论文链接:https://arxiv.org/pdf/2506.04209
代码链接:https://github.com/Jingfeng0705/LIFT
摘要
目前,建立语言-图像对齐的最主要方法是通过对比学习联合预训练文本和图像编码器,例如 CLIP 及其变体。在本研究中,我们质疑这种成本高昂的联合训练是否必要。具体而言,我们探究预训练的固定大语言模型 (LLM) 是否能够提供足够好的文本编码器来指导视觉表征学习。也就是说,我们提出通过仅训练图像编码器,使用来自 LLM 的 Language-Image alignment with a Fixed Text encoder (LIFT)。令人惊讶的是,通过全面的基准测试和简化研究,我们发现这个简化的框架 LIFT 非常有效,并且在大多数涉及构图理解和长字幕的场景中都优于 CLIP,同时在计算效率方面也取得了显著的提升。我们的工作迈出了系统地探索 LLM 的文本嵌入如何指导视觉学习的第一步,并提出了一种学习语言对齐视觉表征的替代设计方案。我们的代码和 checkpoint 可在 https://github.com/Jingfeng0705/LIFT 获取。
1.介绍

近年来,基于海量文本-图像对进行对比预训练已成为学习语言对齐视觉表征的有力范例,并在视觉语言模型 (VLM) 等应用中展现出卓越的性能。CLIP 和 SigLIP 等代表性工作通过在成对数据上训练单独的文本和图像编码器并使用对比损失,在共享空间中对齐文本和图像嵌入。这种方法已被证明非常有效——如今大多数 VLM 都采用此类预训练图像编码器,因为它们具有语言对齐的视觉表征。
尽管文本-图像对的对比预训练被广泛采用,但它仍存在一些众所周知的局限性。例如,从头开始训练两个编码器会使该方法的计算成本高昂。CLIP 所需的大批量和海量训练数据进一步加剧了这个问题。此外,CLIP 的文本和图像编码器难以准确地编码构图信息,包括词序(Text)、空间位置(Imgage)、对象-属性关联(both)以及对象-对象关系(both)。先前的研究将此局限性归因于这样一个事实:在通用检索数据集上进行对比预训练会激励 CLIP 的从头开始训练的编码器采用一种捷径策略,即抑制(即丢弃)与构图信息相关的特征。
至关重要的是,主流对比方法所持有的一个核心假设是该局限性的核心:最佳的语言-图像对齐需要从头开始联合训练文本和图像编码器。在这项工作中,我们质疑这种联合训练的必要性,并证明大语言模型 (LLM) 已经提供了足够好的文本嵌入来指导视觉表征学习。具体而言,我们使用在 LLM 上微调的预训练文本编码器来离线嵌入文本,并单独训练图像编码器以将视觉表征与文本嵌入对齐。我们将这种方法命名为 Language-Image alignment with a Fixed Text encoder (LIFT)。LIFT 这个名称还表明它将原始视觉输入与其相应的高级语义对齐。图 2 展示了所提框架的整体流程。
为了研究 LIFT 是否、何时以及为何可能比 vanilla CLIP 更具优势,我们进行了广泛的基准测试和消融研究,以解决四个基本问题:
- 在评估不同模型能力的任务中,LIFT 在哪些方面比 CLIP 更有优势,又在哪些方面有所不足? Answer:LIFT 在 7 个构图理解任务中,平均准确率比 CLIP 高出 7.4%,并且在 6 个 LLaVA 下游任务中的 5 个中也领先于 CLIP,这得益于其卓越的构图信息编码能力。LIFT 的性能也与 CLIP 的零样本检索性能相当。一些定性结果如图 1 所示。
- LIFT 在哪些类型的训练数据上优于 CLIP,为什么? Answer:在使用短的、从网络抓取的字幕进行训练时,CLIP 在三个零样本检索任务和一个 LLaVA 下游任务中略胜 LIFT 一筹。然而,当两者都使用较长的合成字幕进行训练时,所有这些优势都转移到了 LIFT 身上。我们将 LIFT 的更佳表现归因于其对合成字幕引起的逆效应的鲁棒性。
- 基于 LLM 的文本编码器的哪些设计选择可以实现更好的语言图像对齐? Answer:普通的 LLM 作为 LIFT 的文本编码器通常表现不佳。为了改进文本编码,通常需要进行对比微调,而额外的嵌入提取模块则无需。
- 鉴于其强大的基于 LLM 的文本编码器,LIFT 能否简化主流语言图像对齐方法中的一些设计选择? Answer:我们发现,更简单但有效的余弦相似性损失可以替代对比损失,同时在组合理解任务和 LLaVA 下游任务上实现可比的性能。
2.Related Work
2.1 Language-Image Representation Learning
目前,语言-图像对齐通常通过对比学习实现。开创性的工作 CLIP 和 ALIGN 率先对文本-图像对进行大规模预训练,以学习联合嵌入,从而实现零样本迁移到各种下游任务。这些方法依赖于双编码器架构,其中文本和图像编码器从头开始联合训练,以最大化配对样本嵌入之间的对齐(例如,通过余弦相似度衡量),同时最小化非匹配对嵌入之间的对齐。随后,SigLIP 使用 Sigmoid 对比损失函数提高了训练稳定性。然而,这些方法需要大量的计算资源来训练两个编码器。
最近,SuperClass 和 CatLIP 探索了一种无需文本编码器的替代训练范式。他们从字幕中提取类别标签,并通过训练带有二分类交叉熵损失的图像编码器,将语言-图像对齐转化为多标签分类问题。然而,由于这些方法忽略了字幕中的词序,因此得到的表示类似于词袋模型,缺乏对词组结构的理解。
在这项工作中,我们的目标是简化语言图像对齐流程,同时避免现有无文本编码器方法的缺点。
2.2 The Limitations of CLIP
众所周知,CLIP 缺乏对结构的理解,这主要是因为在通用检索数据集上进行的对比预训练会促使 CLIP 的编码器采取忽略结构信息的捷径策略。为了解决这个问题,[58] 在训练过程中加入了设计的负样本;[49, 50] 则结合了来自多个图像编码器的特征。近期,[36, 39, 41, 51] 将自监督学习方法与对比学习相结合,从而产生了具有更强视觉中心能力的图像编码器。与我们的研究更接近的文献 [5, 47] 用 LLM 替换了 CLIP 的文本编码器,并将其与图像编码器联合训练,从而实现了更好的缩放行为和更强的结构理解。然而,由于对训练流程进行了额外的修改,他们未能独立使用未改变的 LLM 文本向量,因此未能系统地研究其对语言-图像对齐的影响。
此外,[32, 33, 54] 表明,CLIP 在训练全长长字幕时,零样本性能欠佳,而长字幕通常由可变长度语言模型 (VLM) 合成,包含详细的物体描述。[33] 推测,CLIP 的文本编码器会受到合成字幕句法相似性的干扰,从而无法关注语义上有意义的内容。文本裁剪 [33] 和子字幕采样 [60] 等截断策略可以带来实证改进。然而,它们不可避免地会牺牲长字幕所提供的丰富信息。
总而言之,目前的方法不足以解决这两个问题。我们尝试通过质疑对比语言-图像对齐的现行机制来解决这两个问题。
2.3 Text Embedding Models
文本嵌入模型被广泛用于提取文本的语义嵌入,并且在诸如检索增强生成 (RAG) 等任务中至关重要。传统的嵌入模型,例如 BERT 和 T5,通常采用双向注意力机制进行训练。近期,基于 LLM 的嵌入模型,例如 LLM2Vec、E5-Mistral、SFR-Embedding-Mistral 和 NV-Embed-V2,旨在利用自回归 LLM 的丰富语义,并已成为海量文本嵌入基准 (MTEB) 上强大的嵌入模型。特别地,NV-Embed-V2 引入了一个新的潜在注意力层和一个两阶段对比指令微调,使得生成的文本嵌入丰富且在不同语义文本之间具有显著差异。因此,它被用作 LIFT 的文本编码器。
3.Method
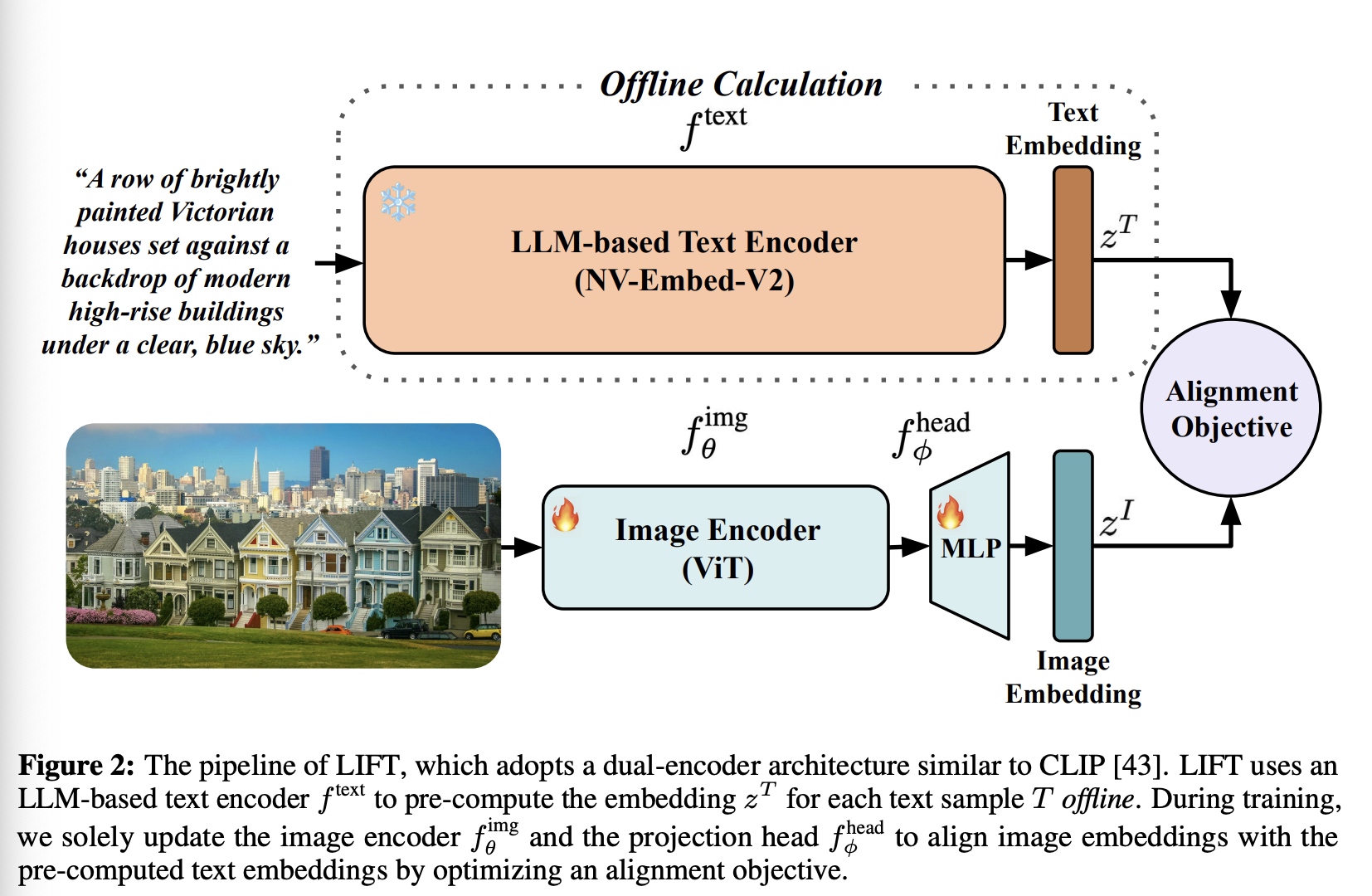
如图 2 所示,LIFT 采用类似于 CLIP 的双编码器架构。设 表示文本-图像对,其中 是来自词表 的 个 token 序列,。我们使用一个基于 LLM 的预训练且冻结的文本编码器 ,其输出维度为 ,用于提取文本向量:
我们参数化一个图像编码器神经网络 和一个投影头 。 由一个宽度为 的 ViT 实现, 是一个 2 层 MLP。令:
作为最终的图像嵌入。我们使用 CLIP 的对比损失作为目标函数,该损失是在一批标准化的 和 之间计算得出的:
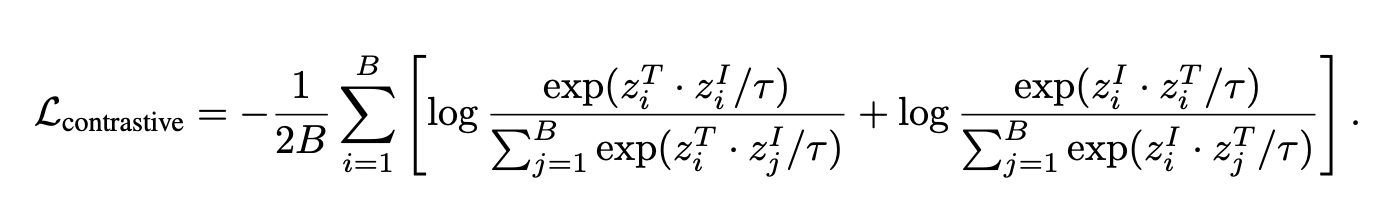
Offline Text Embeddings Generation。由于我们不优化 ,因此整个文本嵌入过程可以离线执行。具体来说,在训练 LIFT 之前,我们将所有字幕嵌入到数据集中一次,以便后续训练无需文本编码器即可重用预先计算的字幕嵌入。LIFT 使用 NV-Embed-V2 作为 。作为参考,八块 H800 GPU 每天可以以 bfloat16 精度嵌入 1 亿条字幕。
如图 3 和图 4 所示,离线嵌入文本可显著提高计算和内存效率。具体而言,给定每批次平均最大字幕 token 长度 ,CLIP 的 FLOP 和内存占用随复杂度 而变化,而 LIFT 的复杂度则达到 。我们还对短字幕(n = 77)和长字幕(n = 128)的 CLIP 和 LIFT 进行了定量基准测试。平均而言,LIFT 可将短字幕的 FLOP 降低 25.5%,将长字幕的 FLOP 降低 35.7%,同时将内存占用分别降低 6.8% 和 12.6%。FLOP 和内存占用的计算细节见附录 A.4。
4.Experiments
