TIP: Token Importance in On-Policy Distillation
论文链接:https://arxiv.org/pdf/2604.14084
代码链接:https://github.com/HJSang/OPSD_OnPolicyDistillation
摘要
On-policy 知识蒸馏(OPD)在 teacher 的逐 token 监督下,训练 student 学习其自身的 rollout,但并非所有 token 位置都同等重要,现有关于 token 重要性的观点并不完整。我们提出以下问题:在 OPD 中,哪些 token 携带最有用的学习信号?我们的答案是,信息丰富的 token 来自两个区域:student 熵高的位置,以及 student 熵低但师生差异大的位置——在这些位置,student 过于自信且判断错误。经验表明,student 熵是一个有效的但结构上不完整的指标。基于熵的采样保留 50% 的 token,其效果与全 token 训练相当甚至更优,同时可将端到端峰值训练内存减少高达 47%;在更积极的保留策略下,内存节省可达 58%。但仅凭熵无法反映第二个重要的区域。当我们筛选出低熵、高分歧的 token 时,仅使用不到 10% 的 token 进行训练,其结果几乎与使用全部 token 的基线模型一致。这表明,尽管仅基于熵的规则几乎无法识别过度自信的 token,但它们仍然携带着密集的修正信号。我们利用 TIP(Token Importance in on-Policy distillation)来组织这些发现。TIP 是一个基于 student 熵和 teacher 分歧的双轴分类体系,它解释了为什么熵虽然有用但结构上并不完整,并启发了结合不确定性和分歧的类型感知选择规则。我们在 MATH-500 和 AIME 2024/2025 数据集上,以及在用于长期智能体规划的 DeepPlanning 基准测试中,验证了这一结论。在 DeepPlanning 基准测试中,仅使用 20% 的 Q3 token 进行训练,其结果优于使用全部 token 的 OPD 模型。我们的实验是通过扩展开源 OPD 存储库 https://github.com/HJSang/OPSD_OnPolicyDistillation 来实现的,该存储库为复现这项工作提供了实际的训练基础,并支持在有限的 GPU 预算下对更大的模型进行内存高效的蒸馏。
1.介绍
知识蒸馏通过训练大型 teacher 模型的输出分布,将能力传递给小型 student 模型,是小型模型容量快速增长的主要驱动力。On-policy 蒸馏(OPD)中,student 模型生成自身的响应,并在每个 token 处从 teacher 模型的修正中学习。由于上下文由 student 模型生成,因此 token 的重要性是每个位置上 student-teacher 状态的一个属性。这就引出了一个直接的问题:哪些 token 携带最有用的学习信号?
我们的核心论点很简单。在 OPD 中,信息丰富的 token 来自 token 状态空间的两个区域:(1) student 熵高的位置,此时 student 尚不确定,仍在形成预测;(2) student 熵低但师生差异大的位置,此时学生自信但与教师的预测不一致。仅凭熵值即可轻松检测到第一个区域:通过基于熵的采样保留 50% 的 token,其效果已与全 token 训练相当甚至更优,同时显著降低了端到端训练所需的内存。第二个区域则容易被忽略:在更激进的保留策略下,仅基于熵的选择会丢弃过度自信的 token ——即 student 在 teacher 强烈反对的后续预测上出现明显的峰值——因为它们的低熵值使其与正确解决的 token 难以区分。
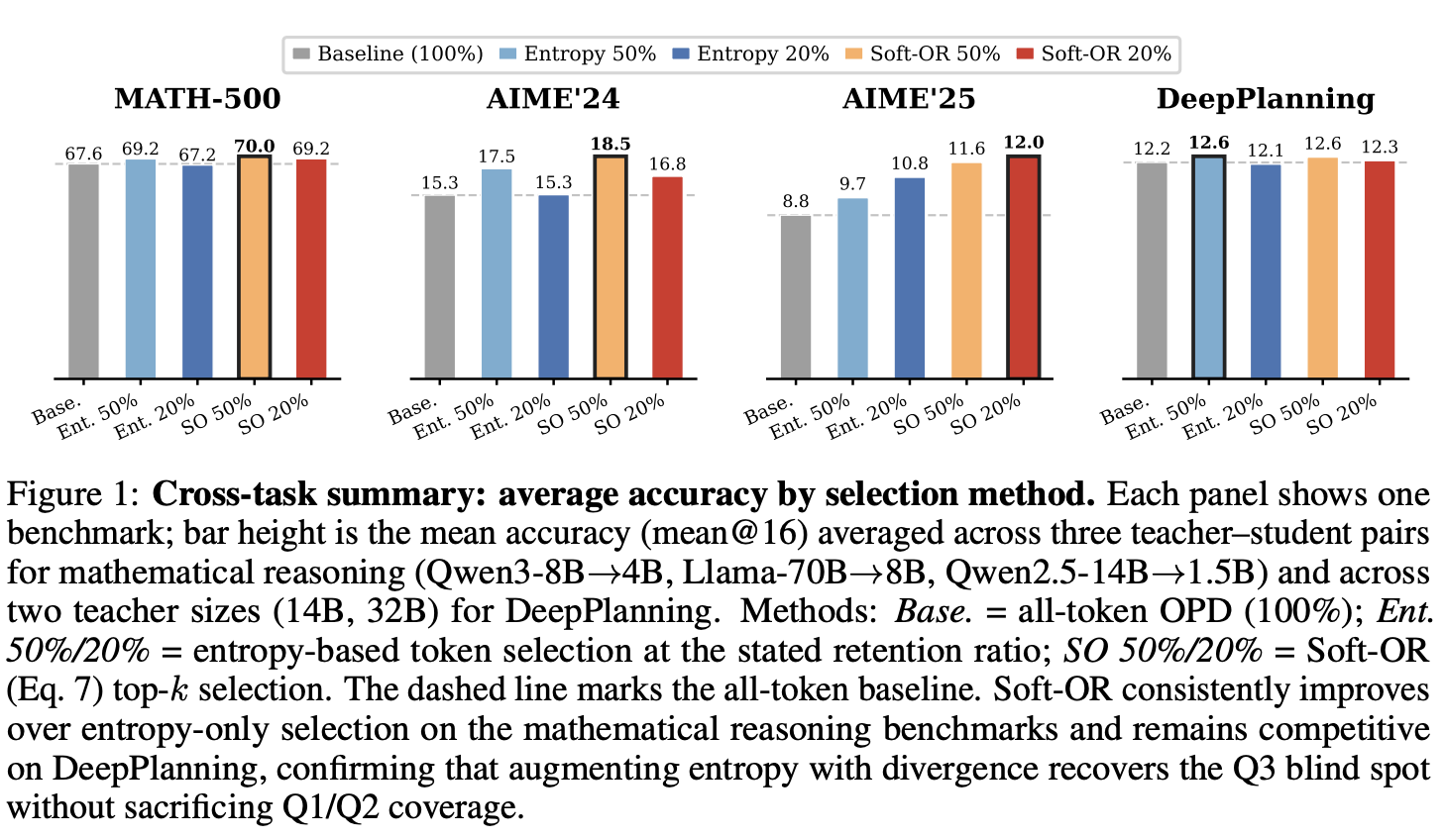
我们使用 TIP 来构建这一图景,TIP 是一个双轴分类系统,它将 student 的熵值和师生差异划分为四个象限(第4节)。从概念上讲,熵值是一个有效但结构上不完整的指标:它必然会将“自信且正确”与“自信但错误”混淆,而无参数的 Soft-OR 评分则弥补了这一盲点(第5节)。实验表明,在数学推理方面,该综合评分始终优于仅使用熵值进行选择的方法,并且在智能规划方面也保持竞争力,尽管在智能规划中仅使用 Q3 进行选择的效果最佳(第7节)。
Contributions。
- 我们提出了 TIP,这是一个双轴分类法,它根据 student 熵和师生差异来组织 token 重要性,不需要验证标签,也不需要标准 OPD 损失之外的额外计算。
- 我们证明熵是一个有效的但结构上不完整的指标,并证明任何仅基于熵的分数在结构上对过度自信的 token 是盲目的,而无参数的 Soft-OR 分数则弥补了这一盲点(命题 1-2,备注 1)。
- 我们在多个数据集和模型系列中验证了该分类法,并表明 Soft-OR 在数学推理方面始终优于仅基于熵的选择,同时在 DeepPlanning 的长期智能体规划中保持竞争力,而其中仅基于 Q3 的选择最为强大。
2.Related Work
Curriculum learning and importance sampling。并非所有训练样本的贡献都相同,这一理念源于课程学习和自主学习,它们会根据难度对样本进行排序或加权。重要性抽样将这一理念扩展到梯度估计:Katharopoulos and Fleuret [2018] 通过梯度范数选择小批量元素,而 Ren et al. [2018] 通过元梯度学习每个样本的权重。这些方法都在样本层面上进行操作。我们的工作将粒度扩展到序列中的单个 token,其中相关的维度是学生的不确定性和师生之间的分歧,而不是标量难度分数。
Off-policy vs. on-policy distillation。经典的序列级知识蒸馏(KD)使用教师生成的序列(off-policy)来训练学生模型。而 On-policy distillation 则允许学生生成自己的 rollout,并逐 token 地应用教师监督,从而避免了 off-polcy 数据中固有的训练集-测试集分布不匹配问题。Sang et al. [2026] 进一步证明,on-policy 反向 KL 自蒸馏可以将冗长的推理链压缩成更短的推理链。蒸馏已被证明在各种场景下都有效——从预训练到极端压缩,再到扩展推理能力,超越强化学习(RL)本身所能达到的水平。由于 on-policy 蒸馏中 token 的重要性取决于学生模型在每个位置的自身分布,因此无法预先从教师输出中计算出来——它必须在线评估。这使得选择哪些 token 进行训练与 off-policy 样本选择在本质上是不同的问题。
Response-level selection。有几种方法在序列层面上进行操作:PACED 使用基于学生模型通过率的 Beta 核加权函数,自适应地优先处理中等难度的样本,过滤掉过于简单和过于复杂的数据,从而提高蒸馏效率;LION 则使用质量信号。这些方法选择用于训练的 rollout,但对响应中的所有 token 一视同仁。一个与之相关的问题——也是我们研究的内容——是响应中的哪个 token 携带的信号最强。
Token-level importance in distillation and RL。在强化学习中,Wang et al. [2025c] 证明高熵“分叉 token”驱动了大部分梯度信号,Cui et al. [2025] 进一步揭示了 token 对数概率和优势之间的协方差驱动了策略优化期间的熵崩溃,SPINE 通过仅使用熵带正则化更新决策关键分支点,将这一思想扩展到了测试时强化学习,而 Xu et al. [2026a] 则将过度自信错误识别为一种关键的失效模式。在蒸馏过程中,AdaSwitch 基于差异在 student 指导和 teacher 指导之间切换;Entropy-Aware OPD 基于 teacher 熵调整损失函数;SelecTKD 允许 teacher 通过提议-验证过程验证 sutdent 提出的 token,并对被拒绝的位置进行掩码或降低权重;LeaF 使用梯度引导的 teacher 比较来识别和剪枝蒸馏过程中的混淆 token;AdaKD 将基于差异的词元选择器(LATF,基于 Hellinger 距离的 top-r%)与词元级温度缩放(IDTS)相结合。除了微调之外,EntroDrop 还表明,在预训练期间丢弃低熵 token 可以提高多轮训练下的泛化能力,这为高熵位置携带大部分学习信号提供了独立的证据。EDIS 进一步证明,token 熵的时间动态(而不仅仅是其大小)可以诊断推理轨迹的正确与错误。
一些并行研究也探索了在蒸馏和微调过程中对 token-level 进行加权、剪枝或压缩的方法。其中最密切相关的是 AdaKD,其 LATF 模块通过师生 Hellinger 距离进行硬性 top-r% 选择——我们在附录 B.2 中对这种仅考虑差异性的视角进行了消融。我们的 Q3 规范并非对“大差异 token”的重新命名:它由低学生熵和高分歧性的结合定义,这两个维度导致了不同的选择(表 3 与表 8)。AdaKD 消融实验本身也支持这一点:仅 LATF 在 Qwen2-1.5B 数据集上仅能带来 +0.04 的平均 ROUGE-L 值提升(见其表 3a),AdaKD 的全部增益来自一个正交温度缩放模块 (IDTS);我们预算匹配的比较(附录 B.2)也得出了相同的结论。除此之外,我们的工作证明,任何仅基于熵的规则在结构上都无法识别低熵、高发散度的标记(命题 2),并提出了一种无参数的 Soft-OR 分数,可以明确地恢复这一区域,并通过数学推理和长期智能规划进行了验证。
3.Setup
令 表示一个冻结的 teacher, 表示一个在词表 上可训练的 student。抽取一个 prompt ,student 生成一个 rollout ,teacher 对每个位置进行评分。位置 的上下文为 。标准的 on-policy 蒸馏损失为:
我们用两个量来描述每个 token 的位置,这两个量都在训练过程中已经计算出来:
Student entropy。
高 值表示学生缺乏自信;低 值表示学生充满信心。
Teacher–student divergence。
值较高表示 teacher 与 student 意见不一致。这是每个 token 本身的损失——无需额外计算。
这两个量定义了我们研究 token 重要性的平面。本文的实证问题是:有用的训练信号是否集中在 平面的特定区域。
4.TIP Taxonomy: A Two-Axis View of Token Importance
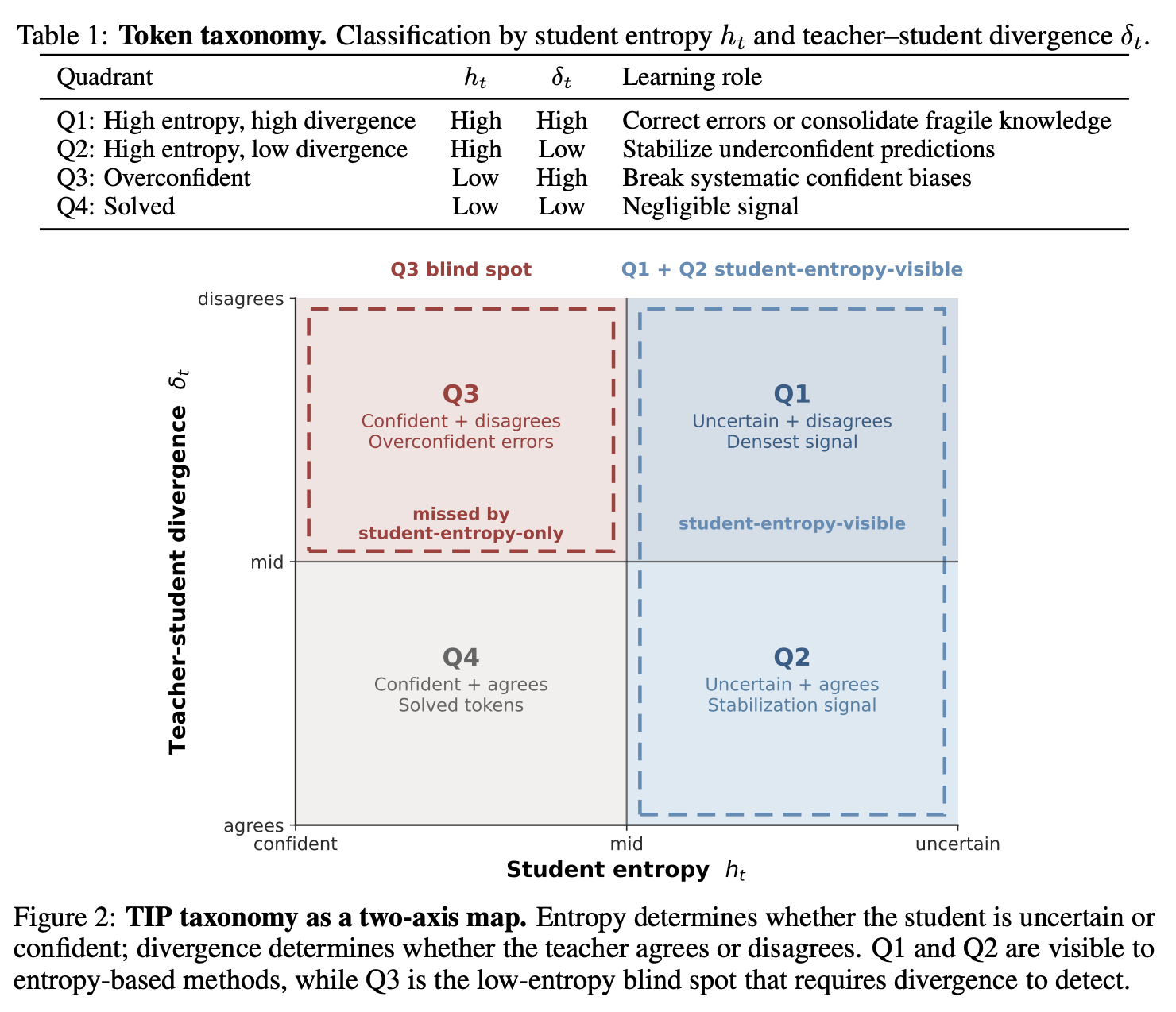
我们根据标准 OPD 训练中已计算出的两个轴来组织 token 重要性:学生熵 和师生差异 。这两个轴交叉后得到四个象限(表 1,图 2)。这些象限极不平衡:Q4 约占所有 token 的 40-47%,Q1 和 Q2 合计占 40-52%,而 Q3 在实验设置中,在所有模型系列和数据集中仅占 3-15%,但却承载了不成比例的校正信号(第 7.3 节;附录 B.5 给出了具有代表性的 token-level 示例,特别是 Q1 和 Q3 的示例)。
5.Theoretical Analysis
该分类法提出了三个预测:高熵 token 相对于已解决 token 应携带显著的学习信号(Q1/Q2 ≫ Q4);仅基于熵的选择会遗漏特定类别的 token(Q3);而添加散度则应能恢复这些 token。我们在下文中对这些预测进行形式化阐述,并在第 7 节中对每个预测进行实验验证。具体而言,我们证明了:(1)oracle token 权重会抑制已解决 token,同时允许高熵 token 和过度自信的纠正 token 都具有正权重(Proposition 1);(2)仅基于熵的评分在结构上无法识别 Q3(Proposition 2);以及(3)通过散度增强熵可以恢复对所有信息象限的覆盖(Remark 1)。
5.1 Oracle Token Weight
我们希望确定哪些 token 能最大程度地加速训练。我们将其形式化为:哪些 token 的权重 能在一次梯度下降后最小化预期损失?
令 为每个 token 的梯度,,并定义 和 。在 平滑性和忽略跨 token 协方差项的 token 可分离近似(附录 A.2)下,加权步长 满足代理界:
Proposition 1 (Oracle token weight)。当 时,界限最小,每个 token 的下降 。
事实上,该界限在各个 token 之间是可分离的,因此每个坐标独立地最小化 。求导得到 ,因此 。代入后得到 。
这是一个预测量(取决于种群梯度),但它给出了清晰的解释:信息丰富的 token 的梯度与下降趋势吻合良好,且能量不高。在四个象限中:
- Q1:较大的 (不确定性下的强修正)⇒ 当梯度噪声不太大时,较高的 oracle 权重。
- Q2:适中的 (稳定置信度不足的预测)⇒ 不可忽略的 oracle 权重
- Q3:正值,有时较大的 (尽管熵低,但真实的校正信号)⇒ 仅基于熵的规则所忽略的不可忽略的 oracle 权重。
- Q4:接近于零的 ⇒ 可忽略的 。
因此,可靠的结论不是 Q1、Q2 和 Q3 之间的固定总排序;而是具有正下降信号的信息区域与信号接近于零的 Q4 之间的分离。
5.2 A Signal-to-Curvature View
上述 oracle 界限可以与更简单的局部诊断图景一起解读。对于单个 token,考虑前向 KL/交叉熵诊断损失作为学生 logits 的函数,其中梯度 ,Hessian 矩阵 。加权步骤给出了二阶近似。
因此,局部最优解满足
因此,token 重要性是一种信号与曲率之间的权衡:分子衡量一阶纠正信号,而分母衡量在该 token 上移动的局部二阶成本。
这种观点阐明了为什么仅凭熵是不完整的。高熵样本通常具有有用的校正信号,这解释了为什么熵是一个有效但结构上不完整的代理变量。但是,Q3 样本也可能具有较大的分子,因为 teacher 强烈反对 student 自信的预测,而其低熵的 student 分布导致 softmax 曲率较小(附录A.1)。Q4样本也处于低曲率状态,但其师生分歧较小,因此分子接近于零。因此,Q3 和 Q4 之间的区别在于信号,而非熵。
实际上, 无法获取,因为它取决于 population-level 的数量。一个自然的替代指标是 student 熵 ,但任何此类分数在结构上都忽略了 Q3:
Proposition 2 (Blind spot)。令 为任意非递减得分函数,且 (例如, 或 )。那么,Q3 token——其可能具有 ——会得到 。仅靠熵无法区分“自信且正确”(Q4)与“自信但错误”(Q3)。
附录 B.5 对此作了具体说明:示例 1、3 和 4 展示了 的 Q3 token,这些 token 会被仅基于熵的规则丢弃;而示例 2 和 5 展示了形成对照的高熵 Q1 情形,这些是基于熵的规则能够捕捉到的。
由于散度 已经作为损失的一部分被计算出来,因此自然的修正方式是构造一个在任一轴被激活时都非零的得分。我们定义 Soft-OR 得分,并使用经过 min-max 归一化的输入 :
这是无参数的:只要熵或散度中任意一个非零, 就非零,而不需要调节系数。
Remark 1 (Soft-OR fixes the blind spot)。对于任意满足 且 的 Q3 token,熵代理会给出 (命题 2),但 。与此同时,Q4 token()仍会被抑制:。Q1 token 保持最高得分,因为 和 都很大()。因此,Soft-OR 得分在恢复 Q3、抑制 Q4 的同时,保留了对高熵区域的覆盖,并且不需要 或 。
Empirical predictions。表2将每个理论结果与其实验验证结果对应起来。

6.Method: Type-Aware Token Selection
给定保留比例 ,我们按照 Soft-OR 得分保留排名前 比例的 token,其中 (公式 7):
训练损失为:
令 会恢复为仅基于熵的选择;加入 则会额外提升 Q3 token。在实践中,在计算 之前,我们会在每个 batch 内裁剪掉熵值最高的 2%,然后应用 min-max 归一化以得到 ,这可以抑制罕见离群值,并稳定不同 batch 之间的 token 排序。该得分是无参数的,并且 与 都已经在标准蒸馏过程中被计算出来,因此唯一的额外成本是这种裁剪后的 min-max 归一化以及 top- 排序——每个 rollout 的复杂度为 ,相较于前向和反向传播可以忽略不计。