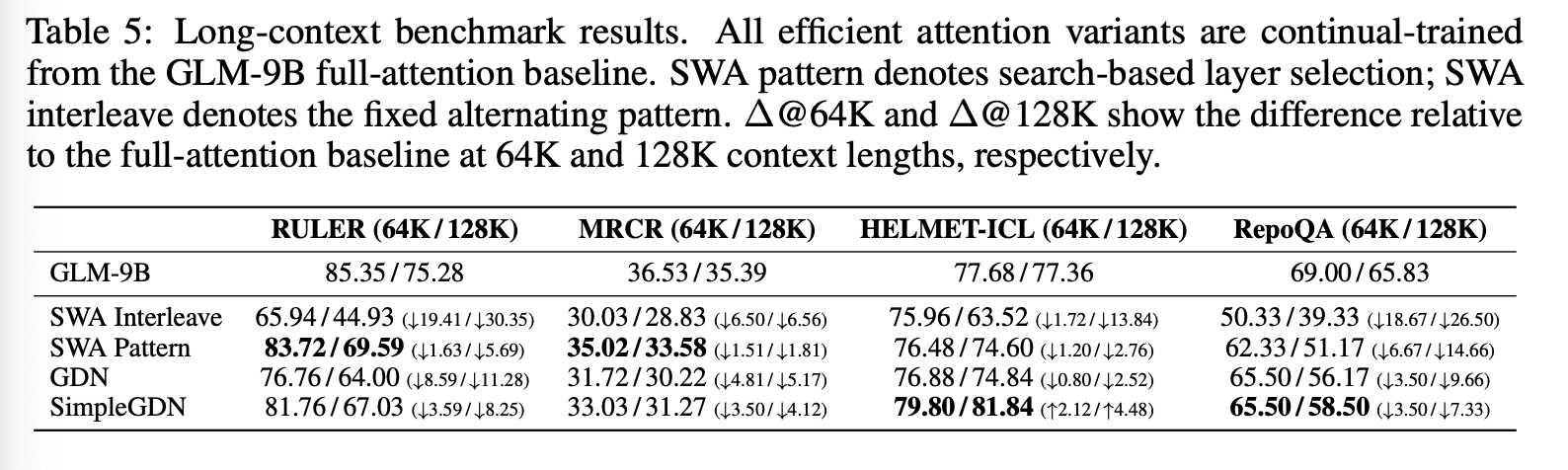
我们在四个长上下文基准数据集上评估了所有方法:RULER、MRCR、HELMETICL 和 RepoQA。结果汇总于表 5。我们使用 190B 个 token,上下文长度为 64K,持续训练每种方法,并保持高效注意力层和完整注意力层 1:1 的比例。对于 GDN 和 SimpleGDN 方法,我们遵循 Jet-Nemotron 流程。
表 5 的结果揭示了高效注意力机制之间清晰的权衡关系。简单的交错滑动窗口注意力(SWA)在长上下文任务上会导致灾难性的性能下降(例如,在RULER@128K任务上下降30.35分),而基于搜索的层选择通过在关键区域保留完整的注意力机制显著缩小了这一差距。线性注意力机制的变体,例如 GDN,可以进一步提高性能,但代价是需要额外的参数;SimpleGDN 通过最大程度地复用预训练权重,实现了最佳平衡。然而,所有这些方法在细粒度检索任务上都存在固有的准确率差距——在 RULER@128K 任务上最高可达5.69分,在RepoQA@128K任务上最高可达7.33分——这是由于高效注意力机制在持续训练适应过程中不可避免地引入了信息损失,即使一半的层保留了完整的注意力机制也是如此。相比之下,DSA 从构造上来说就是无损的:它的 lightning indexer 实现了 token 级稀疏性,而不会丢弃任何长距离依赖关系,从而可以应用于所有层而不会降低质量。
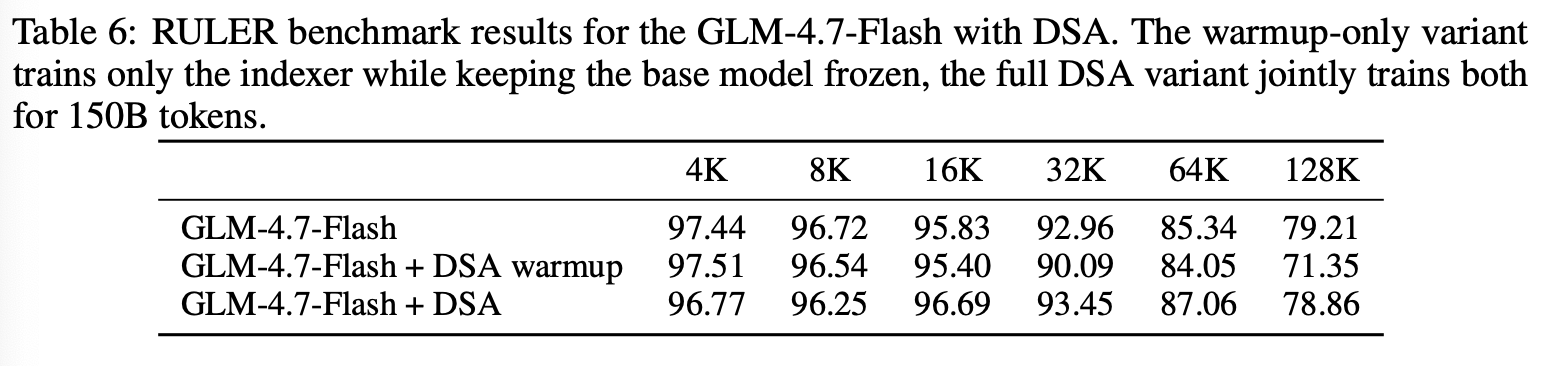
为了验证这一点,我们在具有 MLA 机制的 GLM-4.7-Flash 模型上进行了小规模的 DSA 实验。按照标准的 DSA 流程,训练分为两个阶段:(i)预热阶段,仅训练索引器 1000 步(batch size 为 16),同时保持所有基模型权重不变;(ii)联合训练阶段,模型和索引器在 150B 个 token 上进行联合训练。表 6 总结了在 RULER 数据集上,上下文长度从 4K 到 128K 的实验结果。即使是仅进行预热的变体(GLM-4.7-Flash + DSA 预热)也已经保留了绝大部分的基线性能;性能下降幅度不大,且集中在最长的上下文窗口(128K:79.21 → 71.35),而较短的上下文几乎不受影响。在完成 150B token 的联合训练阶段后,GLM-4.7-Flash + DSA 几乎完全消除了这一剩余差距:它在 16K (+0.86)、32K (+0.49) 和 64K (+1.72) 处超过了基线,而在 128K 处仅产生了 0.35 个百分点的差距。
2.2 Pre-training Data
Web。基于 GLM-4.5 数据管道,我们优化了针对海量网络数据集的选择标准。我们引入了基于句子嵌入的 DCLM 分类器,用于识别和聚合标准分类器无法获取的高质量数据。为了应对长尾知识的挑战,我们利用 World Knowledge 分类器(通过维基百科条目和 LLM 标注数据进行优化)从原本质量中等偏低的数据中提取有价值的信息。
Code。我们利用来自主流代码托管平台的最新快照和更大规模的包含代码的网页集合,扩展了代码预训练语料库,从而使模糊去重后的唯一 token 数量增加了 28%。为了提高语料库的完整性并降低噪声,我们修复了 Software Heritage 代码文件中的元数据对齐问题,并采用了更精确的语言分类流程。我们遵循 GLM-4.5 的质量感知采样策略来处理源代码和与代码相关的网页文档。此外,我们还针对更广泛的低资源编程语言(例如 Scala、Swift、Lua 等)训练了专用分类器,从而提高了这些语言的采样质量。
Math & Science。我们从网页、书籍和论文中收集高质量的数学和科学数据,以进一步提升推理能力。具体而言,我们改进了网页内容提取流程和书籍、论文的PDF解析机制,以提高数据质量。我们采用大型语言模型对候选文档进行评分,并仅保留最具教育意义的内容。对于长上下文文档,我们开发了一种分块聚合评分算法,以提高评分准确率。我们实施了过滤流程,严格避免使用合成数据、AI生成数据或基于模板的数据。
2.3 Mid-Training
在 GLM-4.5 中引入的中期训练框架的基础上,我们在 GLM-5 中扩大了训练量和最大上下文长度,以进一步增强模型的推理能力、长上下文能力和智能能力。
Extended context and training scale。我们将上下文窗口逐步扩展,分为三个阶段:32K(1T token)、128K(500B token)和 200K(500B token)。与 GLM-4.5 中 128K 的最大值相比,新增的 200K 阶段显著提升了模型处理超长文档和复杂多文件代码库的能力。在后续阶段,长文档和合成 Agent 轨迹会相应地进行上采样。
Software engineering data。我们保留了将仓库级代码文件、提交差异、GitHub 问题、拉取请求和相关源文件连接成统一训练序列的范式。在 GLM-5 中,我们放宽了仓库级过滤标准,扩大了符合条件的仓库范围,从而获得了约 1000 万个问题-拉取请求对,同时加强了单个问题级别的质量过滤以降低噪声。此外,我们还为每个问题-拉取请求对检索了更多相关文件,从而获得了更丰富的开发上下文和更广泛的真实软件工程场景覆盖。过滤后,数据集中问题-拉取请求部分包含约 1600 亿个唯一标记。
Long-context data。我们的长上下文训练集包含自然数据和合成数据。自然数据来自书籍、学术论文和通用预训练语料库中的文档,采用多阶段过滤(PPL、去重、长度过滤)和对知识密集型领域的上采样方法进行筛选。在合成数据构建方面,我们受到 NextLong 和 EntropyLong 的启发,采用了多种技术来构建长程依赖关系。高度相似的文本通过交错打包进行聚合以生成序列,旨在缓解中间丢失现象,并提高模型在各种长上下文任务中的性能。在 20 万条数据阶段,我们还加入了一小部分类似 MRCR 的数据,并设计了多个变体来扩展 OpenAI 的原始范式,以增强模型在扩展的多轮对话中的召回率。实验结果表明,增加数据多样性可以逐步提升模型的长上下文性能。值得注意的是,在最初的 128K 阶段的基础上,随后的 200K 中期训练阶段进一步增强了模型的性能,即使在 128K 上下文窗口中也是如此。
2.4 Training Infrastructure
2.4.1 Memory Efficiency
Flexible MTP placement。在交错流水线并行化中,模型组件可以灵活地分配到各个阶段。MTP 模块包含嵌入、Transformer和输出组件。与其他模块相比,它的内存使用量显著更高,导致阶段级内存分配不平衡。为了实现参数共享,我们将MTP的输出层与主输出层置于最终阶段,同时将其嵌入和Transformer组件放置在前一个阶段。这降低了最终阶段的内存压力,并改善了流水线各阶段之间的内存平衡。
Pipeline ZeRO2 gradient sharding。每个流水线进程维护多个阶段,通常情况下,每个阶段都需要一个完整的梯度缓冲区用于梯度累积和优化器更新。受 ZeRO2 的启发,我们将梯度分片到数据并行进程中,使得每个阶段仅存储完整梯度的 1/dp 部分。此外,我们每次只保留两个阶段的完整累积缓冲区,并通过双缓冲机制重用它们。当一个阶段的缓冲区累积连续微批次的梯度时,前一个阶段缓冲区的梯度同步并行执行。这使得持久梯度内存减少到每个阶段的分片缓冲区加上两个用于滚动累积的完整缓冲区,而实际上并没有额外的同步开销。
Zero-redundant communication for the Muon distributed optimizer。朴素的 Muon 实现会在每个数据并行进程上收集所有模型参数,导致瞬态内存峰值和冗余通信。我们将收集限制在每个进程拥有的参数分片上,并将本地计算与分片通信重叠。这消除了冗余通信,并显著降低了与优化器相关的峰值内存开销。
Pipeline activation offloading。在流水线预热期间,前向执行会先于反向传播,从而延长中间激活的生命周期。前向执行结束后,我们将激活卸载到主机内存,并在反向执行之前重新加载它们。卸载操作以层为单位进行,以进一步降低峰值内存使用量。结合细粒度的重新计算,这在很大程度上消除了将激活驻留在GPU内存中的必要性。卸载和重新加载的调度与计算重叠,同时避免与点对点通信和MoE令牌路由(分发和组合)发生争用。这在几乎零开销的情况下,显著减少了激活的内存占用。
Sequence-chunked output projection for peak memory reduction。输出投影和交叉熵损失会因存储反向传播所需的激活值以及在损失计算过程中将其提升至更高精度而产生瞬态内存开销。为了降低这种开销,我们将输入序列分割成更小的块,并在每个块上独立计算投影和损失,在进行下一步之前完成前向和反向传播并释放激活值。因此,随着块数的增加,峰值内存使用量会降低。通过适当的块数,这种方法可以缓解输出层的内存压力,同时保持与非分块执行相当的性能。
2.4.2 Parallelism Efficiency
Efficient deferred weight gradient computation。为了减少流水线气泡,我们延迟计算关键路径上的部分权重梯度。通过优化存储和通信重叠,细粒度的延迟处理可以在保持内存开销有限的同时提高吞吐量。
Efficient long-sequence training。较长的序列会加剧数据并行组和流水线并行组之间的负载不均衡。我们通过感知工作负载的序列重排序、动态重新分配注意力计算以及将数据并行进程灵活划分为不同大小的上下文并行组来解决这个问题。为了降低延迟,我们采用分层全对全重叠的节点内和节点间通信机制来处理 QKV 张量。
INT4 Quantization-aware training
为了在低精度下提供更高的准确率,我们在 SFT 阶段应用了 INT4 QAT。此外,为了进一步降低训练时间开销,我们开发了一种量化核,该量化核既适用于训练,也适用于离线权重量化,从而确保训练和推理过程中的位级一致性。
3.Post-Training
GLM-5 的后训练阶段旨在将基础模型转化为具备强大推理、编码和智能体能力的高级助手。如图 5 所示,我们的流程遵循渐进式对齐策略:首先进行多任务有监督微调 (SFT),并引入复杂的交错思维模式;随后进行专门针对推理和智能体任务的强化学习 (RL) 阶段;最后进行通用的 RL 阶段,实现类人风格的对齐。通过利用on-policy 跨阶段蒸馏作为最终的优化步骤,GLM-5 能够有效缓解能力退化,同时充分利用每个训练阶段的性能提升。
3.1 Supervised Fine-Tuning
与 GLM-4.5 相比,GLM-5 在 SFT 阶段显著扩展了 Agent 和 Coding 数据的规模。GLM-5 的 SFT 语料库涵盖三大类:
- General Chat:问答、写作、角色扮演、翻译、多轮对话和长上下文交互;
- Reasoning:数学、编程和科学推理;
- Coding & Agent:前端和后端工程代码、工具调用、编码 Agent、搜索 Agent 和通用 Agent。
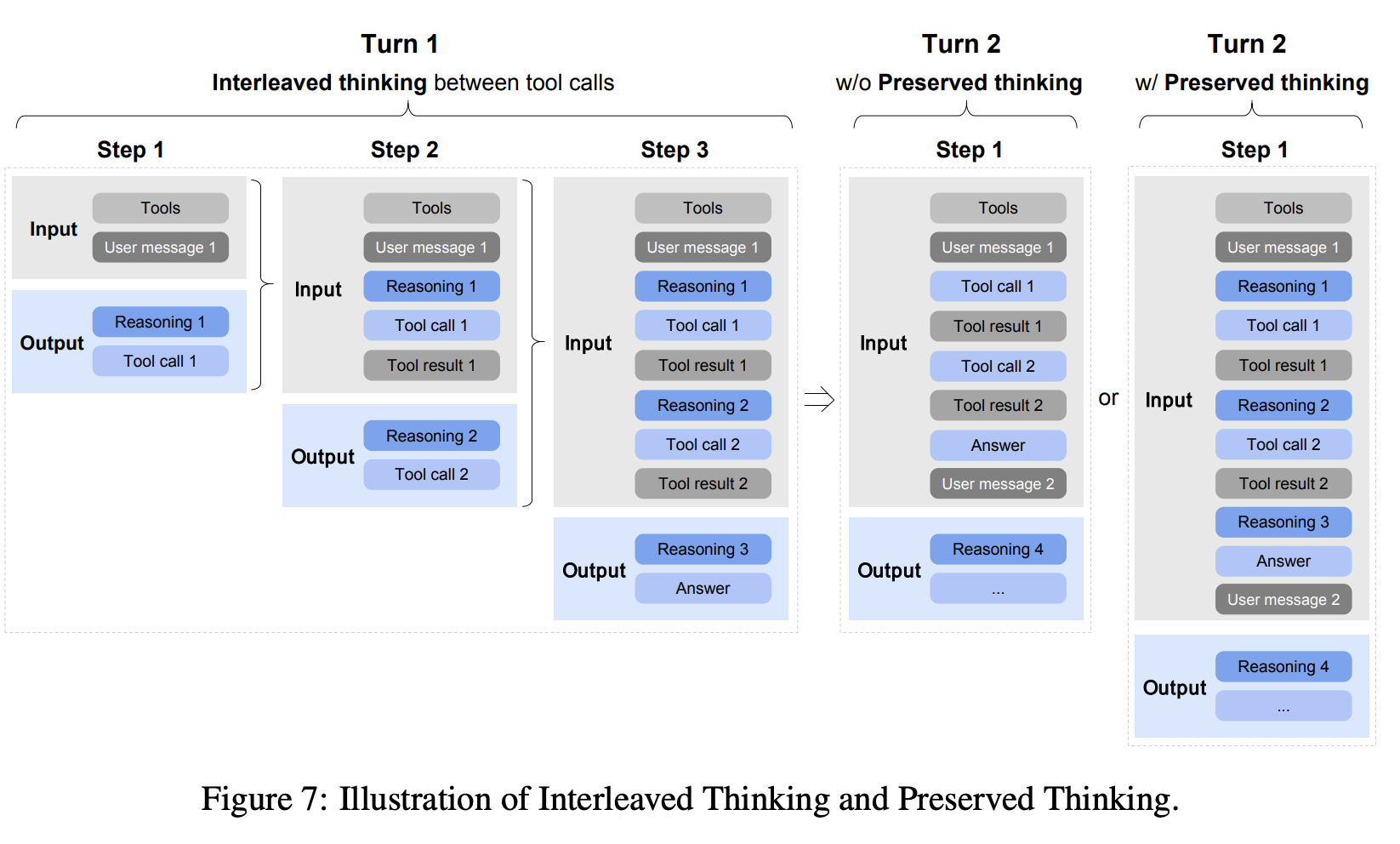
此外,GLM-5 在 SFT 期间将最大上下文长度扩展至 202,752 个 token。该模型除了更新聊天模板外,还支持三种不同的思维特征(见图 7),包括:
- Interleaved Thinking:该模型在每次响应和工具调用之前都会进行思考,从而提高指令执行效率和生成质量。
- Preserved Thinking:在编码 Agent 场景中,该模型能够自动保留多轮对话中的所有思维模块,重用现有推理过程,而不是从头开始重新推导。这减少了信息丢失和不一致,非常适合长期、复杂的任务。
- Turn-level Thinking:该模型支持对会话中的推理进行逐回合控制——对于轻量级请求禁用推理以降低延迟/成本,对于复杂任务启用推理以提高准确性和稳定性。
GLM-5 通过在行动之间进行思考并保持回合间的一致性,在复杂任务中实现了更稳定、更可控的行为。
对于 General Chat tasks,我们优化了回复风格,使其比 GLM-4.5 更符合逻辑且简洁。对于角色扮演任务,我们收集并构建了一个涵盖多种语言和角色配置的更广泛、更多样化的数据集。具体而言,我们定义了几个评估维度——包括指令遵循度、语言表达能力、创造性、逻辑连贯性和长对话一致性——并结合自动和人工筛选来整理和优化数据。
对于 Reasoning tasks,我们进一步增强了模型的推理深度。具体而言,对于逻辑推理,我们构建可验证的问题,并使用拒绝抽样法合成高质量数据。对于数学和科学问题,我们应用基于难度的筛选过程,仅保留对 GLM-4.7 模型具有挑战性的问题。
对于 Coding and Agent tasks,与 GLM-4.5 相比,GLM-5 构建了大量的执行环境以获得高质量的轨迹,尤其侧重于真实场景和长周期任务。我们进一步利用专家强化学习和拒绝采样改进了 SFT 数据集。轨迹中的错误片段被保留,但在损失函数中被屏蔽,这使得模型能够在不强化错误行为的情况下学习纠错行为。
3.2 Reasoning RL
RL algorithm backbone。我们的强化学习算法基于GRPO,并结合了 IcePop 技术来缓解训练-推理不匹配问题,即强化学习优化过程中推理分布与训练分布之间的差异。我们明确区分了用于梯度更新的训练策略 和用于轨迹采样的推理策略 。与原始 IcePop 公式相比,我们移除了 KL 正则化项以加速强化学习的改进。最终的优化损失为:
其中,训练-推理不匹配率定义为:
运算符会抑制不匹配率偏差过大的样本:
PPO 式重要性比率和组归一化优势遵循原始 GRPO 定义:
在训练过程中,我们设置超参数 ,,。训练完全 on-policy 进行,组大小为32,批次大小为 32。
DSA RL insights。我们对基于 DSA 架构的模型进行了大规模强化学习训练。与 MLA 相比,DSA引入了一个额外的索引器,用于检索 top-k 个最相关的 key-value 对,并在检索到的子集上稀疏地计算注意力。检索到的 top-k 个结果对于强化学习的稳定性至关重要。这类似于 MoE 模型使用路由重放来保留激活的 top-k 个专家,以确保训练和推理的一致性。然而,直接将此策略应用于索引器重放,即在每个 token 位置存储索引器的 top-k 个索引,显然是不切实际的,因为索引器使用的 远大于MoE中通常使用的 k 值,存储所有这些索引将产生巨大的存储成本以及训练引擎和推理引擎之间显著的通信开销。
我们发现,采用确定性的 top-k 算子能够有效解决 DSA 索引器 token 选择中的训练-推理不匹配问题。与 SGLang 的 DSA 索引器中使用的基于 CUDA 的非确定性 top-k 实现相比,直接使用简单的 torch.topk 虽然速度稍慢,但具有确定性。它能够产生更一致的输出,并带来显著的强化学习 (RL) 性能提升。相比之下,其他非确定性的 top-k 算子(例如 CUDA 或 TileLang 实现)在强化学习过程中仅经过几步训练后就会导致性能急剧下降,熵值也急剧降低。因此,在我们的强化学习阶段,我们将 torch.topk 作为训练引擎中 DSA 索引器的默认 top-k 算子。此外,我们在强化学习过程中默认冻结索引器参数,以加速训练并防止索引器出现不稳定的学习过程。
Mixed domain reasoning RL。在推理强化学习阶段,我们对四个领域进行混合强化学习训练:数学、科学、代码和工具集成推理(TIR)。对于数学和科学领域,我们从开源数据集和与外部标注供应商共同开发的数据集中收集数据。我们进一步应用难度过滤,将训练重点放在 GLM-4.7 很少能正确解决或总是失败的问题上,而这些问题仍然可以被更强大的教师模型(例如 GPT-5.2 xhigh 和 Gemini 3 Pro Preview)解决。对于代码领域,我们涵盖了竞赛编程风格的任务和科学编程任务。前者主要来自 Codeforces 和一些代表性数据集,例如 TACO 和 SYNTHETIC-2-RL,而后者则是通过将问题分解为实现正确答案所需的最小代码实现,从内部问题库中构建而成。对于 TIR,我们重用了数学和科学强化学习数据中更具挑战性的子集,并与标注供应商共同构建专门设计用于使用外部工具回答的 STEM 问题。在强化学习训练过程中,我们为训练模型分配特定领域和来源的评判模型或评估系统,以产生二元结果奖赏。我们保持四个领域之间的整体混合比例大致平衡,并在混合强化学习设置下,在每个领域都观察到稳定且显著的提升。
3.3 Agentic RL
为了提升 GLM-5 的智能体性能,我们开发了一个完全异步且解耦的强化学习框架,并针对编码和搜索智能体任务优化了 GLM-5。传统的同步强化学习在长时域智能体部署过程中会面临严重的 GPU 空闲问题。通过中央多任务部署协调器解耦推理引擎和训练引擎,我们实现了跨多种智能体工作负载的高吞吐量联合训练。
为了在异步 off-policy 条件下保持训练稳定性,我们引入了两个关键机制。首先,Token-in-Token-out (TITO) 网关通过保留精确的动作级对应关系来消除重新 tokenizer 不匹配。其次,我们采用直接双边重要性采样,该采样对展开的对数概率应用 token-level 裁剪机制 (),同时在不跟踪历史策略检查点的情况下有效控制 off-policy 偏差。此外,我们还采用了一种动态规划感知路由,以在大规模 MoE 模型的长上下文推理期间最大化 KV-cache 的重用,从而加速训练。为了扩展智能体环境,我们在三个领域扩展了可验证的训练环境:超过 1 万个真实世界的软件工程 (SWE) 任务、终端任务和高难度多跳搜索任务。有关智能体强化学习的更多细节,请参见后续的第 4 节。
3.4 General RL
Multi-dimensional optimization objectives。我们将通用强化学习的优化目标分解为三个互补的维度:基础正确性、情商和特定任务质量。
基础正确性维度是响应质量的基石。它旨在纠正各种影响模型输出可用性的错误类型,包括指令执行错误、逻辑不一致、事实错误、知识错觉和语言表达不流畅。目标是最大限度地降低错误率,使响应达到可用的基准水平。我们认为这是所有后续优化的先决条件:包含事实错误或误解用户意图的响应,无论其外观多么完美,都可能误导用户。
情商维度在核心正确性之外,进一步优化了用户体验。它旨在生成富有同理心、洞察力强且风格接近自然人际沟通的回复,使用户与模型的互动更加自然流畅,更具吸引力。
任务特定质量维度旨在针对各种特定任务进行精细化优化。它以基础正确性所建立的可用性为基础,力求在每个任务类别中将答案从仅仅正确提升到真正的高质量。该维度涵盖广泛的任务,包括写作、文本处理、主观和客观问答、角色扮演和翻译。每个任务领域都需要不同的奖赏信号,因此需要一个混合奖励系统。
Hybrid reward system。为了监督上述多样化的目标,我们构建了一个混合奖赏系统,该系统整合了三种互补的奖励信号:基于规则的奖赏函数、结果奖赏模型(ORM)和生成式奖赏模型(GRM)。每种模型都有其独特的优势和劣势,它们的结合是实现稳定、高效且可扩展的通用强化学习训练过程的关键。
基于规则的奖赏机制能够提供精确且易于解释的信号,但其作用范围仅限于可以用确定性规则表达的方面。ORM 能够提供低方差的信号和较高的训练效率,但更容易受到奖励机制攻击,即策略利用表面模式而非真正提升核心能力。GRM 利用语言模型生成标量或结构化的评估结果,对这类攻击更具鲁棒性,但往往表现出更高的方差。通过融合这三种信号类型,我们获得了一种能够平衡精确性、效率和鲁棒性的奖励系统,从而弥补了任何单一组件的不足。
Human-in-the-loop style alignment。我们通用强化学习流程的一个显著特点是明确地融入了高质量的人工撰写的回复。我们并非仅仅依赖模型生成的回复,而是引入专家撰写的回复作为风格和质量的参考标准。这是基于这样的观察:纯粹由模型生成的优化往往会趋向于明显的“模型式”模式——通常冗长、公式化,或者缺乏熟练人类写作的细微差别。通过让模型接触人工撰写的范例,我们鼓励它采用更自然、更符合人类习惯的回复模式。
3.5 On-Policy Cross-Stage Distillation
在我们的多阶段强化学习流程中,针对不同目标进行顺序优化会导致先前习得能力的累积退化。为了缓解这个问题,我们在最后阶段执行 on-policy 跨阶段蒸馏,采用 on-policy 蒸馏算法来快速恢复在早期 SFT 和强化学习阶段(推理强化学习和通用强化学习)习得的技能。
具体来说,前几个训练阶段的最终检查点用作 teacher 模型,训练提示从相应教师的强化学习训练集中采样,并按适当比例混合。训练损失可以通过将公式 1 中的优势项替换为以下公式来获得(“sg”表示停止梯度操作,例如,.detach()):
目前,我们利用推理引擎获取教师模型的 logits。未来,我们计划将推理后端迁移到训练引擎,并统一采用 MLA 的多查询注意力(MQA)模式进行推理()。训练过程中,GRPO 算法中的组大小设置为1以提高数据吞吐量,批大小设置为1024。现阶段这样做是可行的,因为不再需要为每个提示维护大量的样本来估计优势;优势可以直接通过与教师模型的差距来计算。
3.6 RL Training Infrastructure: The slime Framework
我们继续使用 slime 作为 GLM-5 的统一后训练基础设施,从而实现大规模端到端强化学习 (RL)。GLM-5 没有引入新的系统组件,而是充分利用 slime 的各项功能,(1) 通过自由形式的部署定制和基于服务器的执行模型扩展任务覆盖范围;(2) 通过混合精度训练/部署以及 MTP 和预填充解码 (PD) 分解显著提高吞吐量——尤其适用于多轮强化学习工作负载;(3) 通过心跳驱动的部署容错和路由器级服务器生命周期管理提高鲁棒性。
3.6.1 Scaling Out: Flexible Training via Highly Customizable Rollouts
3.6.2 Scaling Up: Tail-Latency Optimization for RL Rollouts
3.6.3 Rollout Robustness: Heartbeat-Driven Fault Tolerance
4.Agentic Engineering
本届描述了从 “vibe coding”(人工提示)到智能体工程的转变。在 vibe coding 中,人类提示人工智能模型编写代码。而在智能体工程中,人工智能体自行编写代码。它们进行规划、实现和迭代。为了支持这些长期任务,GLM-5 采用完全异步和解耦的强化学习框架,通过减少智能体部署期间的空闲时间,显著提升了 GPU 利用率。为了扩展智能体环境,我们开发了环境构建流水线。对于编码任务,我们创建了超过 10,000 个可验证的训练场景,模拟了真实世界的软件工程问题和最终任务。对于搜索智能体,我们开发了一个自动且可扩展的复杂多步骤推理数据合成流水线,用于构建智能体训练数据。
4.1 Asynchronous RL for Agentic Tasks
为了对智能体任务进行强化学习,我们设计了一个完全异步和解耦的强化学习基础设施,可以高效地处理长期智能体部署,并支持跨不同智能体框架的灵活多任务强化学习训练。
我们采用分组策略优化算法进行强化学习训练。对于每个问题 ,我们从前一个策略 中采样 K 个智能体轨迹 ,并针对以下目标优化模型 :
其中 是采样响应的平均奖赏。需要注意的是,优化过程中仅使用模型生成的 token,损失计算中忽略了环境反馈。
4.1.1 Asynchronous RL Design for Agentic Training
由于部署过程具有长尾特性,原生的同步强化学习训练在部署阶段会因智能体任务生成严重不平衡而引入大量“气泡”,导致GPU空闲时间过长。为了提高训练吞吐量,我们采用完全异步的智能体强化学习训练范式来提升GPU利用率和训练效率。具体来说,我们将训练引擎和推理引擎解耦到不同的GPU设备上。推理引擎持续生成轨迹。一旦生成的轨迹数量达到预设阈值,该批次轨迹就会被发送到训练引擎以更新模型。为了减少策略延迟并保持训练大致符合策略,部署引擎使用的模型权重会定期与训练引擎的权重同步。训练引擎每进行 K 次梯度更新,就会更新模型参数并将新的权重推送回推理引擎。虽然异步训练可以显著提高整体训练效率,但也意味着不同的模型版本可能会生成不同的轨迹,从而引入严重的偏离策略问题。由于权重更新会因部署策略的变化而考虑不同的优化问题,因此我们在推理引擎每次权重更新后都会重置优化器。
Server-based multi-task training design。为了解决多任务强化学习中轨迹生成的异构性问题(不同任务通常依赖于不同的工具集和任务特定的部署逻辑),我们引入了一个基于服务器的多任务部署编排器,用于多任务强化学习训练。该组件旨在通过一个拥有多个已注册任务服务的中央编排器,确保 slime 强化学习训练框架与各种下游任务之间的无缝兼容性。具体来说,每个任务都以独立微服务的形式实现自身的部署和奖赏逻辑,并注册到中央编排器进行管理和调度。在部署阶段,中央编排器控制每个任务的部署比例和生成速度,以实现跨任务的均衡数据采集。至关重要的是,我们将所有智能体任务的轨迹标准化为统一的消息列表表示。这使得复杂智能体框架(例如软件工程任务)能够进行联合训练,同时支持对异构工作负载进行集中式后处理和日志记录。这种设计将任务特定的逻辑与核心训练循环清晰地隔离开来,从而实现了与多任务强化学习训练的无缝集成。作为 GLM-5 训练基础设施的骨干,该协调器支持超过 1000 个并发部署,并可自动、动态地调整任务采样率,以及对任务进度进行精细监控。
4.1.2 Optimizing Asynchronous Training Stability
Token-in-Token-out vs. Text-in-Text-out。在强化学习的 rollout 设置中,token-in-token-out (TITO) 指的是训练流程直接使用推理引擎生成的精确分词和解码后的 token 流来构建学习轨迹。相比之下,text-in-text-out 将 rollout 引擎视为一个黑盒,它返回最终的文本;训练器随后通过重新分词(通常还需要重新计算边界和截断)来重建轨迹,然后再计算损失。这种看似微小的选择却至关重要:重新分词可能会在 token 边界、空格/归一化处理、截断或特殊 token 放置等方面引入细微的不匹配,进而破坏动作与奖励/优势之间的步长对齐——尤其是在 rollouts 被流式传输、截断或交错地分配给多个参与者时。我们发现,对于异步强化学习训练而言,token-in-token-out (TITO) 机制至关重要,因为它能够精确地保留采样内容与优化内容之间的动作级对应关系,同时允许参与者立即发出轨迹片段(token ID + 元数据),而无需进行有损的文本往返传输,也无需等待学习器端进行事后重新分词。在实践中,我们实现了一个 TITO 网关,用于拦截来自部署任务的所有生成请求,并记录每个轨迹的 token ID 和元数据。这种设计将繁琐的 token ID 处理与下游 Agent rollout 逻辑隔离开来,同时避免了强化学习训练期间的重新分词不匹配。
Direct double-sided importance sampling for token clipping。与第 3 节中的同步强化学习训练设置不同,在异步设置中,rollout 引擎在单次轨迹生成过程中可能会经历多次更新,这使得精确跟踪行为概率 在计算上变得极其困难。否则,我们需要维护一个庞大的模型检查点历史记录 ,这在实际应用中是不可行的。
为了解决这个问题,我们首先采用了一种简化的 token 级重要性采样机制,该机制重用了在 rollot 过程中生成的对数概率作为直接行为代理。通过计算重要性采样率 并舍弃传统的 ,我们消除了单独进行旧策略推理的计算开销。其次,我们采用了一种双边校准的 token 级掩码策略。与标准 PPO 中使用的非对称裁剪不同,我们将信赖域限制在 内,其中 和 是裁剪超参数。落在该区间之外的 token 将被完全屏蔽,不参与梯度计算,以防止极端策略发散导致的不稳定性。这与 IcePop 机制有相似之处,但我们的策略更简洁,因为它进一步移除了 ,并实现了更稳定的训练。
形式上,采用 token 级裁剪的优化目标可以写成:
在此公式中,重要性抽样率 计算如下:
通过校准函数 进一步增强稳定性:
实验表明,重用 rollout 对数概率可以接受一定程度的离策略偏差,从而避免对历史策略进行跟踪,同时提高训练稳定性。
Dropping off-policy and noisy samples。在异步强化学习(asynchronous RL)中,过长的轨迹可能会变得高度离策略,从而使训练不稳定。为过滤这些严重离策略的样本,我们在生成时记录 rollout 引擎所使用的策略权重版本。具体而言,对于每个响应,我们记录参与生成的模型版本序列 ,其中 。设 表示当前策略版本。如果某个样本的最早 rollout 版本过旧,则将其丢弃,即当 时,其中 是一个预定义的阈值。这样可以移除那些相对于当前策略滞后过多的轨迹。
此外,编码代理(coding-agent)的沙箱环境本身可能不稳定,并且可能由于与模型无关的原因而失败(例如环境崩溃)。此类失败会引入噪声训练信号,因为它们反映的是环境不稳定,而不是模型能力。为缓解这一问题,我们为每个样本记录失败原因,并排除由于环境崩溃导致失败的样本。对于像 GRPO 这样的基于分组的采样方法,移除失败样本可能会导致分组不完整。在这种情况下,如果有效样本数量超过该组大小的一半,我们通过重复有效样本对该组进行填充;否则,我们丢弃整个分组。该过程减少了虚假的奖励噪声,并提高了训练稳定性。
DP-aware routing for acceleration。我们提出一种 DP 感知的路由机制,以在数据并行(Data Parallelism,DP)的大规模 MoE 推理中保持 KV cache 的局部性。在多轮代理(agentic)工作负载中,同一 rollout 的连续请求会共享相同的前缀。为了最大化 KV 复用,我们强制执行 rollout 级别的亲和性:属于同一 agent 实例的所有请求都会被路由到同一个 DP rank。具体来说,我们引入一个有状态的路由层,通过一致性哈希(consistent hashing)将每个 rollout ID 映射到一个固定的 DP rank。该映射在多轮交互之间保持稳定,从而消除跨 rank 的缓存未命中。
为了防止长期负载不均衡,我们将哈希与对哈希空间的轻量级动态负载均衡相结合。该设计避免了冗余的 prefill 计算,同时无需在不同 DP rank 之间进行 KV 同步。随着 rollout 长度增加,prefill 成本保持与增量 token 成正比,而不是与总上下文长度成正比。最终结果是:在长上下文的 agent 推理场景中,端到端延迟得到改善,同时有效吞吐量也更高。
4.2 Environment Scaling for Agents
为了支持各种智能体任务中的强化学习,我们构建了可验证、可执行的环境,为以代码为中心和以内容生成为中心的工作流程提供基于实际情况的反馈。对于智能体编码任务,我们开发了两个环境构建流程,用于构建可验证的可执行环境:一个是基于真实软件工程问题构建的环境设置流程,另一个是用于终端智能体环境的合成流程。除了编码之外,我们还引入了一个幻灯片生成环境,在该环境中,智能体可以对结构化的 HTML 进行操作,并进行可执行的渲染和基于布局的验证。