论文链接:https://arxiv.org/pdf/2502.14786
摘要
我们推出了 SigLIP 2,这是一系列全新的多语言视觉语言编码器,它建立在初代 SigLIP 的成功之上。在第二代迭代中,我们将原有的图像-文本训练目标与之前独立开发的多种技术整合到一个统一的方案中,其中包括基于图像描述的预训练、自监督损失(自蒸馏、掩码预测)以及在线数据管理。通过这些改进,SigLIP 2 模型在所有模型规模上的核心能力方面均优于其 SigLIP 版本,这些核心能力包括零样本分类、图像-文本检索以及在为视觉语言模型 (VLM) 提取视觉表征时的迁移性能。此外,新的训练方案显著提升了定位和密集预测任务的性能。我们还训练了支持多种分辨率并保持输入原始宽高比的变体。最后,我们使用包含去偏技术的更多样化的数据混合进行训练,从而显著提升了多语言理解能力和公平性。为了允许用户在推理成本和性能之间进行权衡,我们发布了四种大小的模型检查点:ViT-B(86M)、L(303M)、So400m(400M)和g(1B)。
1.Introduction
由 CLIP 和 ALIGN 开创的、基于数十亿级数据集训练的图像-文本对比嵌入模型,已成为对视觉数据进行高层次语义理解的主流方法。这些模型能够实现细粒度的零样本分类,其质量可与监督学习方法相媲美,并能高效地进行文本到图像和图像到文本的检索。此外,当与大语言模型 (LLM) 结合构建视觉语言模型 (VLM) 时,它们还能带来卓越的视觉语言理解能力。
基于 CLIP 的成功,人们提出了多种改进方案,例如图像重描述、添加仅基于图像的自监督损失以及使用小型解码器进行训练以完成辅助任务(例如图像描述和定位)。与此同时,一些研究团队也为开源社区发布了模型检查点。然而,这些版本并未将所有最新的改进整合到一个模型中,因为它们都相对紧密地遵循了 CLIP 的原始方法。本文基于 SigLIP 的训练方案,融合了先前工作的多项改进,并发布了一系列新的开源模型。这些模型不仅在 CLIP 的核心功能(即零样本分类、检索和视觉语言模型的特征提取)方面表现出色,而且在定位和提取密集语义表示等 CLIP 式模型的不足之处也得到了改进。
综上所述,SigLIP 2 模型提供以下功能:
- 强大的多语言视觉语言编码器:SigLIP 2 在以英语为中心的视觉语言任务上表现出色,同时在多语言基准测试中也取得了优异的成绩,这使其能够应用于广泛的语言和文化背景中。
- 密集特征:我们结合了自监督损失和基于解码器的损失,从而产生了更好的密集特征(例如用于分割和深度估计),并改进了定位任务(例如指代表达理解)。
- 向后兼容性:SigLIP 2 采用与 SigLIP 相同的架构,因此具有向后兼容性。这使得现有用户只需替换模型权重和分词器(现在支持多语言),即可在各种任务上获得性能提升。
- 原生宽高比和可变分辨率:SigLIP 2 还包含 NaFlex 变体,它支持多种分辨率并保持图像的原生宽高比。这些模型有望改进对宽高比敏感的应用,例如文档理解。
- 强大的小型模型:SigLIP 2 通过主动数据管理中的蒸馏技术,进一步优化小型模型(B/16 和 B/32 模型)的性能。
下一节将详细介绍 SigLIP 2 的训练流程。第 3 节展示了 SigLIP 2 模型和基线模型在各种任务和基准测试中的评估结果。最后,第 4 节简要概述了相关工作,结论见第 5 节。
2.Training recipe
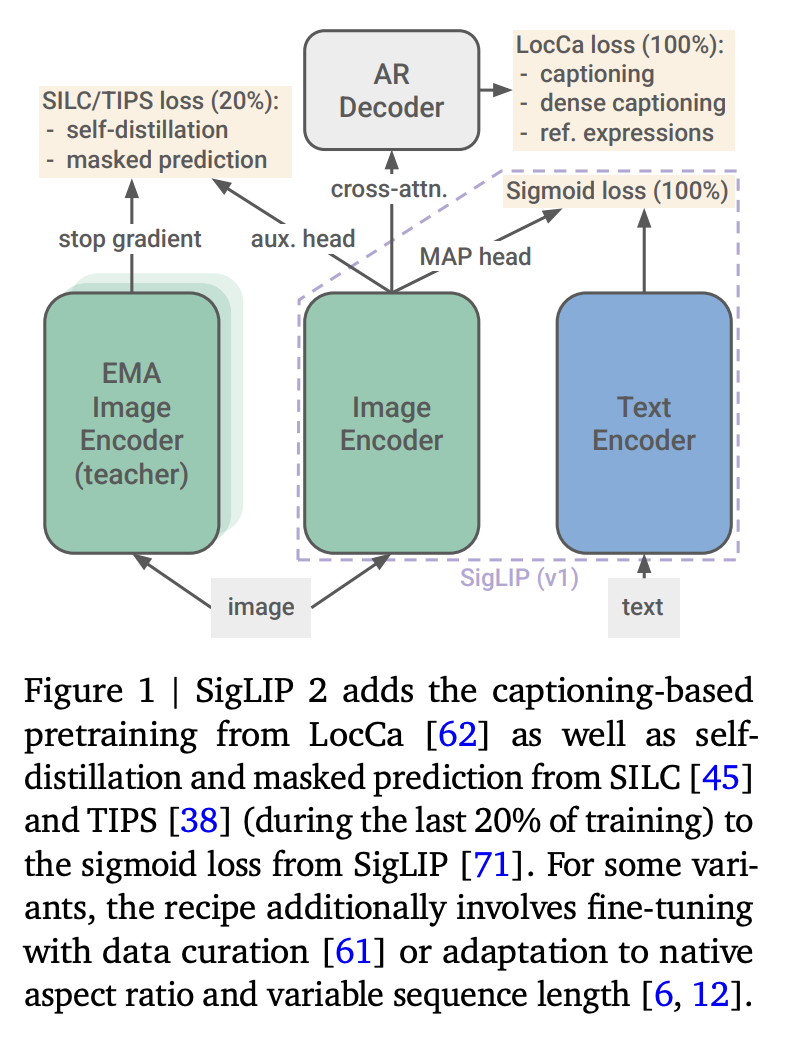
我们结合了原始的 SigLIP 训练方法和基于解码器的预训练,以及类似于 DINO 工作中的自蒸馏和掩码预测(参见图 1 的概述)。研究表明,使用语言解码器预训练图像编码器以进行图像描述和指称表达理解可以提高 OCR 能力和定位精度,而自蒸馏和掩码预测则可以为密集预测任务、零样本分类和检索任务提供更好的特征。为了控制与 SigLIP 训练相比的计算和内存开销,我们并没有将所有这些技术一次性全部组合在一起,而是采用如下所述的分阶段方法。
除了训练一组模型并分别针对不同分辨率调整每个模型(同时改变宽高比)之外,我们还训练了一些变体模型,这些模型在处理图像时能够基本保持其原始宽高比,例如 NaViT,并且支持不同的序列长度,例如 FlexiViT。我们将这种变体模型称为 NaFlex,详见第 2.4.2 节。
最后,为了提高最小模型的质量,我们按照 [61] 中的方法,通过主动样本选择对具有隐式蒸馏的模型进行微调。
2.1 Architecture, training data, optimizer
在架构方面,我们遵循 SigLIP 协议,以便现有用户可以轻松替换编码器权重。具体来说,固定分辨率版本基于标准的 ViT 架构,并学习了位置嵌入。图像和文本编码器使用了相同的架构,区别在于 g 尺寸的视觉编码器与 So400m 尺寸 的文本编码器配对。视觉和文本表示通过 MAP 头(注意力池化)进行池化。我们将文本长度设置为 64,并使用词表为 256k 的多语言 Gemma 分词器,在分词之前将文本转换为小写。
我们使用包含 100 亿张图像和 120 亿条替代文本的 WebLI 数据集,涵盖 109 种语言。为了在英语和多语言视觉语言基准测试中取得良好的平衡,我们按照 [49] 中的建议,将混合数据集的 90% 训练图像-文本对来自英文网页,其余 10% 来自非英文网页。此外,我们还应用了 [2] 中的过滤技术来减轻数据在表示和关联方面对敏感属性的偏差。
除非另有说明,我们使用学习率为 的 Adam 优化器,解耦权重衰减为 ,梯度裁剪为范数 1。我们将 batch size 设置为 32k,并使用余弦调度,预热步数为 20k,总共训练 400 亿个样本。我们的模型在多达 2048 个 TPUv5e 芯片上进行训练,采用完全分片数据并行策略 (FSDP)。
2.2 Training with Sigmoid loss and decoder
在预训练的第一步中,我们将 SigLIP 与 LocCa 结合起来,方法是简单地将两种损失函数以相同的权重进行合并。与依赖对比损失的 CLIP 不同,SigLIP 通过将小批量中的每个图像嵌入与每个文本嵌入进行组合来创建二分类问题,并通过逻辑回归(sigmoid 损失)训练这些嵌入以对匹配和不匹配的对进行分类。我们使用原始实现,详情请参阅 [71]。
对于 LocCa,我们在未池化的视觉编码器表示(在应用 MAP 头之前)上附加一个带有交叉注意力机制的标准 Transformer 解码器。该解码器的结构与文本编码器类似,只是增加了交叉注意力层并将层数减少了一半。除了图像描述之外,LocCa 还训练用于自动指称表达式预测和基于上下文的图像描述。前者是指预测描述特定图像区域的描述文本的边界框坐标,而后者是指根据边界框坐标预测特定区域的描述文本。区域-描述对的标注是通过首先从替代文本中提取 n-gram,然后使用 [41] 中的方法进行开放词汇检测来实现的。此外,我们使用 [10] 中的固定对象类别集来代替 n-gram。对于每个示例,解码器都经过训练以预测所有三个目标(相当于三次解码器前向传播)。字幕目标的预测采用并行预测,概率为50%,即所有字幕 token 均由 mask token 并行预测,不使用因果注意力掩码。更多细节请参见[62]。最后,为了降低大词汇量带来的内存消耗,我们实现了解码器损失的分块版本。
对于所有模型尺寸,我们将视觉编码器的 patch size 设置为 16,图像分辨率设置为 256(从而得到长度为 256 的图像表示序列)。最后,解码器仅用于此处的表示学习,并不包含在模型发布中。
2.3 Training with self-distillation and masked prediction
继 SILC 和 TIPS 之后,我们在第 2.2 节所述的训练设置基础上,引入了局部到全局对应学习(结合自蒸馏)和掩码预测损失,以提升(未池化的)特征表示的局部语义。这种表示通常用于密集预测任务,例如分割、深度估计等。具体而言,我们在第 2.2 节所述的损失函数中添加了两个项,详见下文。
第一项是来自文献 [45] 的局部到全局一致性损失,其中视觉编码器成为 student 网络,它获取训练图像的部分(局部)视图,并被训练以匹配从完整图像中提取的 teacher 表示。这种辅助匹配任务在一个由单独的多层感知器(MLP)头计算的高维特征空间中执行。与文献中常见的做法一样,student 参数是通过对先前迭代的学生参数进行指数移动平均(EMA)得到的。我们依赖于一个全局(教师)视图和8个局部(学生)视图,其他增强、损失和超参数均与文献[45]相同。
第二个损失项是来自 [38] 的马赛克预测目标函数。我们将 student 网络中 50% 的嵌入 patch 替换为掩码 token,并训练 student 模型匹配 teacher 模型在掩码位置的特征。该损失的定义与第一个损失项(一致性损失)相同,但应用于每个 patch 的特征,而不是池化的图像级表示。此外,学生模型和教师模型看到的是相同的全局视图(学生模型中仅包含掩码标记)。
我们在训练完成 80% 时添加这些损失,并使用 student 模型的参数初始化教师模型,其余的附加参数(头部、掩码标记和相应的优化器参数)则随机分配。我们使用原始图像计算上一节中的 SigLIP 和 LocCa 损失,并将附加损失应用于额外的增强视图。这样做是为了确保数据增强不会像 [45] 建议的那样对图像-文本对齐产生负面影响。第一项和第二项损失的权重分别设置为 1 和 0.25。此外,为了平衡模型在全局/语义任务和密集任务上的质量,我们分别对 B、L、So400m 和 g 模型尺寸的两个损失项进行 0.25、0.5、1.0 和 0.5 的加权。
2.4 Adaptation to different resolutions
2.4.1 Fixed-resolution variant
为了在多个分辨率下获得固定分辨率的检查点,我们在训练进行到 95% 时恢复检查点(序列长度为 256,patch size 为 16),将位置嵌入调整为目标序列长度(在某些情况下,使用 [6] 中的伪逆 (PI) 调整策略将 patch 嵌入从 patch size 16 调整为 14),然后使用所有损失函数在目标分辨率下恢复训练。我们选择这种方法是因为常用的策略(使用较小的学习率且不进行权重衰减来微调最后一个检查点)在所有尺寸和分辨率下都未能取得良好的结果。
2.4.2 Variable aspect and resolution (NaFlex)
NaFlex 融合了 FlexiViT 和 NaViT 的理念。FlexiViT 支持使用单个 ViT 模型处理多种预定义的序列长度,而 NaViT 则以图像的原始宽高比进行处理。这使得 NaFlex 能够以适当的分辨率处理不同类型的图像,例如,使用更高的分辨率处理文档图像,同时最大限度地减少宽高比失真对某些推理任务(例如 OCR)的影响。
给定 patch size 和目标序列长度,NaFlex 首先对输入图像进行预处理,使其调整大小后的高度和宽度均为 patch size 的倍数,同时:1)尽可能减小宽高比失真;2)生成至多等于目标序列长度的序列。由此产生的宽度和高度失真分别至多为 (patch_size-1)/width 和 (patch_size-1)/height,对于常见的分辨率和宽高比,这种失真通常很小。需要注意的是,NaViT 也会产生类似的失真。调整大小后,图像被分割成一系列 patch,并添加 patch 坐标以及包含 padding 信息的掩码(用于处理实际序列长度小于目标长度的情况)。
为了使用 ViT 处理不同长度(和宽高比)的序列,我们对学习到的位置嵌入进行双线性缩放(并进行抗锯齿处理),使其与目标非正方形块网格相匹配,以适应调整大小后的输入图像。我们将学习到的位置嵌入的长度设置为 256,假设缩放前块网格为 16 × 16。当缩放后的序列长度小于目标序列长度时,注意力层(包括 MAP 头)会被屏蔽以忽略额外的 pad token。
对于固定分辨率的自适应变体,我们从使用第 2.2 节所述设置训练的默认检查点开始,即使用非宽高比保持的缩放方式将图像缩放至 256 像素,得到 256 的序列长度。我们在训练完成 90% 时选取检查点,然后切换到宽高比保持的缩放方式,并从 {128, 256, 576, 784, 1024} 中均匀采样每个小批量的序列长度。同时,我们将最后 10% 对应的学习率调整因子提高 3.75,以确保每个分辨率都训练了足够多的样本。对于最长的序列长度,我们进一步将批次大小减半,并将训练步数加倍,以避免内存溢出错误。
为了使实现和计算复杂度保持在可控范围内,我们不采用第 2.3 节中的自蒸馏和掩码预测方法。
2.5 Distillation via active data curation
为了最大化最小固定分辨率模型(ViT-B/16 和 ViT-B/32)的性能,我们在一个短暂的微调阶段从 teacher(参考)模型中蒸馏知识。我们将学习率降低到 ,移除权重衰减,并仅使用 sigmoid 图像文本损失函数继续训练这些模型,训练样本数增加到 40 亿。在此阶段,我们使用 [61] 中提出的 ACID 方法进行隐式的“数据蒸馏”。简而言之,在每个训练步骤中,我们使用 teacher 模型和当前学习模型根据样本的“可学习性” 对样本进行评分。然后,这些分数用于从更大的超批量中联合选择一个大小为 32k 的最优批次。在这里,我们选择过滤率为 0.5 的数据(即超批量大小为 64k),以平衡数据整理带来的收益和训练计算成本。对于 B/32 模型,我们发现使用 0.75 的过滤率是值得的。
我们注意到,文献 [61] 的作者认为,ACED 方法能够实现最佳性能,该方法结合了 ACID 和显式 softmax 蒸馏(使用在更多样化的数据上训练的第二个 teacher 模型)。然而,本文提出了一种改进 ACID 的方法,无需显式蒸馏即可获得这些优势,从而显著节省计算资源。具体而言,我们不使用两个独立的 teacher 模型,而是使用一个在多样化数据上训练的强教师模型(在本例中为SigLIP 2 So400m模型),并针对文献 [16] 中提供的高质量精选数据集上的10亿个样本进行微调。然后,我们如上所述,将这个微调后的 teacher 模型应用于ACID方法中。由于该教师模型融合了预训练中丰富的概念知识和高质量知识(来自精选数据集),因此仅ACID的隐式蒸馏就足以恢复ACED的优势。