Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
论文链接:https://www.arxiv.org/pdf/2508.09736
代码链接:https://github.com/bytedance-seed/m3-agent
摘要
我们推出 M3-Agent,一个配备长期记忆的新型多模态 Agent 框架 (multimodal agent framework equipped with long-term memory)。与人类一样,M3-Agent 能够处理实时视觉和听觉输入,从而构建和更新其长期记忆。除了情景记忆之外,它还能发展语义记忆,使其能够随着时间的推移积累世界知识。它的记忆以实体为中心的多模态格式组织,从而能够更深入、更一致地理解环境。在指令下,M3-Agent 能够自主执行多轮迭代推理,并从记忆中检索相关信息以完成任务。为了评估多模态 Agent 的记忆有效性和基于记忆的推理能力,我们开发了 M3-Bench,这是一个全新的长视频问答基准测试。M3-Bench 包含 100 个从机器人视角拍摄的真实世界新录制视频(M3-Bench-robot)和 920 个来自不同场景的网络视频(M3-Bench-web)。我们标注了问答对,旨在测试 Agent 应用所需的关键能力,例如人类理解、常识提取和跨模态推理。实验结果表明,通过强化学习训练的 M3-Agent 的表现优于最强的基线——使用 Gemini-1.5-pro 和 GPT-4o 的提示 Agent,在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别提高了 6.7%、7.7% 和 5.3%。我们的工作推动了多模态 Agent 向更接近人类的长期记忆迈进,并为其实际设计提供了深刻见解。模型、代码和数据可在 https://github.com/bytedance-seed/m3-agent 获取。
1.介绍
想象一下,未来家用机器人无需你的明确指令就能自主完成家务:它通过日常经验学习了你家的运作规则。早上,它递给你一杯咖啡,而不会问“咖啡还是茶?”,因为它通过长期互动逐渐形成了对你记忆,追踪你的喜好和日常习惯。对于多模态 Agent 来说,实现这种智能水平从根本上依赖于三种能力:(1) 通过多模态传感器持续感知世界;(2) 将经验存储在长期记忆中,并逐步构建关于环境的知识;(3) 基于积累的记忆进行推理,以指导自身行动。
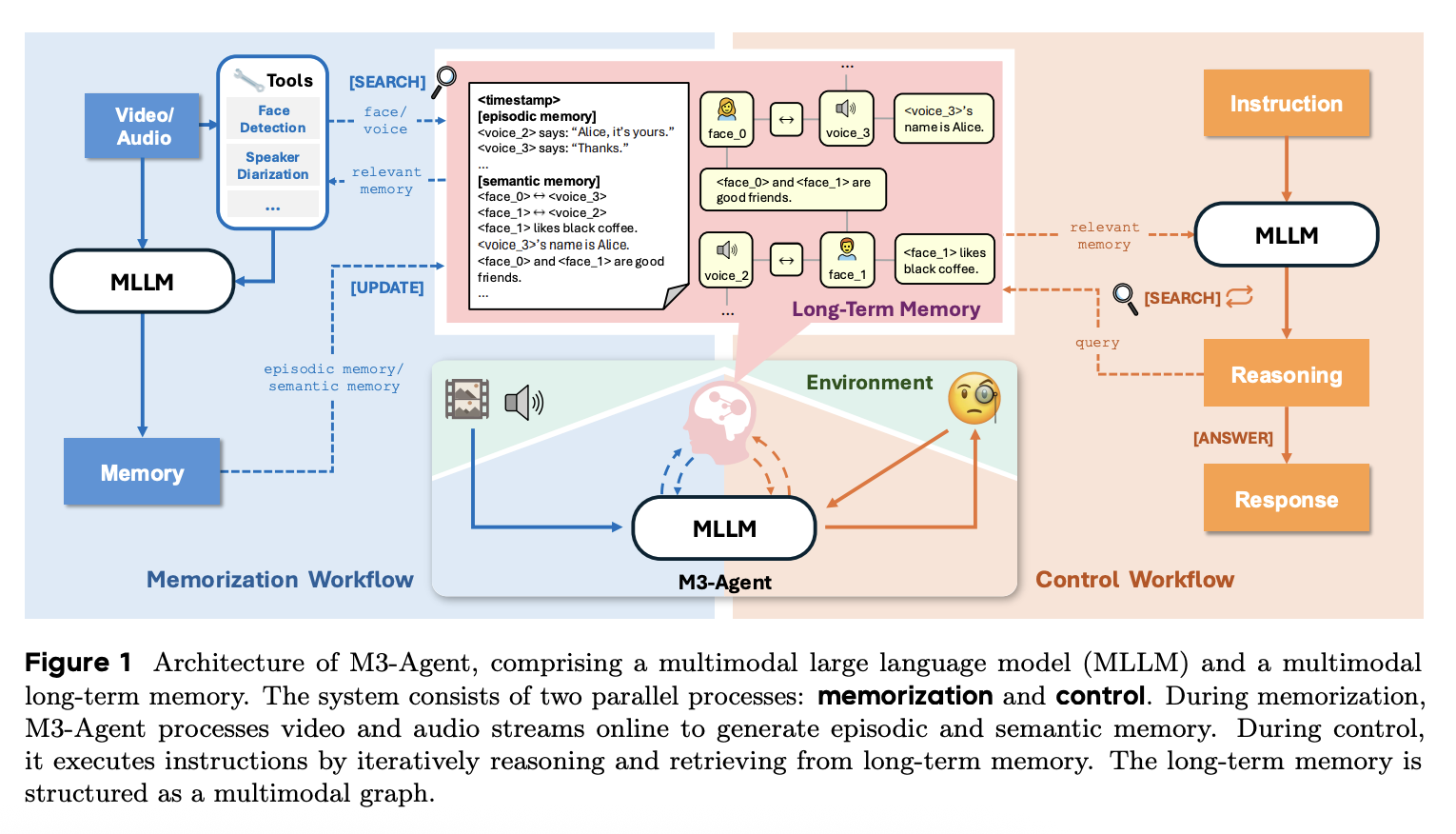
为了实现这些目标,我们提出了M3-Agent,一个具备长期记忆能力的新型多模态 Agent 框架。如图1所示,它通过两个并行的过程运行:(1)记忆,持续感知实时多模态输入,构建和更新长期记忆;(2)控制,解释外部指令,对存储的记忆进行推理,并执行相应的任务。
在记忆过程中,M3-Agent 处理传入的视频流,通过生成两种类型的记忆来捕捉细粒度的细节和高级抽象,类似于人类的认知系统:
- Episodic memory:记录视频中观察到的具体事件。例如,“爱丽丝拿起咖啡说:‘明天早上我喝不了咖啡。’”以及“爱丽丝把一个空瓶子扔进了绿色垃圾桶。”
- Semantic memory:从视频片段中获取常识。例如,“爱丽丝喜欢早上喝咖啡”和“绿色垃圾桶用于回收利用”。
生成的记忆随后会被存储在长期记忆中,它支持多模态信息,例如人脸、声音和文本知识。此外,这些记忆以实体为中心的结构进行组织。例如,与同一个人相关的信息(例如,他们的人脸、声音和相关知识)以图的形式连接起来,如图 1 所示。随着 Agent 提取和整合语义记忆,这些连接会逐步建立。
在控制过程中,M3-Agent 利用其长期记忆进行推理并完成任务。它能够自主地从其长期记忆中检索不同维度的相关信息,例如事件或人物。M3-Agent 并非使用单轮检索增强生成 (RAG) 将记忆加载到上下文中,而是采用强化学习来实现多轮推理和迭代记忆检索,从而提高任务成功率。
记忆任务与长视频描述相关但又超越了它,带来了两个关键挑战:(1)无限信息处理。记忆需要处理无限长的输入流。现有方法优化了架构效率以处理更长但仍然有限的离线视频。相比之下,M3-Agent 可以在线连续处理任意长的多模态流,通过持续的感知和增量的经验整合,更紧密地模仿人类长期记忆的形成方式。(2)世界知识构建。传统的视频描述通常侧重于低级视觉细节,而忽略了高级世界知识,例如人物身份和实体属性,这可能会导致长期语境中的模糊性和不一致性。M3-Agent 通过以实体为中心的记忆结构逐步构建世界知识来解决这个问题。它形成关键实体的丰富的多模态表示,从而实现连贯一致的长期记忆。
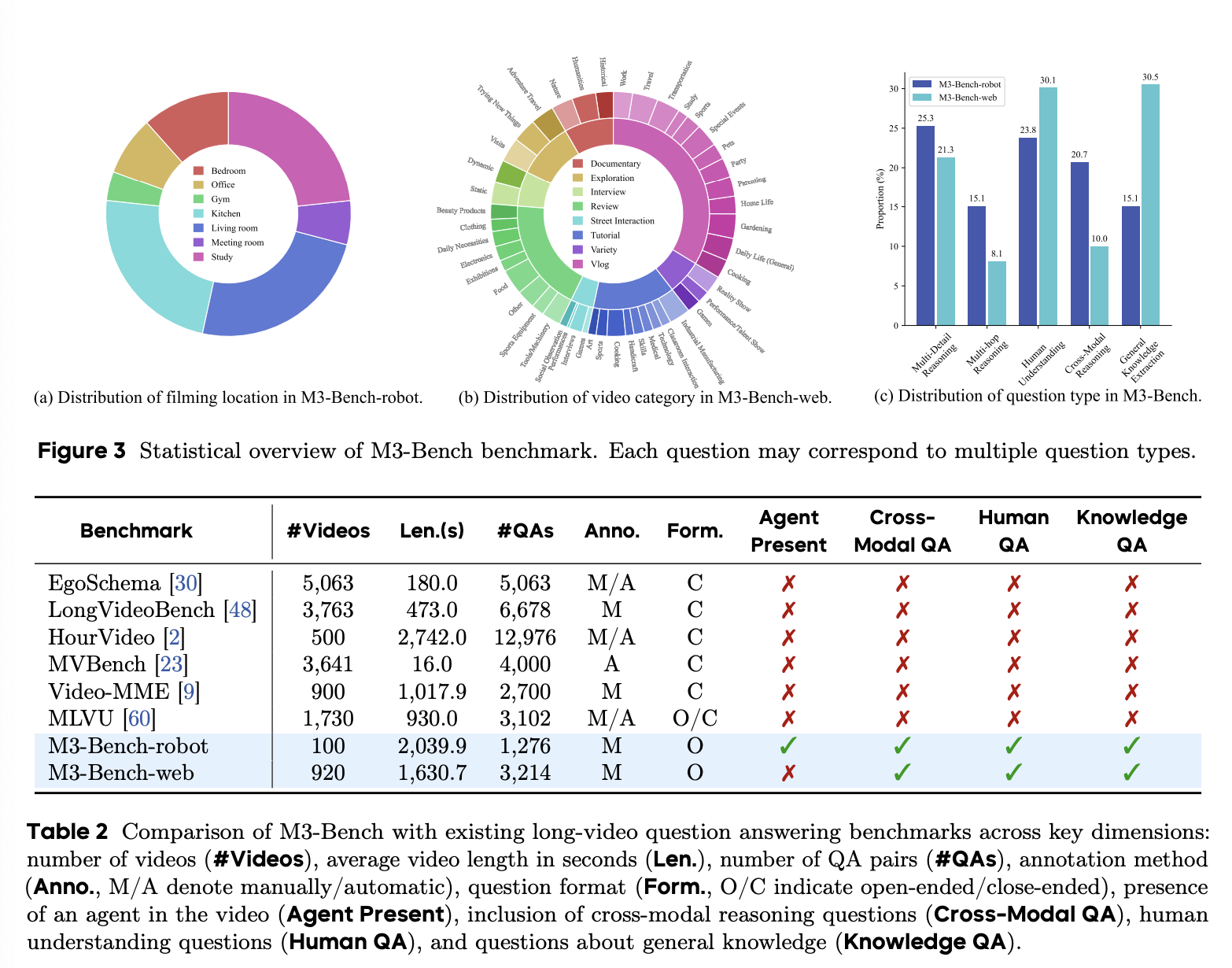
我们利用长视频问答 (LVQA) 来评估 M3-Agent,其中视频模拟了 Agent 接收到的多模态输入流(视觉和听觉)。现有的 LVQA 基准大多侧重于视觉理解,例如动作识别和时空感知,而对依赖于长期记忆的高级认知能力的评估则存在不足,这些能力对于现实世界中的代理至关重要,例如理解人类、提取常识以及执行跨模态推理。为了弥补这一不足,我们推出了 M3-Bench,这是一个全新的 LVQA 基准,旨在评估多模态 Agent 运用长期记忆进行推理的能力。M3-Bench 包含两个来源的视频:(1) M3-Bench-robot,包含 100 个从机器人视角录制的真实世界视频;(2) M3-Bench-web,包含 920 个 YouTube 视频,涵盖更广泛的内容和场景。我们定义了五种问题类型,如表 1 所示,分别针对基于记忆的推理的不同方面。总的来说,我们为 M3-Bench-robot 注释了 1,276 个 QA 对,为 M3-Bench-web 注释了 3,214 个 QA 对。
我们在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上进行了实验。结果表明,通过强化学习训练的 M3-Agent 在所有三个基准测试中均优于所有基准测试。与最强大的基准测试 Gemini-GPT4o-Hybrid(通过提示 Gemini-1.5-Pro 进行记忆和提示 GPT-4o 进行控制来实现 M3-Agent 框架)相比,M3-Agent 在 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率分别提高了 6.7%、7.7% 和 5.3%。我们的消融研究表明了语义记忆的重要性:删除语义记忆会分别使 M3-Bench-robot、M3-Bench-web 和 VideoMME-long 上的准确率降低 17.1%、19.2% 和 13.1%。此外,我们考察了强化学习训练、轮次间指令和推理模式对控制性能的影响。具体而言,强化学习训练在相应的基准测试中分别将准确率提高了 10.0%、8.0% 和 9.3%。移除轮次间指令会导致准确率分别下降 10.5%、5.8% 和 5.9%,而禁用推理模式会导致准确率在三个基准测试中分别下降 11.7%、8.8% 和 9.5%。
本文的主要贡献概括如下:
- 我们推出了 M3-Agent,一个面向具有长期记忆的多模态 Agent 的全新框架。M3-Agent 持续处理实时多模态输入(视觉和听觉),通过生成情景记忆和语义记忆(记忆)逐步构建世界知识,并基于这些记忆进行推理以完成复杂的指令(推理)。
- 我们开发了 M3-Bench,这是一种新的 LVQA 基准,旨在评估多模式代理的记忆和基于记忆的推理的有效性。
- 我们的实验表明,通过强化学习训练的 M3-Agent 在多个基准测试中始终优于基于提示商业模型的 Agent。
2.Related Work
2.1 Long-Term Memory of AI Agents
长期记忆对于人工智能 Agent 至关重要,它使它们能够保留远距离的上下文信息并支持更高级的推理。一种常见的方法是将整个 Agent 轨迹(例如对话或执行轨迹)直接附加到记忆中。除了原始数据之外,一些方法还结合了摘要、潜在嵌入或结构化知识表示。最近的系统进一步构建了复杂的记忆架构,使 Agent 能够更精细地控制内存管理。
然而,大多数现有方法都侧重于 LLM Agent。相比之下,多模态 Agent 能够处理更广泛的输入,并在记忆中存储更丰富的多模态内容和概念。这也带来了新的挑战,尤其是在维持长期记忆的一致性方面。此外,正如人类通过经验获取世界知识一样,多模态 Agent 应该在记忆中形成内部世界知识,而不仅仅是存储经验描述。
2.2 Online Video Understanding
对于多模态 Agent 而言,记忆形成与在线视频理解密切相关,这是一项极具挑战性的任务,需要实时处理视频流并基于过去的观察结果进行决策。传统的长视频理解方法,例如在多模态模型中扩展上下文窗口或压缩视觉 token 以增加时间覆盖范围,对于无限长的视频流而言无法有效扩展。在实际场景中,例如交互式 Agent 场景,为每条新指令重新处理整个视频历史记录在计算上是极其困难的。
为了提高可扩展性,基于记忆的方法引入了记忆模块,用于存储已编码的视觉特征以供将来检索。这些架构适用于在线视频处理。然而,它们面临一个根本性的限制:如何保持长期一致性。由于它们仅存储视觉特征,这些方法难以保持对实体(例如人类身份或随时间演变的事件)的连贯跟踪。
随着大型多模态模型和语言模型的快速发展,苏格拉底模型框架已成为一种颇具前景的在线视频理解方法。通过利用多模态模型生成视频描述作为基于语言的记忆,该方法提高了可扩展性。然而,在复杂且不断变化的视频内容中保持长期一致性方面,该方法仍面临挑战。
3.Datasets
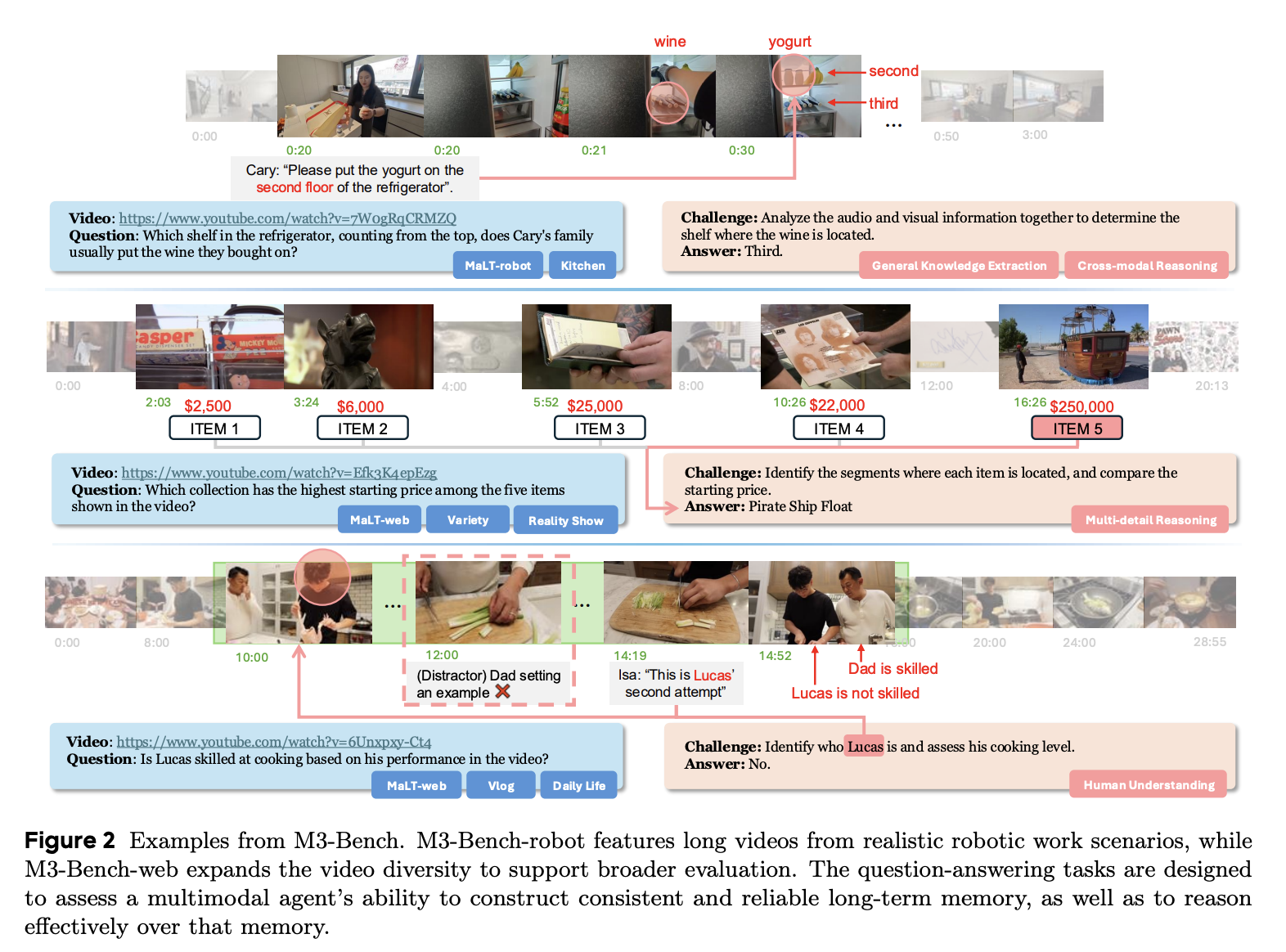
在本节中,我们将介绍 M3-Bench,这是一个 LVQA 数据集,旨在评估多模态智能体基于长期记忆进行推理的能力。M3-Bench 中的每个实例都包含一段模拟智能体感知输入的长视频,以及一系列开放式问答对。该数据集分为两个子集:(1) M3-Bench-robot,包含 100 个以机器人第一人称视角录制的真实世界视频;(2) M3-Bench-web,包含 920 个来自网络的视频,涵盖更广泛的内容和场景。为了全面评估 Agent 回忆过去观察和执行基于记忆的推理的能力,我们整理了五种不同类型的问题,如表 1 所示。总体而言,M3-Bench 的特点是:(1) 长时间的真实世界视频,涵盖与多模态 Agent 部署相关的各种现实场景;(2) 具有挑战性的问题,这些问题超出了浅显的感知理解,需要在长期背景下进行复杂的推理。
图 2 展示了 M3-Bench 的示例。M3-Bench 的整体统计数据如图 3 所示。表 2 提供了与现有 LVQA 基准的比较分析。本节的其余部分分别详细介绍了 M3-Bench-robot 和 M3-Bench-web 的数据收集和标注流程。
3.1 M3-Bench-robot
机器人是多模态智能体的典型代表。通用机器人应该能够保持长期记忆,并运用记忆进行推理以指导自身行动。例如,在处理观察结果时,机器人可能会记住一个人的名字、外套放在哪里,或者咖啡偏好。基于长期记忆的推理能够实现更高级的认知功能,例如推断一个人的性格、理解个体之间的关系,或识别周围物体的功能。为了系统地评估这些能力,我们从机器人的视角录制了一组新的视频,并手动标注了相应的问答对。
Scripts Design。
Video Filming。
Annotations。
3.2 M3-Bench-web
为了进一步增加视频的多样性,我们按照现有做法从 YouTube 收集了额外的视频。
3.3 Automatic Evaluation
我们使用 GPT-4o 作为 M3-Bench 的自动评估器,提示其通过将生成的答案与同一问题的相应参考答案进行比较来评估其正确性。提示模板如表 18 (§ H.1) 所示。
为了验证 GPT-4o 的可靠性,我们构建了一个由 100 个随机抽样三元组组成的测试集,每个三元组包含一个问题、其参考答案以及基于我们的方法或各种基线生成的答案(§5.1)。三位作者独立评估每个生成答案的正确性,并将 GPT-4o 的判断与人类标注的多数票结果进行比较。GPT-4o 与人类评判者的一致率高达 96%,证明了其作为自动评估器的有效性。
4.Approach
如图 1 所示,M3-Agent 由一个多模态 LLM 和一个长期记忆模块组成。它通过两个并行过程运行:记忆,能够连续处理任意长度的视频流并构建终身记忆;控制,推理长期记忆以执行指令。在以下小节中,我们将分别详细介绍长期记忆的存储、记忆和控制。
4.1 Long-Term Memory

长期记忆被实现为一个外部数据库,以结构化的多模态格式(文本、图像、音频)存储信息。具体来说,记忆条目被组织成一个记忆图,其中每个节点代表一个不同的记忆项。每个节点包含一个唯一的 ID、模态类型、原始内容、权重、嵌入以及其他元数据(例如时间戳)。详情请参见表 3。节点通过无向边连接,这些边捕捉记忆项之间的逻辑关系。这些连接充当线索,促进相关记忆的检索。
Agent 通过逐步添加新的文本、图像或音频节点以及连接它们的边,或通过更新现有节点的内容和权重来构建其记忆。构建过程中可能会引入冲突信息。为了解决这个问题,M3-Agent 在推理过程中应用了一种基于权重的投票机制:强化频率更高的条目会积累更高的权重,从而覆盖强化频率较低的冲突条目。此机制确保了记忆图的稳健性和随时间推移的一致性。
Search Tool。为了方便记忆访问,我们提供了一套搜索工具,使 Agent 能够根据特定需求检索相关记忆。具体而言,我们实现了两种不同粒度的搜索机制,如表 4 所示。这些检索机制的详细实现请参见附录 C。
4.2 Memorization
如图1所示,在记忆过程中,M3-Agent 逐个片段地处理传入的视频流,生成两种类型的记忆:情景记忆,从原始视频中捕捉视觉和听觉内容;语义记忆,提取人物身份、属性、关系和其他世界知识等常识。语义记忆不仅丰富了记忆内容,还提供了额外的检索线索,增强了控制过程的检索效果。
Consistent Entity Representation。构建高质量长期记忆的一个关键挑战是如何在任意长的时间跨度内保持一致性地表征核心概念(例如主要人物和物体)。现有研究通常生成基于语言的描述,例如“一个留着胡须的男人”或“一个穿着红裙子的女人”。然而,此类文本描述本质上具有歧义性,并且随着时间的推移容易出现不一致。为了解决这个问题,M3-Agent 保留了原始的多模态特征,并在其长期记忆中构建了持久的身份表征。这种方法提供了一个更稳定、更稳健的基础,确保了长期一致性。
具体来说,我们为 M3-Agent 配备了一套外部工具,包括面部识别和说话人识别。这些工具提取片段中出现的角色的面孔和声音,并从长期记忆中返回其对应的身份。每个提取的面孔或声音都通过 search_node 函数与现有节点关联,或分配给新创建的节点。生成的标识符(face_id 或 voice_id)将作为对应角色的持久引用。通过利用全局维护的记忆图作为统一结构,M3-Agent 确保不同片段的本地记忆之间角色身份映射的一致性,从而形成连贯的长期记忆。
这种方法可以推广到将更多概念(例如关键位置或物体)编码到长期记忆中,从而进一步提高记忆生成的一致性。附录C提供了这两种工具的详细实现。
Memory Generation。有了人脸和语音身份,M3-Agent 可以持续生成情景记忆和语义记忆。每个角色必须通过其 face_id 或 voice_id 来引用。例如:“”,或“”这种机制确保每个角色都与存储在长期记忆中的物理特征明确地联系起来。尤其是在语义记忆中,M3-Agent 可以进行跨模态推理,推断不同实体 ID 之间的关系(例如,将属于同一个人的一张脸和一个语音关联起来)。这些推断出的等价关系随后可用于更新记忆图中人脸节点和语音节点之间的连接。一旦关联起来,该对节点将被视为单个角色。在检索过程中,连接的节点将统一使用共享的 ,从而使模型能够更一致地跨模态推理角色。
关于输出格式,M3-Agent 会将情景记忆和语义记忆生成为文本条目列表。除了以边表示的实体 ID 关系外,每个条目都作为文本节点存储在记忆图中。如记忆存储中所述,冲突信息通过投票机制解决。例如, 对应于 ,但在某些具有挑战性的片段中,系统可能会暂时将其关联到不同的人脸。随着时间的推移,随着正确关联的积累,正确映射()的权重会增加并占据主导地位。这使得系统即使在偶尔出现局部错误的情况下也能稳健地学习并保持准确的知识。
4.3 Control
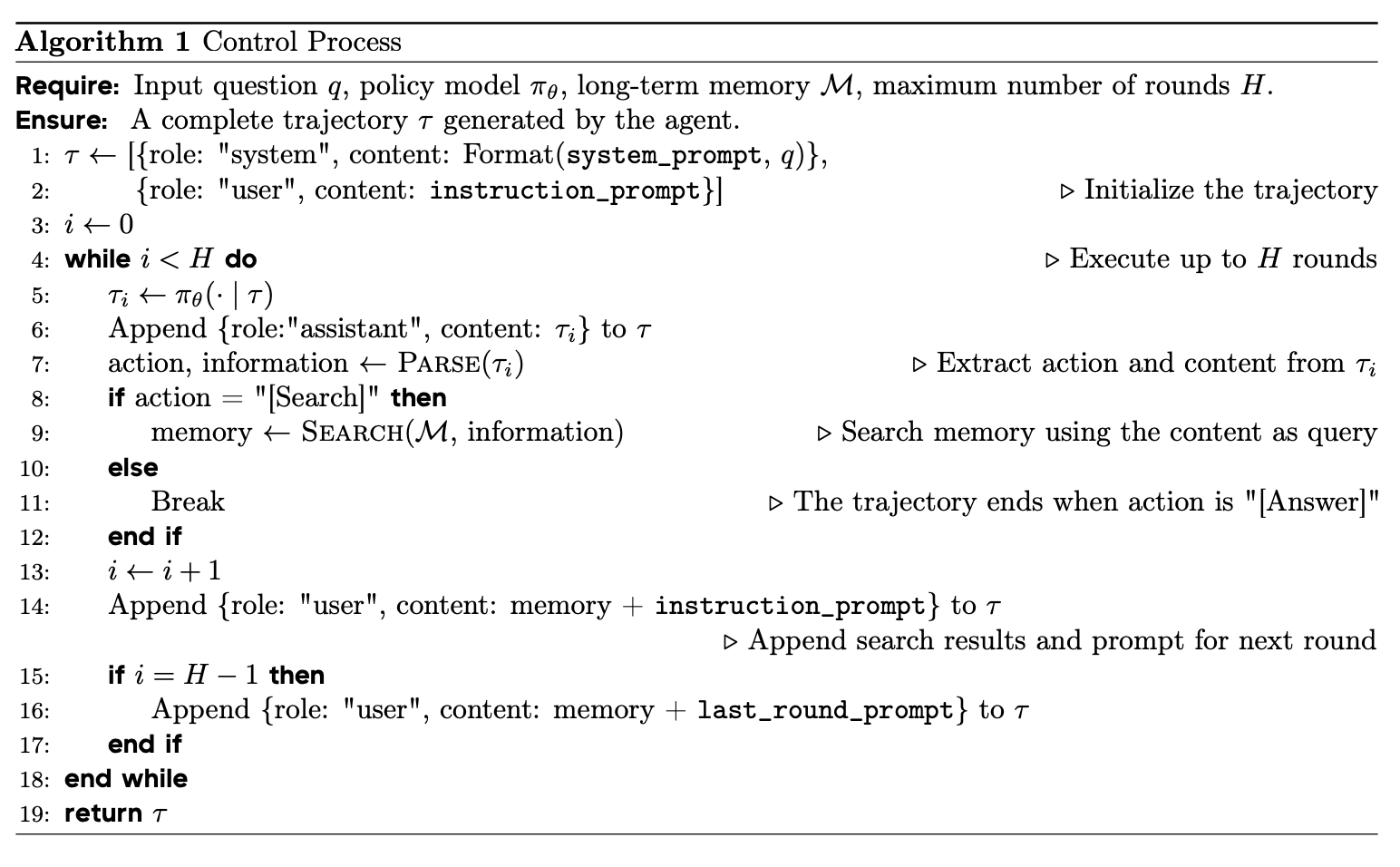
当接收到指令时,控制流程将被触发。如图 1 所示,在控制过程中,M3-Agent 自主进行多轮推理(最多 H 轮),并调用搜索函数从长期记忆中检索相关信息。M3-Agent 可以独立决定调用哪个搜索函数,例如调用 search_clip 检索特定的记忆片段,或调用 search_node 获取特定角色的角色 ID。
具体来说,M3-Agent 中的 MLLM 可以看作是策略模型 。给定问题 和当前的长期记忆 ,控制过程按照算法 1 执行。为了简化此过程,我们设计了三种类型的提示:(1)在每个会话开始时的系统提示,指定总体任务目标。(2)在每轮开始时附加的指令提示(最后一轮除外),提供问题和详细指导。(3)最后一轮提示,仅在最后一轮使用,告知 Agent 这是最后一次回答的机会。具体提示见表 22(§ H.3)。
4.4 Training
我们应用强化学习来优化 M3-Agent。虽然记忆和控制在理论上由一个模型处理,但我们训练了两个独立的模型以实现最佳性能。记忆依赖于强大的多模态理解,而控制则需要强大的推理能力。因此,我们使用不同的基础模型初始化了每个模型:Qwen2.5-Omni,一个支持视觉和音频输入的高级开源多模态模型,用于记忆;Qwen3,一个具有强大推理能力的开源大型语言模型,用于控制。
训练数据来源于我们内部的视频数据集,我们已获得该数据集的模型训练权限。我们收集视频及其对应的问答对,并遵循与 M3-Bench-web 数据集相同的标注标准。训练数据集共包含 500 个长视频,对应 26,943 个 30 秒的片段和 2,736 个问答对。
Memorization。为了提升模型生成所需记忆的能力,我们在 Qwen2.5-Omni-7b 上进行模仿学习,从而创建了 memory-7b-sft。该过程首先构建一个高质量的合成演示数据集。我们将数据集中的每个视频分割成 30 秒的片段,并通过三个阶段生成相应的记忆标注:(1) 情景记忆合成:我们采用一种混合标注策略,联合提示 Gemini-1.5-Pro 和 GPT-4o。GPT-4o 提供帧级线索,作为 Gemini-1.5-Pro 的先验;两者的输出合并后,形成比单独使用任何一种输出都更丰富的叙述摘要。(2) 身份等价性检测:我们提出了一种算法,可以从长视频中自动挖掘高置信度的元片段(即只包含一张脸和一个声音的短独白片段),以构建全局的人脸-声音对应关系。这些元片段提供清晰的身份线索,从而实现准确的人脸-声音配对。一旦建立了全局映射,就可以用它来自动标注任何30秒子片段中的人脸-语音关联。(3)其他语义记忆的合成:我们设计了提示模板,从不同角度提取语义记忆,引导语义记忆包含表10(§D)中列出的信息。数据合成过程的详细信息见附录D。我们总共合成了10,952个样本:10,752个用于训练,200个用于验证。
使用 16 个 GPU 和 80GB 内存进行 3 个 epoch 的微调,学习率为 1e −5,batch size 为 16。
Control。我们首先设置 RL 训练的环境。对于数据集中每个视频,我们使用 memory-7b-sft 生成对应的长期记忆。对于任何给定的问题,智能体被限制为只能在该问题对应视频生成的记忆中进行搜索。
接着,我们使用 DAPO [52] 训练策略模型 πθ,该模型初始化自 control-32b-prompt。对于从训练数据集 𝒟 中采样的每一个问答对 (q, a),策略 πθ 会 rollout 一组 G 条轨迹 {τᵢ}ᵢ₌₁ᴳ,采用 算法 1 所示的算法。对于每条轨迹 τᵢ,最终提交的答案 yᵢ 会被提取并使用第 3.3 节介绍的 GPT-4o 评估器进行评估。 第 i 条轨迹的奖励定义如下:
然后,第 i 个响应的优势 (advantage) 通过归一化组级别奖励 {Rᵢ}ᵢ₌₁ᴳ 来计算:
需要注意的是,在训练过程中,我们只在 LLM 生成的 token 上计算损失。优化目标函数为:
满足约束条件:
其中指示函数 𝕀(τᵢ,ₜ) = 1 当 τᵢ,ₜ 为 LLM 生成的 token 时,反之为 0。表 14 (§ F) 列出了在 DAPO 训练过程中使用的超参数。
5.Experiments
Appendix
C Implementation Details of Tools

在这里,我们提供了第 4.2 节中介绍的表示提取工具的实现细节。
Facial Recognition。为了进行人脸识别,我们以每秒 5 帧的速率均匀采样视频帧。对于每个采样帧,我们使用 InsightFace 库中的 buffalo_l 预定义模型套件提取人脸属性,包括边界框坐标、身份嵌入以及检测/质量得分。低质量的检测结果(例如长宽比异常或置信度得分极低的检测结果)将被丢弃。然后,我们对剩余高质量人脸的嵌入应用 HDBSCAN 聚类,按角色身份对其进行分组。这将生成一组可靠的、按角色聚类的人脸表征。
Voice Identification。为了进行说话人识别,我们使用 Gemini-1.5-Pro 提取与不同说话人声音对应的音频片段,同时对每个片段进行自动语音识别 (ASR)。为确保可靠性,短于 2 秒的片段会被过滤掉。然后,我们应用语音嵌入模型 ERes2NetV2 将每个片段编码为特定于说话人的表示。基于生成的语音嵌入,我们对与同一说话人(即具有相似声音特征的说话人)对应的片段进行聚类和合并。此过程生成一组高质量的说话人表示,并按角色分组。用于语音处理的提示如表 9 所示。
Search。所有基于记忆的检索均通过 最大内积搜索 (MIPS) 实现,并针对不同模态进行了特定适配。
每个面部和语音节点都维护一组具有代表性的特征快照。当从视频片段中提取新的面部或语音特征时,我们会计算每个提取特征与该节点所有存储快照的平均余弦相似度。若相似度最高的节点超过预设阈值(图像为 0.3,语音为 0.6),则认为匹配成功;否则,创建一个新节点。匹配的节点会随着新特征的加入而更新,以逐步优化其表示。
对于文本记忆,我们在输入查询与所有已有文本节点之间应用 MIPS,使用 OpenAI 的 text-embedding-3-large 作为嵌入模型。为了支持多条结果检索,我们采用 top-k 检索,并设定相似度阈值 t。具体来说,我们返回 k 个最相关的节点,这些节点的相似度需超过阈值 t。为了保证检索的一致性,我们还进行 片段级检索:每个视频片段会根据其记忆条目中的最高相似度进行打分,并返回得分最高的片段。在所有实验中,我们采用了相对严格的超参数设置 (k = 2, t = 0.5),以减少检索过程中的随机性,并确保不同模型之间的一致性评估。