论文链接:https://arxiv.org/pdf/2507.18071
代码链接:
摘要
本文介绍了一种稳定、高效且性能优异的强化学习算法——组序列策略优化(GSPO),用于训练大语言模型。与以往采用 token 级重要性比率的算法不同,GSPO 基于序列似然定义重要性比率,并执行序列级裁剪、奖赏和优化。我们证明,与 GRPO 算法相比,GSPO 具有更高的训练效率和性能,显著提高了混合专家(MoE)强化学习训练的稳定性,并有望简化强化学习基础设施的设计。GSPO 的这些优势促成了最新 Qwen3 模型性能的显著提升。
1.介绍
强化学习(RL)已成为扩展大语言模型的关键范式。通过大规模强化学习,语言模型能够进行更深层次、更长时间的推理过程,从而发展出解决复杂问题的能力,例如竞赛级别的数学和编程问题。
为了成功地利用更大的计算资源扩展强化学习(RL),首要前提是保持稳定且稳健的训练动态。然而,目前最先进的强化学习算法,例如GRPO,在训练庞大的语言模型时表现出严重的稳定性问题,常常导致灾难性的、不可逆的模型崩溃。这种不稳定性阻碍了通过持续的强化学习训练来拓展语言模型能力的努力。
本文指出,GRPO 的不稳定性源于其算法设计中重要性采样权重的根本性误用和无效化。这引入了高方差的训练噪声,该噪声会随着响应长度的增加而逐渐累积,并被截断机制进一步放大,最终导致模型崩溃。
为了解决这些核心局限性,我们提出了 Group Sequence Policy Optimization (GSPO),一种用于训练大语言模型的新型强化学习算法。GSPO 的关键创新之处在于其基于序列似然的重要比率的理论定义,这与重要性采样的基本原理相一致。此外,GSPO 将归一化奖赏计算为对同一 query 的多个响应的优势函数,从而确保了序列级奖赏与优化之间的一致性。
我们的实证评估表明,GSPO 在训练稳定性、效率和性能方面均显著优于 GRPO。至关重要的是,GSPO 从根本上解决了大型混合专家 (MoE) 模型强化学习 (RL) 训练中的稳定性挑战,无需复杂的稳定策略,并展现出简化 RL 基础设施的潜力。GSPO 的这些优势最终促成了最新 Qwen3 模型性能的显著提升。我们设想 GSPO 将成为一个稳健且可扩展的算法基础,从而推动基于语言模型的大规模 RL 训练的持续发展。
2.Preliminaries
Notation。本文定义了一个由参数 参数化的自回归语言模型作为策略 。我们用 表示 query, 表示 query 集。给定对 query 的响应 ,其在策略 下的似然表示为 ,其中 表示 中的 token 数。query-response 对 可以由验证器 进行评分,得到奖赏 。
Proximal Policy Optimization (PPO)。利用从旧策略 生成的样本,PPO 通过裁剪机制将策略更新限制在旧策略的邻近区域内。具体来说,PPO 采用以下目标函数进行策略优化(为简洁起见,下文省略 KL 正则化项,因为它并非本文的重点):
其中,token 的重要性比率定义为 , 的优势函数 由另一个 value 模型估计, 是重要性比率的裁剪范围。
PPO在实践中面临的核心挑战在于其对 value 模型的严重依赖。具体而言,value 模型通常与策略模型规模相当,这会带来相当大的内存和计算负担。此外,算法的有效性取决于其 value 估计的可靠性。虽然获取可靠的 value 模型本身就极具挑战性,但确保其能够扩展到更长的响应时间和更复杂的任务则更具挑战性。
Group Relative Policy Optimization (GRPO)。GRPO 通过计算同一 query 的一组响应中每个响应的相对优势,绕过了对 value 模型的需求。具体而言,GRPO优化以下目标:
其中 是针对每个 query 生成的响应数量(即组大小),token 的重要性比率 和优势函数 为:
其中, 中的所有 token 都与具有相同的优势 。
3.Motivation
模型规模、稀疏性(例如,在混合专家模型中)和响应长度的增长,使得强化学习过程中需要更大的 rollout batch size 才能最大限度地利用硬件资源。为了提高样本效率,通常的做法是将一大批 rollout 数据分割成多个小批量进行梯度更新。然而,这种方法不可避免地引入了 off-policy 学习的设置,即响应 是从旧策略 而非当前正在优化的策略 中采样得到的。这也解释了 PPO 和 GRPO 中裁剪机制的必要性,该机制可以防止过多的 off-policy 样本参与梯度估计。
尽管诸如裁剪之类的机制旨在管理这种 off-policy 偏差,但我们发现 GRPO 中存在一个更根本的问题:其目标函数是不适定的。当在长响应任务上训练大型模型时,这个问题尤为突出,会导致灾难性的模型崩溃。GRPO 目标函数的不适定性源于重要性抽样权重的错误应用。重要性抽样的原理是通过对从行为分布 中抽取的样本进行重新加权,来估计目标分布 下函数 的期望值:
关键在于,这依赖于对行为分布 的多个样本 (N ≫ 1) 进行平均,得到重要性权重 ,从而有效地纠正分布不匹配。
相比之下,GRPO 在每个 token 位置 应用重要性权重 。由于该权重基于每个下一个 token 分布 中的单个样本 ,因此它无法发挥预期的分布校正作用。相反,它会在训练梯度中引入高方差噪声,这种噪声会在长序列中累积,并因裁剪机制而加剧。我们通过实验观察到,这会导致模型崩溃,而且这种崩溃通常是不可逆的。一旦发生崩溃,即使回滚到之前的检查点并仔细调整超参数(例如裁剪范围)、延长生成长度或切换强化学习查询,也无法恢复训练。
上述观察揭示了 GRPO 设计中的一个根本性问题。token 级重要性权重的失效指向一个核心原则:优化目标的单位应与奖赏的单位相匹配。由于奖赏是授予整个序列的,因此在 token 级应用 off-polocy 修正似乎存在问题。这促使我们放弃 token 级目标,转而探索利用重要性权重并直接在序列级进行优化。
4.Algorithm
4.1 GSPO: Group Sequence Policy Optimization
虽然在 GRPO 中,token 级重要性权重 存在问题,但我们观察到,在语言生成的背景下,序列级重要性权重 具有明确的理论意义:它反映了从 中采样的响应 与 的偏差程度,这自然与序列级奖赏相一致,也可以作为裁剪机制的有意义的指标。
基于这一简单的观察,我们提出了组序列策略优化(GSPO)算法。GSPO采用以下序列级优化目标:
我们采用基于组的优势估计方法:
并基于序列似然性定义重要性比率 :
因此,GSPO 对整个响应而非单个 token 进行裁剪,以排除过度“偏离策略”的样本,从而避免影响梯度估计,这与序列级奖赏和优化目标相符。需要注意的是,我们对 进行了长度归一化,以降低方差并将其控制在一个统一的数值范围内。否则,少数 token 的似然性变化会导致序列级重要性比率的剧烈波动,而不同长度响应的重要性比率需要不同的裁剪范围。此外,我们还注意到,由于重要性比率的定义不同,GSPO 和之前的算法(例如 GRPO)中的裁剪范围通常在数量级上存在差异。
4.2 Gradient Analysis
我们可以按如下方式推导出 GSPO 目标函数的梯度(为简洁起见,省略了裁剪步骤):
为了进行比较,GRPO 目标函数的梯度如下(注意 ):
因此,GSPO 和 GRPO 的根本区别在于它们如何对 token 的对数似然梯度进行加权。在 GRPO 中,token 根据其各自的重要性权重 进行加权。然而,这些不相等的权重(当 时,其取值范围为 ;当 时,其取值范围为 )不可忽略,并且随着训练的进行,其影响会累积并导致不可预测的后果。相比之下,GSPO 对响应中的所有 token 赋予相同的权重,从而消除了 GRPO 的这种不稳定性因素。
4.3 GSPO-token: A Token-level Objective Variant
在诸如多轮强化学习之类的场景中,我们可能需要比序列级别更精细的优势调整。为此,我们引入了GSPO的 token 级目标变体,即GSPO-token,以允许逐 token 地定制优势:
其中
其中, 表示仅取数值而不计算梯度,对应于 PyTorch 中的 操作。GSPO-token 的梯度可以推导如下:
注意,项 的数值为 1,因此 在数值上等于 。比较公式 (5) 和 (13),以及公式 (10) 和 (17),当响应 中所有 token 的优势值设置为相同值(即 )时,GSPO-token 和 GSPO 在优化目标、裁剪条件和理论梯度方面数值相同,但 GSPO-token 具有更高的灵活性,可以调整每个 token 的优势值。
5.Experiments and Discussion
5.1 Empirical Results
5.2 Curious Observation on Clipping Fractions
5.3 Benefit of GSPO for MoE Training
Background。与密集模型的强化学习训练相比,MoE 模型的稀疏激活特性带来了独特的稳定性挑战。特别是,我们发现,当采用GRPO 算法时,MoE 模型的专家激活波动性会阻碍强化学习训练的正常收敛。具体而言,经过一次或多次梯度更新后,针对同一响应激活的专家可能会发生显著变化。例如,对于48层的 Qwen3-30B-A3B-Base 模型,在每次强化学习梯度更新后,对于相同的 rollout 样本,在新策略 下激活的专家与在旧策略 下激活的专家相比,大约有 10% 的专家发生了变化。这种现象在更深的 MoE 模型中更为显著,导致 token 级重要性比率 剧烈波动,并进一步使其失效(如第3节和4.2节所述),从而阻碍强化学习训练的正常收敛。
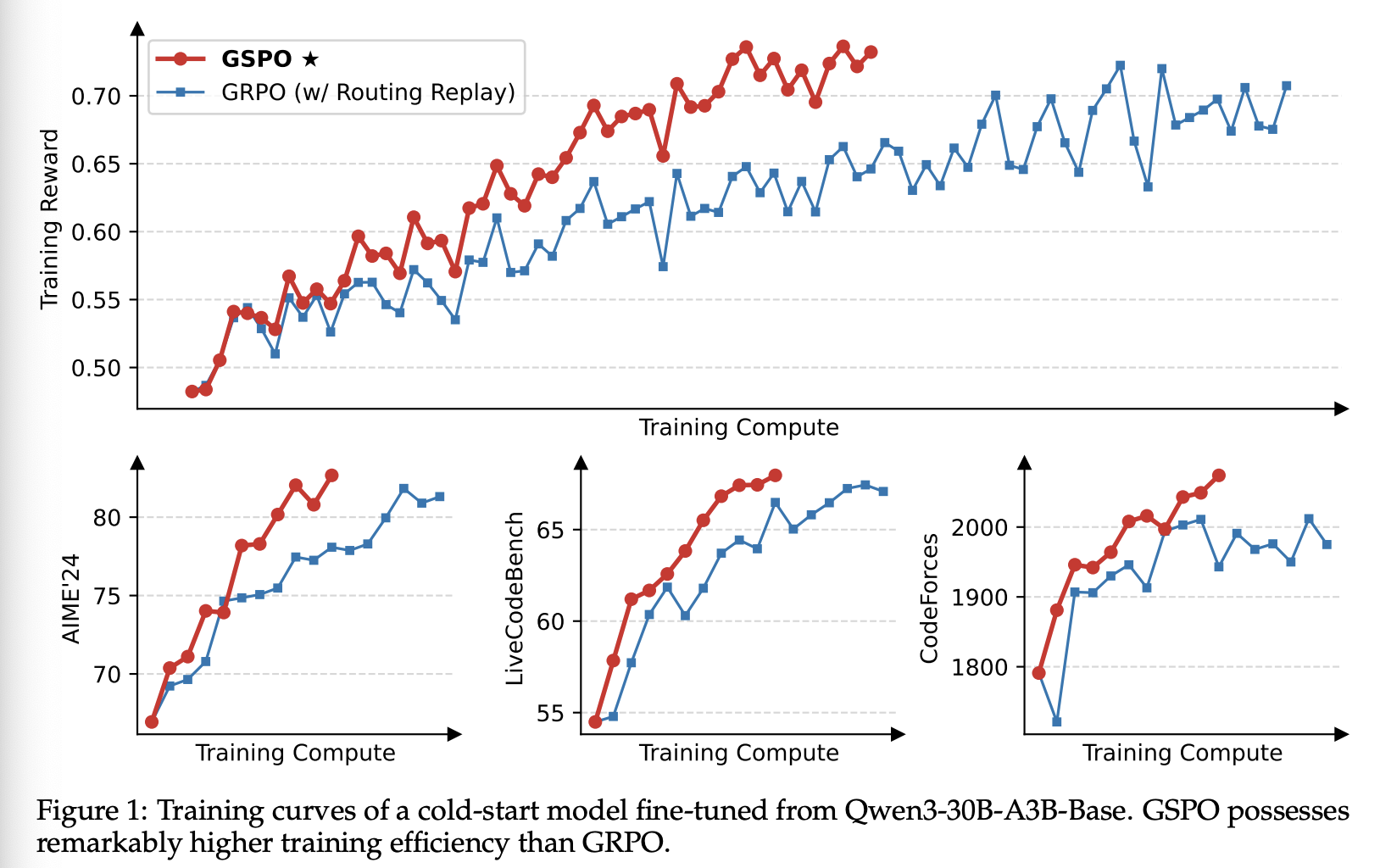
Our Previous Approach。为了应对这一挑战,我们之前采用了路由重放训练策略。具体来说,我们将激活的专家缓存在 中,并在计算重要性比率 时,在 中“重放”这些路由模式。这样,对于每个 token , 和 共享同一个激活网络,从而可以恢复 token 级重要性比率的稳定性,并确保在梯度更新过程中激活网络的优化一致性。图 3 表明,路由重放是 MoE 模型 GRPO 训练正常收敛的关键技术。
Benefit of GSPO。尽管路由重放能够使 GRPO 训练的 MoE 模型正常收敛,但其重用路由模式的做法会带来额外的内存和通信开销,并且可能限制 MoE 模型的实际容量。相比之下,如图 1 所示,GSPO 消除了对路由重放的依赖,能够以常规方式计算重要性比率 ,正常收敛并稳定优化。其关键在于 GSPO 仅关注序列似然(即 ),而不关注单个 token 似然(即 )。由于 MoE 模型始终保持其语言建模能力,因此序列似然不会出现剧烈波动。总之,GSPO 从根本上解决了 MoE 模型中专家激活波动的问题,避免了使用路由重放等复杂变通方法。这不仅简化和稳定了训练过程,而且还使模型能够在不受人为限制的情况下充分发挥其能力。