Multimodal OCR: Parse Anything from Documents
论文链接:https://arxiv.org/pdf/2603.13032
代码链接:https://github.com/rednote-hilab/dots.mocr
摘要
我们提出了一种名为 dots.mocr 的 Multimodal OCR (MOCR) 文档解析范式,它将文本和图形联合解析为统一的文本表示。与传统的 OCR 系统专注于文本识别并将图形区域裁剪为像素不同,我们的方法将图表、示意图、表格和图标等视觉元素视为一级解析目标,使系统能够在解析文档的同时保留元素间的语义关系。该方法具有以下几个优势:(1)它将文本和图形都重构为结构化输出,从而实现更忠实的文档重构;(2)它支持对异构文档元素进行端到端训练,使模型能够利用文本和视觉组件之间的语义关系;(3)它将先前被丢弃的图形转换为可重用的代码级监督信息,从而释放嵌入在现有文档中的多模态监督信息。为了使这种范式能够大规模应用,我们构建了一个综合数据引擎,该引擎包含 PDF、渲染后的网页和原生 SVG 资源,并通过分阶段预训练和有监督微调训练了一个紧凑的 3B 参数模型。我们从文档解析和结构化图形解析两个方面评估了 dots.mocr。在文档解析基准测试中,它在我们的 OCR Arena Elo 排行榜上仅次于 Gemini 3 Pro,位列第二,超越了现有的开源文档解析系统,并在 olmOCR Bench 测试中取得了 83.9 分的新最佳成绩。在结构化图形解析方面,我们的模型在所有图像到 SVG 的基准测试中都实现了比 Gemini 3 Pro 更高的重建质量,并在图表、UI 布局、科学图表和化学图谱上展现了强大的性能。这些结果展示了一条构建用于多模态预训练的大规模图像到代码语料库的可扩展路径。代码和模型可在 https://github.com/rednote-hilab/dots.mocr 公开获取。
1.介绍

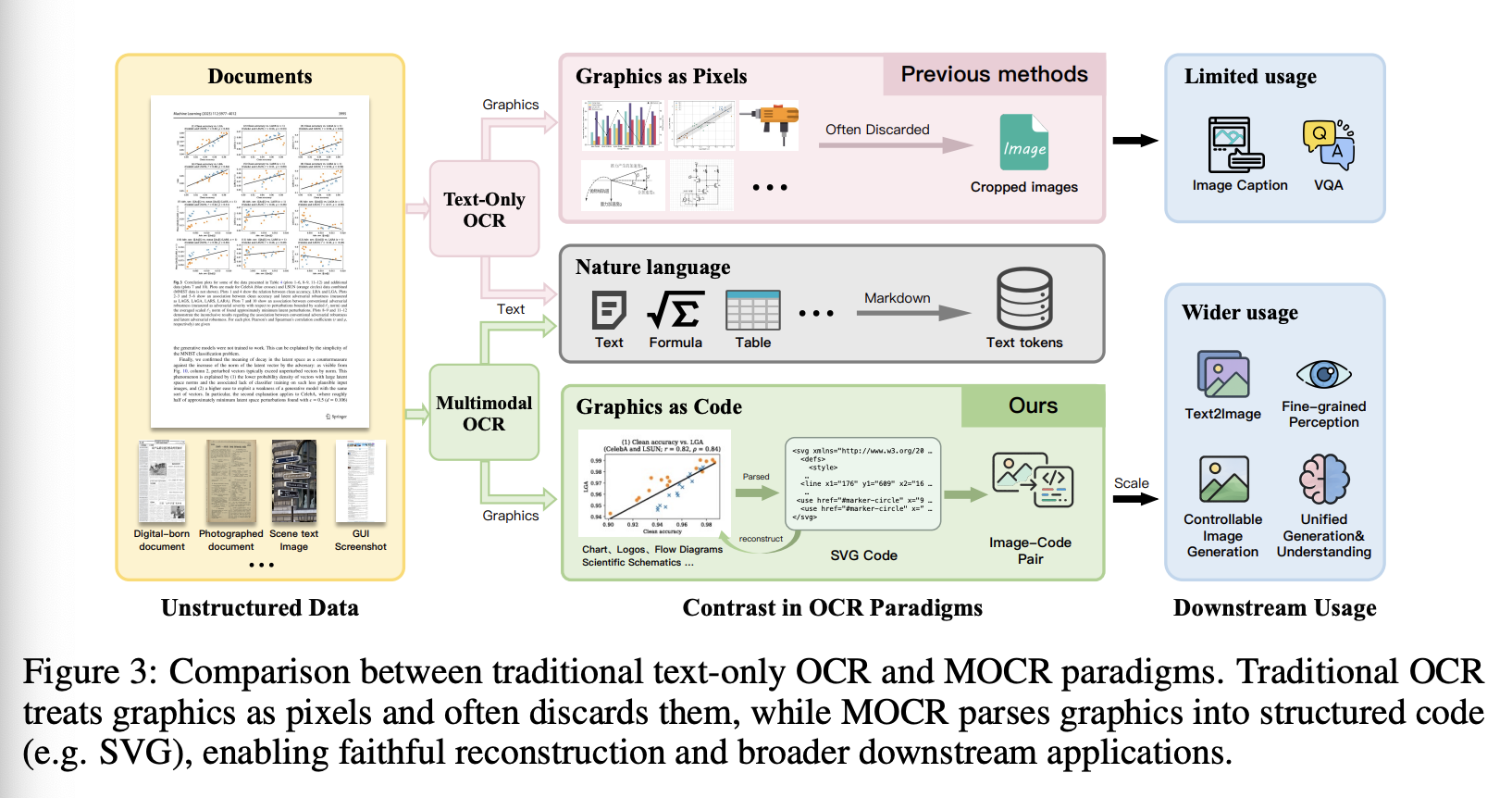
在大语言和多模态模型时代,文档解析已成为预训练和检索的核心数据引擎,因为它决定了能够从海量的PDF、扫描件和屏幕截图(这些文档存储着现实世界的知识)中恢复多少可靠的结构化监督信息。然而,文档不仅通过文本传递信息,还通过图表、示意图、流程图、用户界面元素和科学插图等图形来传递信息。现有的文档解析流程仍然主要以文本为中心:它们专注于识别和组织文本内容,而将非文本元素视为图形区域,并简单地将其裁剪为像素。因此,文档图形中编码的大量结构和语义信息被丢弃,使得当前的文档解析本质上是有损的,并限制了可以从文档中提取的监督信息量。
视觉语言模型的最新进展使得从文档图像中恢复结构化表示(而非仅仅将其保存为像素)变得越来越可行。除了图像描述之外,现代模型还展现出越来越强的能力,能够根据图像生成可执行表示,从而从视觉输入中重建底层结构。早期将用户界面屏幕截图转换为代码的工作(例如 pix2code)探索了这一方向,而更新的方法则将其扩展到更丰富的程序空间,例如 SVG,其中图像可以转换为可渲染的矢量代码。这些进展表明,文档解析可以超越文本提取,转而旨在恢复文档中所有包含信息的元素,并将其作为结构化输出。
基于此观察,我们引入了 Multimodal OCR (MOCR),这是一种文档解析范式,旨在解析文档中的任何内容,包括文本、布局结构、表格以及信息密集型图形,例如图表、示意图、图标和 UI 组件,如图 1 所示。与主要恢复文本而将图形区域作为栅格裁剪的传统 OCR 流程(图3)不同,MOCR 将文本和视觉元素都视为一级解析目标,并将它们转换为可重用的结构化输出。具体而言,文档图形与文本内容一起表示为可渲染的 SVG 代码,从而可以将图表、示意图和其他视觉元素重建为结构化表示,这些结构化表示可以作为下游推理和多模态预训练的可重用监督信息。
尽管 MOCR 为解析文本和图形元素提供了一个统一的范式,但使其可扩展仍然面临挑战。首先,图形的监督信息匮乏,因为真实文档很少提供与视觉元素对齐的代码表示。其次,可渲染代码本质上是不唯一的,因为不同的代码可以产生视觉上相同的输出,这需要在训练过程中进行归一化和质量控制。第三,该任务需要精确的视觉基础以及长序列结构化生成,这比纯文本光学字符识别(OCR)要困难得多。
为了应对这些挑战,我们开发了一个名为 dots.mocr 的可扩展系统,该系统使用涵盖 PDF、渲染网页和原生 SVG 图形的大型数据引擎进行训练。我们的训练遵循分阶段的方法,将大规模 OCR 监督与来自自然结构化源的图形中心信号相结合,同时应用归一化和质量控制,以使预测代码与真实渲染结果保持一致。这种设计使我们的方法能够在单一统一的架构内泛化到传统文档解析和结构化图形重建。
这项工作的主要优点总结如下:
- 我们引入了 MOCR,这是一种通用的 OCR 范式,它将视觉符号提升为一级的解析目标,并将文档图形恢复为可重用的、可渲染的代码,而不是栅格裁剪,从而从现有文档中解锁了新的结构化监督来源。
- 我们的系统 dots.mocr 提出了一种统一的学习公式,通过归一化和训练稳定化,使生成的代码与渲染保真度保持一致,从而在稀疏和非唯一程序监督下实现大规模的实用性,并由完全从头开始训练的视觉编码器提供支持。
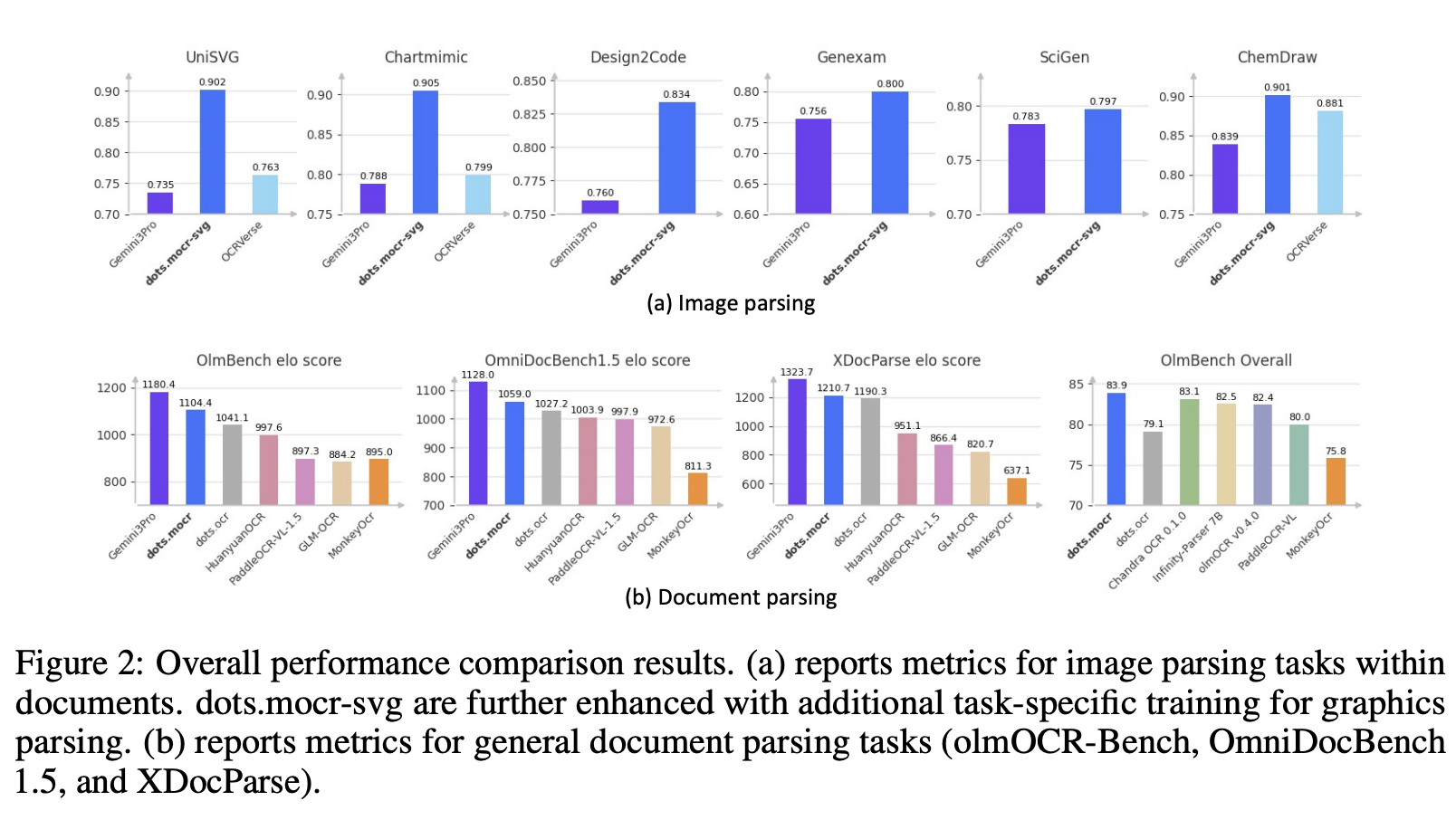
- dots.mocr 在文档解析和结构化图形重建方面表现出强劲而均衡的性能(图 2),在 OCR Arena Elo 排行榜上仅次于 Gemini 3 Pro,在 olmOCR-Bench 上创造了新的最先进水平,在图像到 SVG 基准测试中超越了 Gemini 3 Pro,并且在 OCRBench 上除了解析之外,还保持了强大的视觉基础和推理性能,所有这些都在一个紧凑的 3B 参数模型中。
2. Related Work
2.1 Text Parsing
近年来,文本解析方法发展迅速,旨在从各种文档格式(包括 PDF、网页、幻灯片、电子表格、扫描文档和场景文本图像)中提取和分析文本内容。现有方法主要分为三类,具体取决于它们是否以及如何利用视觉语言模型 (VLM)。传统系统通常遵循多阶段流程,包括布局分析、检测、识别和阅读顺序预测,例如 pp-structurev3,它提供了模块化设计和面向部署的集成;然而,它们可能会在各个阶段累积错误。第二类方法使用 VLM 组件增强此类流程,以在保留显式结构的同时增强语义推理,例如 MonkeyOCR、MinerU 2.5 和 PaddleOCR-VL;这些混合方法在许多场景下提高了理解能力,但仍然主要关注文本,并且继承了一些流程复杂性。最后,端到端的基于 VLM 的模型将解析视为直接的视觉到文本生成,例如 DeepSeek-OCR、GOT-OCR 和 OCRVerse,通过大规模预训练实现了强大的跨领域泛化能力,但仍然面临着在密集布局(例如表格和公式)下保持忠实结构的挑战。
2.2 Structured Graphics Parsing
结构化图形解析将文本解析扩展到布局、几何形状和样式线索(例如形状、线条和空间关系)的恢复,旨在将图像转换为可执行、可渲染的表示形式(例如 HTML、LaTeX、SVG 或 Python),而不是字符级转录。网站和 UI 解析通过将屏幕截图转换为类似 DOM 的结构或前端代码来体现这一方向:Pix2Struct 预训练视觉到文本的转换,以从蒙版网页图像中生成简化的 HTML;Design2Code 对屏幕截图到实现的生成进行基准测试并突出显示持续存在的保真度差距;OmniParser 直接从像素中提取 UI 元素。除了 HTML 之外,目标语言通常也是领域驱动的,例如 Plot2Code、ChartMimic 和 ChartMaster 通过 Python 程序渲染来重建图表,而 ChemDraw 风格的设置则将分子图映射到 SMILES 等结构化字符串。SVG 已成为一种特别富有表现力的目标格式,因为它能够显式地编码几何形状和样式;最近的一些方法将图像转换为 SVG 格式,用于图标和矢量图形,例如 StarVector、OmniSVG 和 UniSVG。虽然像 OCRVerse 这样的更广泛的统一方案通过提示将 OCR、图表解析、SVG 重建、网页布局生成和其他结构化目标整合到一个单一的视觉语言模型中,但一个持续存在的挑战是如何在保持对复杂结构化图像的强大泛化能力的同时,使专门的系统能够胜任特定的任务。
在此背景下,我们引入了 MOCR,用于解析文档中的任何内容,它能将表格,图标,UI 元素,图标以及特定领域图像转换为可重用的、可渲染的表示形式,而非栅格裁剪。MOCR 旨在将文档解析重新定义为一种可扩展的、可执行的监督信息来源,用于多模态预训练和检索,从而连接以文本为中心的解析器和特定任务的图形系统。表 1 和图 3 直观地展示了不同系统之间的比较。
3.Multimodal OCR
MOCR 的设计理念是将页面级解析任务统一到一个模型中,包括文档解析、网页和用户界面解析、场景文本解析以及结构化图形解析。这种统一性将文档和屏幕转化为更丰富的数据引擎,不仅能够恢复文本,还能恢复可重用、可渲染的视觉符号(例如SVG),这些代码可执行、可编辑且可组合,从而实现可扩展的预训练和检索,超越栅格裁剪的局限性。
3.1 Task Definition
MOCR 旨在对文档页面进行全面解析,包括 PDF 渲染图、数字扫描件、网页和场景文本图像。与将非文本元素视为静态栅格裁剪的传统文本中心流程不同,MOCR 将文本和视觉符号都视为一级解析目标。这种方法能够将信息密集型图形(例如图表、示意图、图标和示意图)显式地恢复为结构化的、可重用的表示,从而将静态像素转换为可用于下游推理和多模态训练的可操作数据。
给定输入图像 ,任务是生成带解析结果的有序序列 :
\textbf S=[(\mathcal B_1,c_1,p_1),...,(\mathcal B_K,c_K,p_K)].\tag{1}
其中,每个组成元素由以下部分定义:,空间区域或边界框;,语义类别或元素类型;,关联的 payload。序列 按照以人为中心的阅读顺序生成,使模型能够通过生成序列和专用分隔符隐式地编码结构层次和逻辑关系,而无需依赖外部关系模块。
Payload 是区域 内内容特定类型的序列化,由语义类型 决定。对于以文本为中心的区域(例如,文本行/块、表格和公式), 对应于它们以适当符号形式(例如纯文本、表格标记或 LaTeX)的转录。对于可以进行简洁程序化描述的视觉符号(例如 UI 组件、图标和图表), 是一种可渲染的结构化表示,即图像到 SVG 的转换。通过将符合条件的图形解析为 SVG 代码,MOCR 简化了“渲染和重用”的工作流程。值得注意的是,缺乏简洁程序化描述的复杂真实世界图像或自然照片将保留为栅格内容。这种策略性转变使得文档不仅能够提供文本 token,还能为下一代多模态预训练提供细粒度、可控的结构监督。
在当前版本中,MOCR 是任务条件式的,目前还无法一次性生成包含整页文档解析和视觉符号(例如 SVG)解析的输出。相反,我们通过分别运行页面级文本解析和区域级图像到 SVG 解码来获得完整的多模态解析结果。
3.2 Model Architecture
我们的方法架构遵循先前工作中确立的基本设计原则。它包含三个主要组件:高分辨率视觉编码器、轻量级多模态连接器和自回归语言模型(LLM)解码器。
High-Resolution Vision Encoder。视觉编码器是一个完全从零开始训练的 1.2B 参数骨干网络,确保编码器能够生成针对文档解析进行原生优化的特征表示,从而实现对密集文本和几何敏感的视觉符号(例如图表、示意图和原理图)的联合建模。在架构上,该编码器旨在接收高达约 1100 万像素的原生高分辨率输入。这种高吞吐量对于保留精细细节和保持整个页面上的远距离空间连贯性至关重要。这种分辨率不仅对于小字体文本或密集布局的可读性至关重要,而且对于精确感知图形基元(例如图表标记和示意图笔画)也至关重要——这些基元必须被精确定位才能恢复为结构化代码。
Structured Language Decoder。对于自回归解码器,我们使用 Qwen2.5-1.5B。关键在于统一 MOCR 解析的容量和成本权衡:远小于 1.5B 的模型通常难以在单个自回归解码过程中同时处理异构页面内容(文本、布局结构和视觉符号)并生成诸如 SVG 程序之类的长篇、高度结构化的输出,而规模更大的解码器则会增加训练和推理成本。从 base 模型(而非专门的 chat 模型)进行初始化,这为大规模预训练提供了一个中立的起点,模型必须学习非自然、结构化程度高的目标序列和远距离依赖关系,作为解析目标的一部分。
3.3 Training Recipe
我们的训练策略有意采用数据驱动的方式。鉴于 MOCR 的广泛覆盖范围,我们的目标不是引入特定任务的优化启发式方法,而是设计一个高效的课程,以降低学习难度,稳定多任务联合训练,并使单个模型能够吸收我们数据引擎产生的异构监督信息。
我们分三个阶段进行大规模预训练,每个阶段都有其独特的目标。第一阶段通过通用视觉训练建立稳定的视觉-语言接口,使语言模型能够可靠地处理视觉 token 并基于视觉输入进行生成。第二阶段在通用视觉数据和纯文本文档解析监督的统一混合数据集上进行广泛的预训练,在保持通用视觉鲁棒性的同时,构建强大的以文本为中心的解析基础。第三阶段通过降低通用视觉数据的比例并增加多模态文档解析的权重,将混合数据集转向MOCR特定目标,从而强化以OCR为中心的解析以及以图像到SVG形式实例化的视觉符号解析。在所有阶段中,我们都保持单一的自回归目标函数,预测基于输入图像和任务指令的结构化解析序列,并通过混合模型重加权和课程调度来控制优化稳定性。此外,我们还逐步提高各阶段的输入分辨率,以应对密集页面解析和长结构化生成日益增长的难度。
预训练之后,我们使用数据引擎构建的精心挑选的高质量监督数据集进行指令微调。与预训练相比,此阶段优先考虑监督的可靠性和任务可用性:我们筛选和优化样本以纠正系统性错误、统一输出规范并提高跨任务的端到端解析保真度。对于视觉符号解析,指令调优对目标一致性尤为敏感,因此 SVG 特有的处理(例如规范化、viewBox 归一化和复杂度降低)作为数据引擎的一部分,而训练方案则侧重于将这些优化后的信号整合到一个稳定的多任务 SFT 混合模型中。我们发布了两个具有相同预训练的检查点:dots.mocr 和 dots.mocr-svg,其中后者增加了 SVG 的比例,并在 SFT 期间提高了难度更高的 SVG 程序的权重,以便在相同的参数预算下更好地优先处理图像到 SVG 的解析。
3.4 Data Engine
为 MOCR 训练单个模型对训练语料库提出了异常严格的要求。除了要能适应不同的脚本、布局和长距离阅读结构之外,模型还必须学会将视觉符号(例如图表、示意图、图标和示意图)解析成可重用的结构化表示,而不是将其作为栅格图像保留下来。目前尚无任何数据集能够以足够的规模和质量提供这种覆盖范围。
我们的训练语料库由四个互补的来源构建而成:(i) 用于文本语言页面解析的 PDF 文档;(ii) 经过图像处理并带有对齐结构信号的网页;(iii) 用于图像到 SVG 监督的原生 SVG 资源;以及 (iv) 用于保持广泛鲁棒性和下游可用性的通用数据。我们在预训练阶段应用轻量级质量控制,以去除明显的噪声并保持多样性,并精心挑选出一个更小、更高精度的子集,用于指令微调,同时采用更严格的验证和规范对齐方法。
PDF documents。我们使用 dots.ocr 作为自动标注引擎,从原始 PDF 构建多语言文档解析监督模型,生成包含布局区域和阅读顺序的结构化页面转录。我们通过分层抽样,根据语言、领域和布局复杂度(通过块数、文本密度以及表格/公式的存在等轻量级代理指标进行估计)来筛选 PDF 样本库,以突出难解区域。为了优化指令,我们通过以下方式进一步提高可靠性:(i)使用基于规则的健全性检查和基于渲染的与输入页面的比较进行验证;(ii)通过更严格的监督重新标注或筛选样本,以纠正常见错误。
Webpages。我们抓取网页并将其渲染成页面图像,然后将其转换为与 PDF 相同的 MOCR 解析格式。这种数据源扩展了分发范围,提供了高分辨率且布局复杂的图像,提供了来自 HTML/DOM 的对齐结构信号以减少标签噪声,并提供了丰富的 SVG 原生图标、图表和示意图,进一步支持视觉符号解析。
SVG graphics。MOCR 的核心目标是将符合条件的图形解析为可重用、可渲染的表示形式,而不是将其保留为栅格裁剪图像。由于网络上的许多图标、图表和 UI 图形都以 SVG 格式原生存储,我们从各种来源收集此类资源,并对其进行渲染以构建图像-SVG 对。我们的流程包含两个阶段:清洗和采样。在清洗阶段,我们使用 svgo 去除无关的元数据、规范化数值精度并标准化代码结构,然后使用文本匹配和感知哈希(pHash)对渲染后的图像进行代码和图像层面的去重。在采样阶段,我们执行领域层面的平衡,以避免单个来源的过度表示,并应用基于 SVG 程序复杂度的复杂度感知采样,以保持简单和复杂图形的平衡组合。
General-purpose data。此外,我们还加入了通用视觉和 OCR 监督任务(例如,定位和计数),以在页面级解析的同时保持广泛的功能。
该数据引擎支持对文本解析和视觉符号解析进行统一训练,将以前仅包含栅格图像的图形转换为可重用的 MOCR 程序监督。