Agentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
论文链接:https://arxiv.org/pdf/2604.25850
代码链接:https://github.com/china-qijizhifeng/agentic-harness-engineering
摘要
如今,模型框架(Harness)已成为智能体性能的核心,它协调着模型与工具和执行环境的交互方式。然而,模型框架工程仍然是一项手工技艺,因为自动化面临着可编辑组件间异构的动作空间、大量掩盖有效信号的轨迹,以及难以归因的编辑效果等挑战。我们引入了 Agentic Harness Engineering (AHE),这是一个闭环系统,通过三个匹配的可观测性支柱来应对这些挑战:❶ 组件可观测性为每个可编辑的模型框架组件提供文件级表示,从而使动作空间清晰且可逆;❷ 经验可观测性将数百万个原始轨迹 token 提炼成一个分层的、可深入挖掘的证据库,供不断演化的智能体实际使用;❸ 决策可观测性将每次编辑与一个自我声明的预测配对,并在下一轮任务级结果中进行验证。这三个支柱共同将每次编辑转化为一个可证伪的契约,从而使模型框架的演化能够自主进行,避免陷入试错的泥潭。经验表明,经过十次 AHE 迭代,Terminal-Bench 2 上的 pass@1 成功率从 69.7% 提升至 77.0%,超过了人工设计的框架 Codex (71.9%) 以及自演化基线 ACE 和 Training-Free GRPO。冻结的框架无需重新演化即可迁移:在 SWE-bench-verified 上,它实现了最高的综合成功率,同时使用的 token 数量比种子模型减少了 12%;在 TerminalBench 2 上,它在三个不同的模型系列中实现了 +5.1 至 +10.1 pp 的跨系列性能提升,表明演化后的组件编码了通用的工程经验,而非针对特定基准测试的调优。消融实验进一步将性能提升归因于工具、中间件和长期记忆,而非系统提示。这些结果表明,基于可观测性的演化是一种切实可行的途径,能够使编码 Agent 框架与其基础模型同步持续改进。
1.介绍
编码 Agent 越来越多地应用于长期软件工程任务,并在解决真实代码库和多步骤终端工作流的问题方面取得了显著进展。实际上,这种进展不仅依赖于底层语言模型,也同样依赖于周围的工程组件:塑造工作方式的系统提示、暴露文件系统和 shell 的工具,以及控制上下文、执行和恢复的中间件。这些模型外部的可编辑组件统称为 Agent Harness。
即使基础模型保持不变,框架设计也能显著提升长期编码基准测试的任务完成率,这使得框架工程成为提升编码 Agent 性能的重要手段。此外,最佳框架是针对特定模型的:针对某个基础模型优化的框架在另一个基础模型上往往表现不佳,并且必须随着基础模型的变化而进行重新调整。目前,这种调整是手动完成的——开发人员检查执行轨迹,识别重复出现的故障模式,并手动修改提示、工具、中间件和技能。然而,随着基础模型的快速发展,这种手动循环难以跟上步伐,导致模型能力与实现该能力所需的框架之间的差距日益扩大。
一个直观的方向是利用 evolution Agent 实现此循环的自动化,该 Agent 能够基于经验优化工具组件。然而,现有方法很少能够联合演化所有可编辑组件;大多数方法都侧重于单个组件,通常是提示、技能或上下文相关的剧本。端到端地联合演化多个组件面临两个结构性障碍:冗长且无结构的演化轨迹难以产生可操作的信号,而紧密耦合的工具框架使得对提示之外的编辑容易出错。这使得 Agent 驱动的工具演化的核心问题仍然悬而未决:evolution Agent 如何才能联合且稳定地演化编码 Agent 工具的所有可编辑组件?
我们的核心观点是,这个问题的瓶颈在于可观测性,而非智能体的能力:一旦 evolution Agent 接收到清晰动作空间中的结构化上下文,它就能可靠地收敛到更优的框架设计。我们在智能体框架工程(AHE,图 2)中实现了这一点,这是一个由三大可观测性支柱驱动的闭环:❶ 通过解耦框架实现组件可观测性,该框架将七种可编辑的组件类型以文件的形式公开,因此每个故障模式都能清晰地映射到单个组件类;❷ 通过从数百万原始轨迹 token 中提炼出的分层、可钻取的证据库实现经验可观测性,因此 evolution Agent 能够获取结构化的根本原因,而不是原始日志;❸ 通过变更清单实现决策可观测性,该清单将每次编辑与一个自我声明的预测配对,并在下一轮任务级结果中进行验证,因此每次编辑都成为一个可证伪的契约,无效的编辑会在文件粒度级别上被回滚。
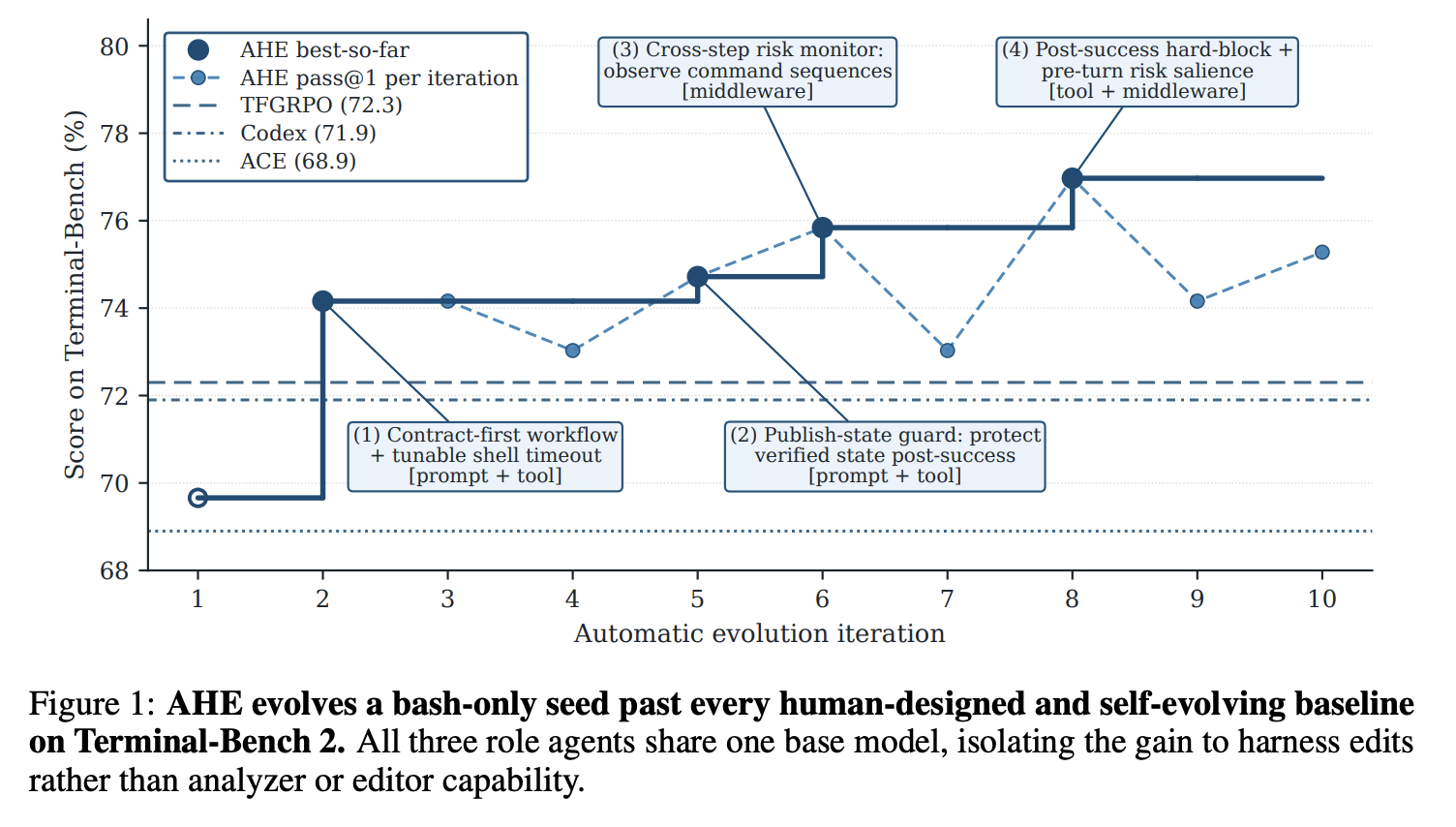
我们在 Terminal-Bench 2 上对 AHE 进行了实证验证:十次迭代将 pass@1 的准确率从 69.7% 提升至 77.0%,超过了人工设计的 Codex 以及自演化基线 ACE 和 Training-Free GRPO。无需进一步演化,冻结的框架即可迁移到 SWE-benchverified,并且在三个不同的基模型系列中均获得了 +5.1 至 +10.1 pp 的稳定 pass@1 提升,其中在低性能的基模型上提升幅度最大,这表明 AHE 编码了低性能模型更依赖的协调模式。组件消融实验明确了提升的来源:工具、中间件和长期记忆各自独立地带来了改进,而系统提示本身却出现了退步,这表明框架级别的策略可以跨任务和模型迁移,而文字级别的策略则不能。
本文做出以下三项贡献:
- 我们为编码 Agent 制定了 Agent 驱动的框架演化,并提出了 AHE,它将组件、轨迹和决策之间的可观测性作为设计枢纽,并通过三个可观测性支柱将每次框架编辑转化为可证伪的文件级契约:解耦的组件底层、分层的轨迹提炼管道以及变更清单,其自我声明的预测由下一轮任务增量进行验证。
- 我们通过实证表明,AHE 将 Terminal-Bench 2 上的 pass@1 从 69.7% 提高到 77.0%,超越了人工设计和自动化的基准,并生成了一个可在测试基准和基础模型系列之间转移的冻结框架。
- 我们的分析揭示了 agent 驱动的自我进化存在两个限制:首先,harness 组件之间存在非加性相互作用,因此即使叠加多个单独有效的修改,总体收益也会受到上限约束;其次,该循环的自我归因能力在识别修复效果方面较为可靠,但对性能退化缺乏感知。因此,如何提前预判回归/退化,是未来自我进化循环最明确的改进方向。
2.Related Work
2.1 Harness Engineering and Evaluation for Coding Agents
Harness Engineering 是指设计围绕模型运行的系统,包括其工具、接口、记忆、执行约束和反馈回路,这些因素共同决定了智能体在长期任务中能够执行的操作。具体而言,框架协调模型如何感知环境并与之互动:它公开了用于展开工具增强推理的动作和观察接口、用于存储库导航、文件编辑和命令执行的自定义智能体-计算机接口,以及确保长期运行可复现的沙盒执行和编排支持。
验证此类系统是否真正有效,推动了编码 Agent 评估在两个维度上的并行发展:任务评估范围和环境真实性。评估范围涵盖了从侧重于污染和新鲜度控制的短期功能级基准测试,到 repo 规模的可执行补丁解析,再到长达数小时、终端驱动的、模拟长期真实执行的工作流程。一个并行基础设施轨道围绕这些基准测试打包了可执行运行时和验证器,这些基准测试对可复现、可追溯和可验证执行的关注,直接推动了 AHE 所依赖的观察系统的构建。
2.2 Automated Optimization of LLM Agents
自动化智能体优化方法在优化器可观测的证据和可编辑的内容方面存在差异。一些方法通过上下文批判和反思来修正智能体自身的输出。另一些方法则针对提示和指令:结构化剧本、语义优势先验、用于多阶段程序的联合优化指令演示流程以及由帕累托前沿轨迹驱动的反思性更新。还有一种方法直接编辑程序结构本身,例如技能库、通过变异演化的评分程序和智能体档案以及从部署中搜索或学习的图结构工作流。
AHE 将整个组件视为一个组合整体进行调整,而非单个可编辑的曲面,因此优化器能够清晰地理解组件间的权衡关系。它还能最大限度地减少人为先验知识,让优化器通过实际部署来探索优化方法,而不是手动调整。我们在第 3 节中描述了实现这些选择的底层架构、轨迹分析和迭代过程。
3.Method
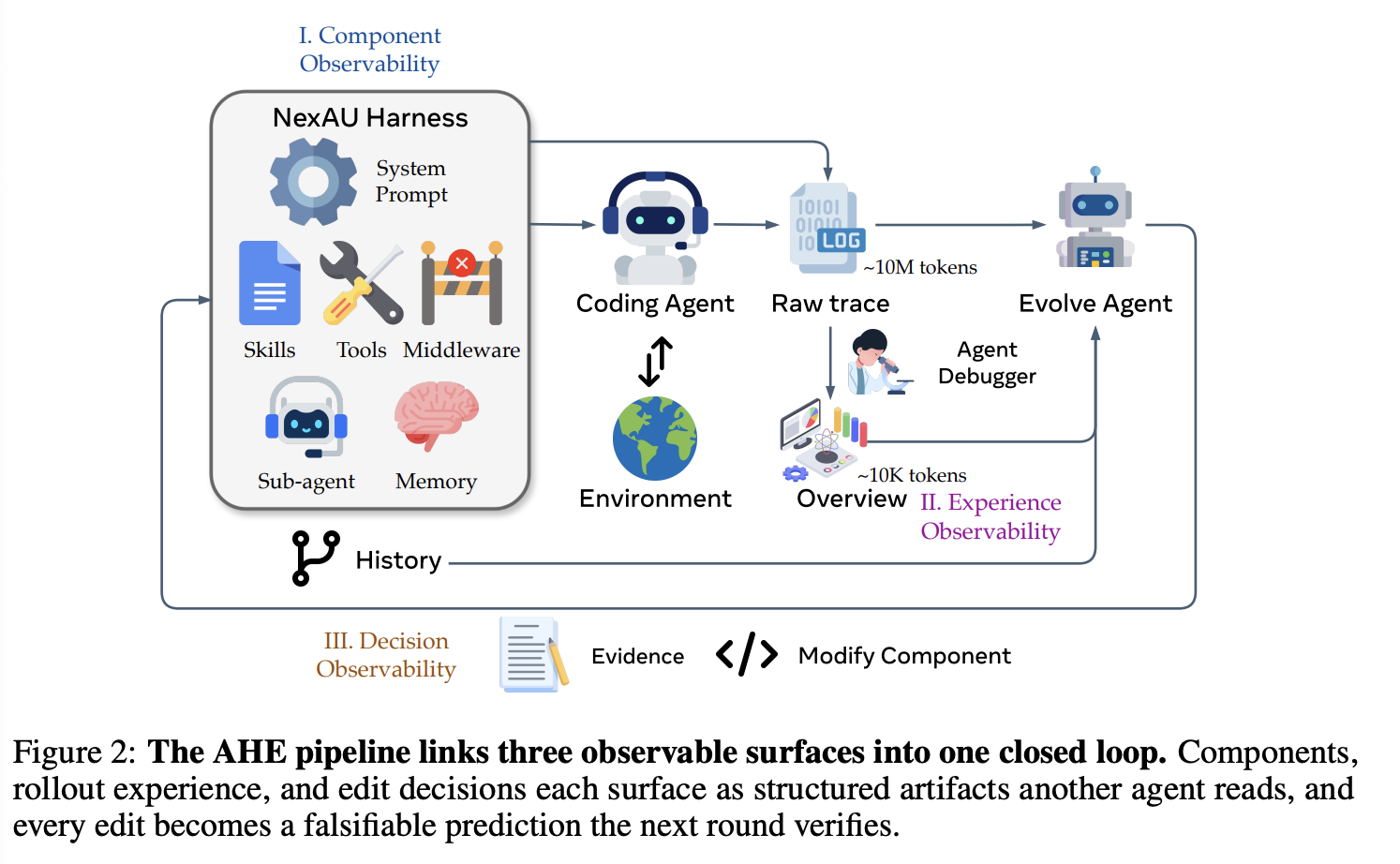
AHE 将框架优化转化为一个由另一个 Agent 驱动的闭环过程,其中基础模型保持不变,仅编辑显式组件。我们的设计原则是,该循环的每个阶段都必须是可观察的:AHE 忠实地记录每个阶段产生的工件(迭代写入的框架组件、生成的 rollout 轨迹、提交的编辑决策),并以结构化的分层形式表示,供其他 Agent 读取和执行。
三个可观测性层实现了这一原则。Component observability(§3.1)通过一个解耦的文件级测试框架底层实现,该底层将每个故障模式映射到单个组件类。Experience observability(§3.2)通过一个分层证据库实现,该证据库从原始 rollout 中提炼出来,并建立索引以便进行深入访问。Decision observability(§3.3)通过一个变更清单实现,该清单将每次编辑与一个自我声明的预测配对,下一轮将验证该预测。这三个层构成 Algorithm 1 的迭代,该算法可以自动一轮又一轮地运行。
3.1 NexAU: an editable, decoupled harness substrate
我们在 NexAU 框架上实例化了工具 ,该框架在单个工作区中以固定挂载点的显式文件形式公开了七种正交组件类型:系统提示符、工具描述、工具实现、中间件、技能、子 Agent 配置和长期记忆。这些组件类型是松耦合的,因此添加中间件不需要编辑系统提示符,添加技能也不需要修改任何工具。
这种解耦实现了组件的可观测性:每个故障模式都映射到一个单独的组件类,从而为演化 Agent 提供了一个清晰的操作空间,并将每次通过率的更改都集中在一个文件中,而不是分散在数百行无结构的提示文本中。每次逻辑编辑都会在工作区的 Git 历史记录中生成一次提交,从而免费提供文件级差异和回滚粒度。
我们的种子框架 刻意做到极简:仅包含一个 shell 执行工具,不包含中间件、技能或子 Agent。如果种子框架已经与目标基准测试相匹配,那么后续每次修改的归因都会受到影响,因为我们无法判断性能提升是来自循环还是种子框架本身。这种极简的种子框架迫使 AHE 添加的每个组件都必须通过实际部署才能证明其价值。
3.2 Agent Debugger: layered trajectory evidence
我们使用测试框架 为基准测试中的每个任务生成 条轨迹。这些轨迹可能包含由测试框架缺陷导致的错误,这些错误可以得到纠正,但分散在数百万条原始消息中。为了从 Agent 轨迹中提取洞察并实现体验可观测性,我们应用了 Agent Debugger 框架,利用 Agent 探索轨迹。该框架构建了一个可导航的基于文件的环境中,其中每条轨迹消息都存储在各自的文件中,并通过通用 shell 和脚本工具进行访问。具有相同 query 的轨迹被放置在同一个环境中,调试器需要分析失败或成功模式的根本原因,并将分析结果存储在每个任务的分析报告中。该分析还包括任务的通过/失败状态,以指导 Evolve Agent 的运行。最后,我们将每个报告汇总到一个文档中,作为每次迭代的入口点,从而形成基准测试级别的概览。
除了这些报告之外,我们还提供原始跟踪记录,以便 Agent 在需要时验证报告中的说法。跟踪记录以原始形式提供,也提供经过轻微处理(去除不必要内容)的版本。所有这些内容均以文件形式提供,支持逐步披露,从而节省令牌并帮助代理商做出更明智的决策。
3.3 Evolve Agent: evidence-driven, auditable edits
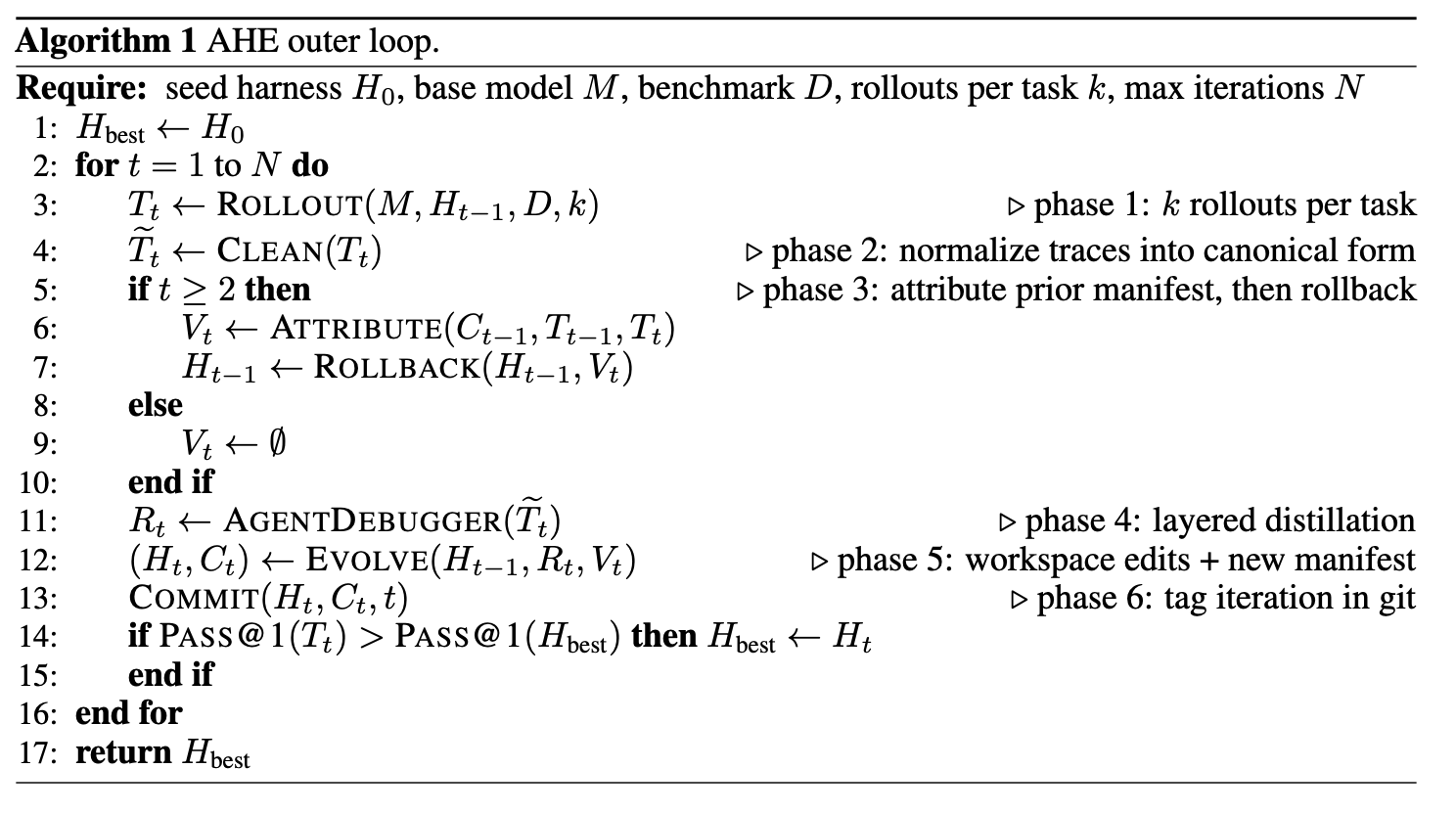
Evolve Agent 完成了 AHE 的闭环。在每一轮迭代中,它读取 Agent Debugger 生成的分层证据语料库,决定添加、修改或移除哪些组件,将这些修改应用到工作区,并记录每次修改背后的原因。这些修改受两个约束条件控制,它们共同实现了决策的可观察性:每次修改都会成为一个可证伪的文件级声明,并记录在版本化的清单中;下一轮的判定结果要么确认该声明,要么撤销它。
第一个限制是可控性:Evolve Agent 只能写入框架工作区,而运行目录、跟踪器、验证器和 LLM 配置均为只读,种子系统提示符(附录 B.1)被标记为不可删除。这些限制阻止了不受约束的自我修改器可能采取的捷径,例如禁用验证器、更换模型或提高推理预算,从而确保所有记录的性能提升都归因于框架的编辑。
第二个限制是,每次变更都必须以证据为依据,并附带记录的预测结果。每次编辑都会附加一个清单条目,其中列出了失败证据、推断出的根本原因、目标修复方案以及包含预期修复和潜在回归的预测影响;该清单即为循环的证据账簿(参见附录 B.2)。在下一轮中,循环会将预测修复和预测回归的集合与观察到的任务级变化进行交集运算,从而得出每次编辑的最终结果。因此,每次编辑都可通过下一次评估进行证伪,从而在轮次之间建立可衡量的契约,取代基于理性论证的自我辩解。
算法 1 将三个底层步骤组合成一个迭代:发布、清理、归因先前清单并回滚被拒绝的编辑、提炼、编辑、提交。每个任务运行 次 rollout,因此每个任务都带有一个通过率信号,这稳定了 pass@1,并使部分通过的任务能够锚定比较诊断。归因在提炼之前运行,因此其结果会落入证据语料库中,并将每个先前清单条目绑定为契约而非理由。一个一次性探索 Agent(附录 B.3)与迭代 1 并行运行,以从 NexAU 源代码和公共 coding-agent 参考中初始化少量可重用技能。这些技能没有特殊保护:从迭代 2 开始,Evolve Agent 可以根据观察到的发布情况保留、改进或删除它们。
4.Experiments
我们的实证研究围绕三个问题展开:AHE 在现有利用设计的方法中处于什么位置,它所产生的结果是否可以移植到其优化目标之外,以及回路内部是什么驱动了增益。
