论文链接:https://arxiv.org/pdf/2503.20215
代码链接:https://github.com/QwenLM/Qwen2.5-Omni
摘要
在本报告中,我们介绍了 Qwen2.5-Omni,这是一个端到端的多模态模型,旨在感知多种模态,包括文本、图像、音频和视频,同时以流式传输的方式生成文本和自然语音响应。为了实现多模态信息输入的流式传输,音频和视觉编码器均采用了分块处理方法。该策略有效地解耦了长序列多模态数据的处理,将感知任务分配给多模态编码器,并将扩展序列的建模委托给大语言模型。这种分工通过共享注意力机制增强了不同模态的融合。为了同步视频输入和音频的时间戳,我们以交错的方式按顺序组织音频和视频,并提出了一种新的位置嵌入方法,称为 TMRoPE(时间对齐多模态 RoPE)。为了同时生成文本和语音,同时避免两种模态之间的干扰,我们提出了 Thinker-Talker 架构。在这个框架中,Thinker 是一个大语言模型,负责文本生成;而 Talker 是一个双轨自回归模型,它直接利用 Thinker 的隐藏表征生成音频 token 作为输出。Thinker 和 Talker 模型均设计为端到端训练和推理。为了以流式方式解码音频 token,我们引入了一个滑动窗口 DiT 来限制感受野,旨在减少初始数据包延迟。Qwen2.5-Omni 与类似大小的 Qwen2.5-VL 相当,并且优于 Qwen2-Audio。此外,Qwen2.5-Omni 在 Omni-Bench 等多模态基准测试中达到了最佳性能。值得注意的是,Qwen2.5-Omni 在端到端语音指令遵循方面的表现与其在文本输入方面的能力相当,MMLU 和 GSM8K 等基准测试就是明证。在语音生成方面,Qwen2.5-Omni 的流式 Talker 在稳健性和自然性方面优于大多数现有的流式和非流式替代方案。
1.介绍
在日常生活中,人类能够同时感知周围的视觉和听觉信息。经过大脑处理后,人类会通过书写、发声或使用工具(以及肢体动作)进行反馈,从而与世界上各种生物进行信息交换,展现出智能。近年来,通用人工智能日益受到人们的关注,这主要得益于大语言模型 (LLM) 的进步。这些模型基于海量文本数据进行训练,代表了人类创造的高级离散表征,展现了解决复杂问题和快速学习的能力。此外,在理解领域,语言-听觉-语言模型 (LALM) 和语言-视觉-语言模型 (LVLM) 帮助 LLM 以端到端的方式进一步扩展了听觉和视觉能力。然而,如何高效地以端到端的方式统一所有这些不同的理解模式,充分利用数据,并以类似于人类交流的文本和语音流提供响应,仍然是一项重大挑战。
开发统一智能的全模态模型需要仔细考虑几个关键因素。首先,必须实现一种系统的方法,对文本、图像、视频和音频等各种模态进行联合训练,以促进它们之间的相互增强。这种协调对于视频内容尤为重要,因为视频内容需要同步音频和视频信号的时间方面。其次,必须管理不同模态输出之间的潜在干扰,确保文本和语音 token 等输出的训练过程不会相互干扰。最后,需要探索能够实时理解多模态信息并实现高效音频输出流的架构设计,从而减少初始延迟。
在本报告中,我们介绍了 Qwen2.5-Omni,这是一个统一的单模型,能够处理多种模态,并以流格式同时生成文本和自然语音响应。为了应对第一个挑战,我们提出了一种新的位置嵌入方法,称为 TMRoPE(Time-aligned Multimodal RoPE)。我们将这些音频和视频帧组织成交错结构,以按时间顺序表示视频序列。对于第二个挑战,我们提出了 Thinker-Talker 架构,其中 Thinker 负责文本生成,而 Talker 专注于生成流式语音 token。Talker 直接从 Thinker 接收高级表示。这种设计的灵感来自于人类利用不同器官产生各种信号的方式,这些信号同时通过相同的神经网络进行协调。因此,Thinker-Talker 架构是端到端联合训练的,每个组件专用于生成不同的信号。为了应对流式传输带来的挑战,并促进实时理解多模态信号所需的预填充,我们建议对所有多模态编码器进行修改,采用分块流式处理方法。为了支持流式语音生成,我们实现了一个双轨自回归模型来生成语音 token,以及一个DiT模型来将这些 token 转换为波形,从而实现流式音频生成并最大限度地减少初始延迟。此设计旨在使模型能够实时处理多模态信息并有效地进行预填充,从而实现文本和语音信号的并发生成。
Qwen2.5-Omni 与规模相近的 Qwen2.5-VL 性能相当,并在图像和音频性能方面优于 Qwen2-Audio。此外,Qwen2.5-Omni 在 OmniBench 和 AV-Odyssey Bench 等多模态基准测试中取得了最佳性能。值得注意的是,Qwen2.5-Omni 在端到端语音指令遵循方面的表现与其在文本输入方面的表现相当,这在 MMLU 和 GSM8K 等基准测试中得到了证实。在语音生成方面,Qwen2.5-Omni 在 seed-tts-eval test-zh、test-en 和 test-hard 集上分别实现了 1.42%、2.33% 和 6.54% 的字错误率 (WER),优于 MaskGCT 和 CosyVoice 2。
Qwen2.5-Omni 的主要特点可以概括为:
- 我们推出了 Qwen2.5-Omni,这是一个统一的模型,可以感知所有模态并以流式方式同时生成文本和自然语音响应。
- 我们提出了一种新的位置嵌入算法,称为 TMRoPE,它明确地结合了时间信息来同步音频和视频。
- 我们提出了 架构来促进实Thinker-Talker 时理解和语音生成。
- 与规模相近的单模态模型相比,Qwen2.5-Omni 在所有模态上均展现出强劲的性能。它显著提升了语音指令的执行能力,达到了与纯文本输入相当的性能水平。对于涉及多模态整合的任务,例如在 OmniBench 中评估的任务,Qwen2.5-Omni 达到了最佳性能。值得注意的是,Qwen2.5-Omni 在 seed-tts-eval 上表现出色,展现出强大的语音生成能力。
2.Architecture
2.1 Overview
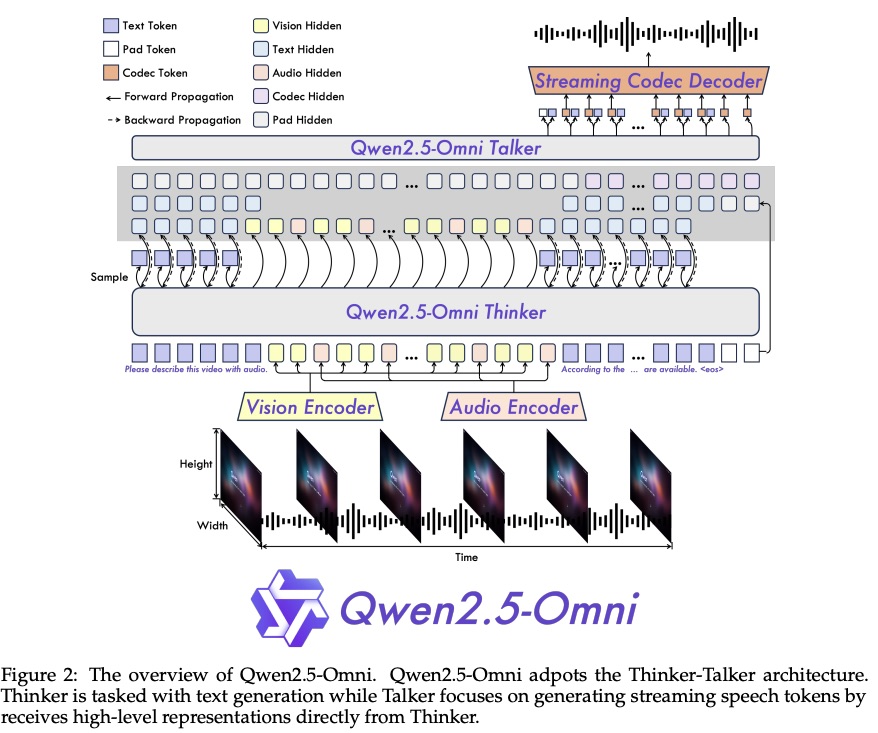
如图 2 所示,Qwen2.5-Omni 采用 Thinker-Talker 架构。Thinker 的功能类似于大脑,负责处理和理解来自文本、音频和视频模态的输入,生成高级表征和相应的文本。Talker 的运作类似于人类的嘴巴,以流式方式接收 Thinker 生成的高级表征和文本,并流畅地输出离散的语音 token。Thinker 是一个 Transformer 解码器,并配有音频和图像编码器,用于信息提取。相比之下,Talker 的设计灵感源自 Mini-Omni,是一个双轨自回归 Transformer 解码器架构。在训练和推理过程中,Talker 直接从 Thinker 接收高维表征,并共享 Thinker 的所有历史上下文信息。因此,整个架构作为一个统一的模型运行,实现端到端的训练和推理。
在接下来的章节中,我们首先介绍 Qwen2.5-Omni 如何感知各种输入信号,并介绍我们提出的新型位置编码算法 TMRoPE。随后,我们将详细介绍文本和语音的生成过程。最后,我们将重点介绍理解和生成模块的改进,以促进高效的流式推理。
2.2 Perceivation
Text, Audio, Image and Video (w/o Audio)。Thinker 通过将文本、音频、图像和视频(不含音轨)转换为一系列隐藏表征来处理输入。对于文本的分词,我们使用 Qwen 的 tokenizer,它采用字节级字节对编码,词表包含 151,643 个常规分词。对于音频输入和视频音频,我们将其重采样至 16kHz 频率,并将原始波形转换为 128 通道梅尔频谱图,窗口大小为 25ms,跳频大小为 10ms。我们采用 Qwen2-Audio 的音频编码器,使每帧音频表征大致对应于原始音频信号的 40ms 片段。此外,我们还采用了 Qwen2.5-VL 的视觉编码器,该编码器基于 Vision Transformer (ViT) 模型,拥有约 6.75 亿个参数,能够有效处理图像和视频输入。视觉编码器采用融合图像和视频数据的混合训练方案,确保图像理解和视频理解的熟练程度。为了在适应音频采样率的同时尽可能完整地保留视频信息,我们使用动态帧率对视频进行采样。此外,为了保持一致性,我们将每幅图像视为两个相同的帧。
“此外,为了保持一致性,每张图像被当作两个完全相同的帧来处理。” 意思是:他们把“图像”和“视频”统一按“帧序列”的形式送进同一个视觉编码器。 视频天然有多帧,而静态图像只有一帧。如果直接用单帧,输入张量的时间维度会与视频样本不一致。为了让图像样本在形状上与视频样本对齐(便于批处理、位置编码、时序建模等),他们把同一张静态图像复制一次,拼成“两帧的短视频”,两帧内容完全相同。这样模型看到的所有视觉输入——无论原本是一张图还是一段视频——都会拥有至少两帧的时间维度,保持输入格式的一致性。
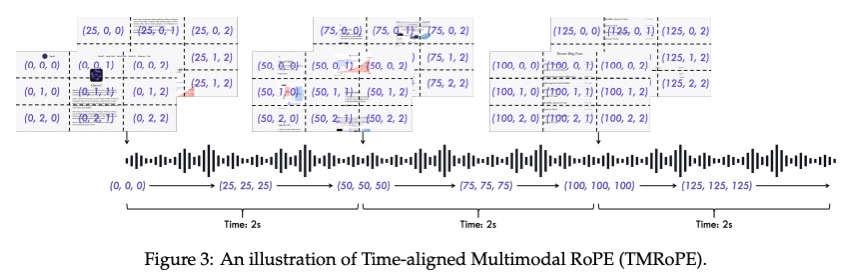
Video and TMRoPE。我们提出了一种用于音频和视频的时间交织算法,以及一种新的位置编码方法。如图 3 所示,TMRoPE 对多模态输入的三维位置信息进行编码,即具有绝对时间位置的多模态旋转位置嵌入 (M-RoPE)。这是通过将原始旋转嵌入解构为三个分量(时间、高度和宽度)来实现的。对于文本输入,这些分量使用相同的位置 ID,使得 M-RoPE 在功能上等同于 1D-RoPE。同样,对于音频输入,我们也使用相同的位置 ID,并引入绝对时间位置编码,其中一个时间 ID 对应 40 毫秒。
在处理图像时,每个视觉token的时间ID保持不变,而高度和宽度组件则根据其在图像中的位置分配不同的ID。当输入为带音频的视频时,音频仍然以每帧40毫秒相同的位置ID进行编码,视频则被视为一系列图像,其时间ID会逐帧递增,而高度和宽度组件则遵循与图像相同的ID分配模式。由于视频的帧速率不固定,我们根据每帧对应的实际时间动态调整帧之间的时间ID,以确保一个时间ID对应40毫秒。在模型输入包含多个模态的场景中,每个模态的位置编号通过将前一个模态的最大位置ID加1来初始化。TMRoPE增强了位置信息建模,最大限度地整合了各种模态,使Qwen2.5-Omni能够同时理解和分析来自多个模态的信息。
将位置信息融入每个模态后,我们按顺序排列这些表征。为了使模型能够同时接收视觉和听觉信息,如图 3 所示,我们针对带音频的视频设计了一种称为时间交织方法的特殊方法,该方法根据实际时间每 2 秒将带音频的视频中的表征分割成多个块。然后,我们将视觉表征排列在最前面,音频表征排列在最后,并在 2 秒内将视频和音频的表征交织在一起。
2.3 Generation
Text。文本由 Thinker 直接生成。文本生成的逻辑与广泛使用的 LLM 基本相同,后者通过基于词表概率分布的自回归采样来生成文本。生成过程可能采用重复惩罚和 top-p 采样等技术来增强文本的多样性。
Speech。Talker 接收 Thinker 采样的文本 token 的高级表示和嵌入。在此背景下,高维表示与离散采样 token 的集成至关重要。作为一种流式算法,语音生成必须在完整生成文本之前预测内容的语气和态度。Thinker 提供的高维表示隐式地传达了这些信息,从而实现了更自然的流式生成过程。此外,Thinker 的表示主要表达表征空间中的语义相似性,而非语音相似性。因此,即使是语音上不同的单词也可能具有非常相似的高级表示,因此需要输入采样的离散 token 来消除这种不确定性。
我们设计了一个名为 qwen-tts-tokenizer 的高效语音编解码器。qwen-tts-tokenizer 能够高效地表示语音的关键信息,并可通过因果音频解码器以流式方式解码为语音。接收信息后,Talker 开始自回归生成音频 token 和文本 token。语音生成无需与文本进行词级和时间戳级对齐。这显著简化了对训练数据和推理过程的要求。
2.4 Designs for Streaming
在流式音视频交互的背景下,初始数据包延迟是系统流式传输性能的关键指标。该延迟受以下几个因素影响:1)处理多模态信息输入造成的延迟;2)从接收到第一个文本输入到输出第一个语音 token 的延迟;3)将第一段语音转换为音频的延迟;以及 4)架构本身的固有延迟,这与模型大小、计算 FLOP 和其他因素有关。本文随后将讨论为降低这四个维度的延迟而进行的算法和架构改进。
Support Prefilling。分块预填充是现代推理框架中广泛使用的一种机制。为了在模态交互中支持该机制,我们修改了音频和视觉编码器,使其支持沿时间维度的分块注意力机制。具体而言,音频编码器的注意力机制从覆盖整个音频的完全注意力机制更改为以每 2 秒为一个分块的方式进行注意力机制。视觉编码器利用 flash attention 机制,通过一个简单的多层感知器 (MLP) 层进行高效的训练和推理,该层将相邻的 2×2 个 token 合并为一个 token。块大小设置为 14,允许将不同分辨率的图像打包成一个序列。
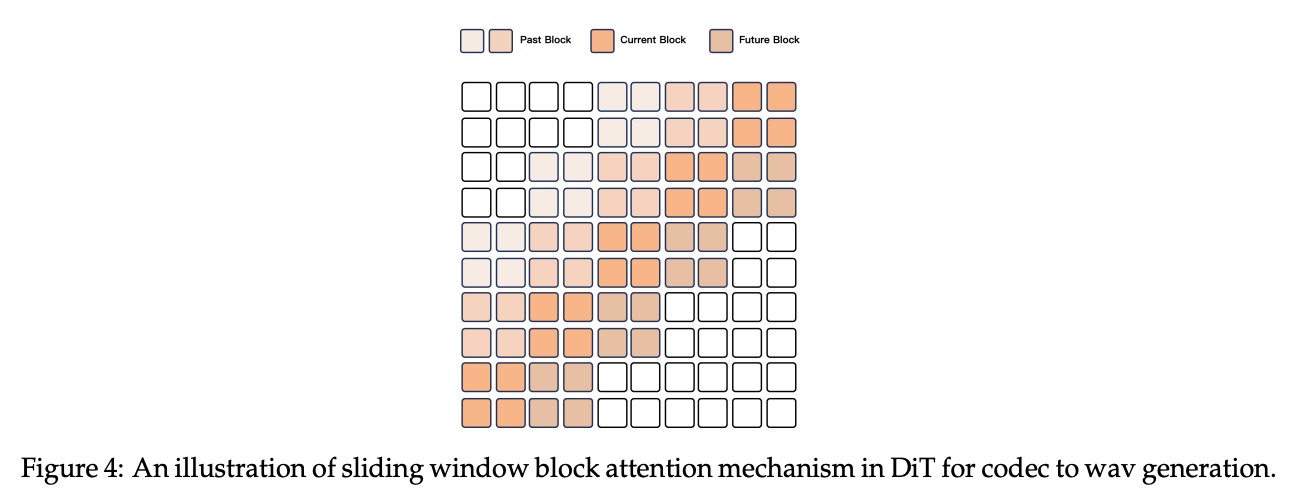
Streaming Codec Generation。为了方便音频流传输,尤其是对于扩展序列,我们提出了一种滑动窗口块注意力机制,该机制将当前 token 的访问限制在有限的上下文中。具体来说,我们利用了 Flow-Matching DiT 模型。输入 code 首先使用流匹配转换为梅尔谱图,然后使用改进的 BigVGAN 将生成的梅尔谱图重建为波形。
如图 4 所示,为了从 code 生成波形,我们将相邻的 code 分组为块,并将其用作注意力掩码。我们将 DiT 的感受野限制为 4 个块,其中包括 2 个块的回溯和 1 个块的前瞻。在解码过程中,我们使用流匹配以块为单位生成梅尔谱,确保每个代码块都能访问必要的上下文块。这种方法通过保留上下文信息来提高流输出的质量。我们还将这种逐块方法应用于 BigVGAN 的固定感受野,以促进流波形的生成。
3. Pre-training
Qwen2.5-Omni 包含三个训练阶段。在第一阶段,我们固定住 LLM 参数,专注于训练视觉编码器和音频编码器,利用大量的音频-文本和图像-文本对语料库来增强 LLM 中的语义理解。在第二阶段,我们解冻所有参数,并使用更广泛的多模态数据进行训练,以实现更全面的学习。在最后阶段,我们使用序列长度为 32k 的数据来增强模型理解复杂长序列数据的能力。
该模型在包含图片-文本、视频-文本、视频-音频、音频-文本以及文本语料库等多种类型的数据集上进行了预训练。我们将层级标签替换为遵循 Qwen2-Audio 的自然语言提示,从而提升了泛化能力和指令遵循能力。
在初始预训练阶段,Qwen2.5-Omni 的 LLM 组件使用 Qwen2.5 的参数进行初始化,视觉编码器与 Qwen2.5-VL 相同,音频编码器则使用 Whisper-large-v3 进行初始化。两个编码器分别在固定的 LLM 上进行训练,在训练编码器之前,它们都首先专注于训练各自的 adapter。这项基础训练对于使模型对核心的视觉-文本和音频-文本相关性及对齐方式建立稳健的理解至关重要。
预训练的第二阶段标志着一项重大进展,它新增了 8000 亿个图像和视频相关数据、3000 亿个音频相关数据以及 1000 亿个视频和音频相关数据。此阶段引入了更大规模的混合多模态数据和更广泛的任务,从而增强了交互性,并加深了听觉、视觉和文本信息之间的理解。引入多模态、多任务数据集对于开发模型同时处理多任务和多模态的能力至关重要,而这正是管理复杂的现实世界数据集的关键能力。此外,纯文本数据在维持和提高语言能力方面也发挥着至关重要的作用。
为了提高训练效率,我们在前几个阶段将最大 token 长度限制为 8192 个 token。之后,我们引入长音频和长视频数据,将原始文本、音频、图像和视频数据扩展至 32,768 个 token 进行训练。实验结果表明,我们的数据在支持长序列数据方面取得了显著提升。
4.Post-training
4.1 Data Format
The Dataset Format Example of ChatML <|im_start|>user <|vision_start|>Video.mp4 [Two people are talking in the video]<|vision_end|>What are the people in the video saying?<|im_end|> <|im_start|>assistant Both pictures are of SpongeBob SquarePants.The person in the red clothes says, “Hello, how’s the weather today?” The person in the black clothes responds, “Hello, the weather is quite nice today.”<|im_end|> <|im_start|>user <|vision_start|>Video.mp4 [A person in the video is saying, “Please describe the person in front of you.”]<|vision_end|><|im_end|> <|im_start|>assistant The person in front of you is wearing glasses and a brown jacket over a blue shirt. They appear to be speaking or reacting to something, as their mouth is open and they seem engaged. The background shows a room with a wall-mounted air conditioner, a clothing rack with various garments hanging on it, and a large screen displaying an image of a cityscape at night. The lighting in the room is warm and cozy.<|im_end|>
4.2 Thinker
在后训练阶段,我们使用 ChatML 格式的指令遵循数据进行指令微调。我们的数据集包含纯文本对话数据、视觉模态对话数据、音频模态对话数据和混合模态对话数据。
4.3 Talker
我们为 Talker 设计了三阶段训练流程,使 Qwen2.5‑Omni 能够同时生成文本与语音回复。
- 阶段一:训练 Talker 学习上下文续写。
- 阶段二:引入 DPO 以提高语音生成的稳定性。
- 阶段三:进行多说话人指令微调,进一步增强语音输出的自然度与可控性。
在 In‑Context Learning (ICL) 训练阶段,除了采用与 Thinker 类似的文本监督外,我们还通过下一 token 预测执行语音续写任务,利用大量融合多模态上下文与口语回应的对话数据。Talker 学会将语义表示单调映射到语音,并能在韵律、情感、口音等多维属性上做出符合语境的表达。此外,我们使用音色解耦技术,防止模型把特定声音与低频文本模式绑定。
为覆盖更多说话人和场景,预训练数据难免含有标签噪声与发音错误,易导致模型幻觉。为缓解该问题,我们引入强化学习阶段来提升语音生成的稳定性。具体而言,对每条 请求–回复文本 及其 参考语音,构建数据集 :其中 为输入文本序列, 与 分别是优质与劣质的生成语音序列。我们依据与 词错误率(WER) 和 标点停顿错误率 相关的奖励分对样本进行排序。
最后,我们在上述基座模型上执行 说话人微调,使 Talker 能够采样特定声音,并进一步提升语音自然度。